python之二进制
二进制表示
- 十进制与二进制
- 十进制与八进制
- 字符的二进制表示
- 中文与二进制
- py2 与 py3的编码
- hash哈希
- python中基于hash的数据类型
十进制与二进制
十进制—>二进制,除2取余倒排列
如十进制的5,表示为二进制101
python实现:
d = 5
bin(5)
#"0b101"
#将当前二进制数据,转为整型
int("0b101",base=2) # 5
小数部分,则乘2取整正排列
如十进制的0.5,表示为二进制0.1
二进制---->十进制,只需加权求和
如二进制101,其十进制表示为1*22+0*21+1*20=5
十进制与八进制
十进制---->八进制,除8取余倒排列
如十进制的8 ,表示为八进制为0o10
d = 8
oct(d)
#0o10
int("0o10",base=8)
八进制—>十进制,同样加权求和
十进制---->十六进制,same
d = 17
hex(d)
#'0x11'
int("0x11",base=16) #十六进制转十进制,加权求和
#1*16^1 + 1*16^0
字符的二进制表示
字符有对应的ASCII码表,将对应的十进制数,转为二进制
#获取英文字符的二进制
bin(ord("a"))
#'0b1100001',一字节
chr
1byte = 8bit
1Kb = 1024bytes
1Mb = 1024Kb
…
中文与二进制
中文字符有对应的GBK/GB2312/GB18030编码表,对应的十进制,转为二进制。

一个中文字符占两个字节,现在主流为GBK编码。
通用编码方式Unicode,将所有的字符与二进制对应起来,但是每个字符占用两个字节的内存,比ASCII编码多一倍,临时存储在内存中还可以,存入磁盘或者网络传输就很浪费空间。
所以产生了一个utf-8的编码,Unicode Transform Format,节省磁盘、传输时的空间。
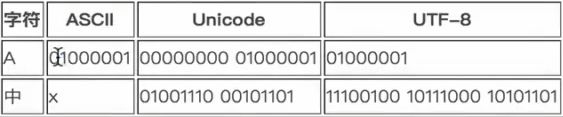
内存中的数据–>Unicode编码----2bytes/per char
磁盘中的数据–>UTF-8----1byte for english, 3bytes for chinese
linux命令行下输入locale,查看支持的编码格式
py2 与 py3的编码
py2 内存中为ASCII编码,使用中文需声明
linux/macOS系统中使用utf-8
#!/usr/bin/python2
# -*- coding:utf-8 -*-
print("中文")
windows系统使用gbk编码
py3 内存中为Unicode编码
hash哈希
将不同的输入,哈希计算得出固定长度的输出。
特性:
不可逆
计算速度快,即使文件很大,也不会太影响计算速度
输入的数据类型,必须不可变
用途:
密码加密
文件校验
hash("xxxxx")
from hashlib import md5
m = md5()
m.update("xxx".encode())
m.hexdigest()
python中基于hash的数据类型
dict/set
为什么字典查询速度快?
在字典里,每个key都要经过hash计算,对所有的key的hash值进行排序。
在查找某个key的值时,首先计算其hash值,根据其hash值找到对应的value,时间复杂度O(1)。
根据查询到的hash值,得到对应value的索引。
为什么set自动去重?
存入值时,计算其hash值,然后在对应位置存入数据,若该位置没有数据,则插入;否则不插入。
上一篇:python基础之常用操作
下一篇:python文件操纵