分布式定时任务调度实战
目录
1、为什么需要定时任务
2、定时任务调度框架
2.1 单机
2.2 分布
3、xxl-job和elastic-job对比
3.1 支持集群部署方式
3.2 多节点部署任务执行方式
3.3 日志可追溯
3.4 监控告警
3.5 弹性扩容缩容
3.6 支持并行调度
3.7 高可用策略
3.8 失败处理策略
3.9 动态分片策略
3.10 总结和结论
4、xxl-job实践
4.1 下载源码
4.2 执行数据库脚本
4.3 配置调度中心文件
4.4 部署调度中心
4.5 创建执行器项目
4.6 配置执行器
4.7 配置job任务
4.8 启动执行器项目和job任务测试
4.9 执行器集群模式测试
4.10 分片广播路由模式
5、Elastic-job实践
5.1 简单入门
5.2 实现数据流式处理
5.3 Console控制台
5.4 zookeeper集群控制
5.5 分片策略
5.6 作业监听
5.7 数据源追踪调度历史
1、为什么需要定时任务
我们先思考下面几个业务场景的解决方案:
-
支付系统每天凌晨1点跑批,进行一天清算,每月1号进行上个月清算
-
电商整点抢购,商品价格8点整开始优惠
-
12306购票系统,超过30分钟没有成功支付订单的,进行回收处理
-
商品成功发货后,需要向客户发送短信提醒
类似的业务场景非常多,我们怎么解决?
很多业务场景需要我们某一特定的时刻去做某件任务,定时任务解决的就是这种业务场景。一般来说,系统可以使用消息传递代替部分定时任务,两者有很多相似之处,可以相互替换场景。如,上面发货成功发短信通知客户的业务场景,我们可以在发货成功后发送MQ消息到队列,然后去消费mq消息,发送短信。 但在某些场景下不能互换:
a)时间驱动/事件驱动:内部系统一般可以通过事件来驱动,但涉及到外部系统,则只能使用时间驱动。如爬取外部网站价格,每小时爬一次
b)批量处理/逐条处理:批量处理堆积的数据更加高效,在不需要实时性的情况下比消息中间件更有优势。而且有的业务逻辑只能批量处理。如移动每个月结算我们的话费
c)实时性/非实时性:消息中间件能够做到实时处理数据,但是有些情况下并不需要实时,比如:vip升级
d)系统内部/系统解耦:定时任务调度一般是在系统内部,而消息中间件可用于两个系统间
2、定时任务调度框架
2.1 单机
-
timer:是一个定时器类,通过该类可以为指定的定时任务进行配置。TimerTask类是一个定时任务类,该类实现了Runnable接口,缺点异常未检查会中止线程
-
ScheduledExecutorService:相对延迟或者周期作为定时任务调度,缺点没有绝对的日期或者时间
-
spring定时框架:配置简单功能较多,如果系统使用单机的话可以优先考虑spring定时器
2.2 分布
-
Quartz:Java事实上的定时任务标准。但Quartz关注点在于定时任务而非数据,并无一套根据数据处理而定制化的流程。虽然Quartz可以基于数据库实现作业的高可用,但缺少分布式并行调度的功能
-
TBSchedule:阿里早期开源的分布式任务调度系统。代码略陈旧,使用timer而非线程池执行任务调度。众所周知,timer在处理异常状况时是有缺陷的。而且TBSchedule作业类型较为单一,只能是获取/处理数据一种模式。还有就是文档缺失比较严重
-
Saturn:是唯品会自主研发的分布式的定时任务的调度平台,基于当当的elastic-job 版本1开发,并且可以很好的部署到docker容器上。
-
xxl-job: 是大众点评员工徐雪里于2015年发布的分布式任务调度平台,是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
-
elastic-job:当当开发的弹性分布式任务调度系统,功能丰富强大,采用zookeeper实现分布式协调,实现任务高可用以及分片,目前是版本2.15,并且可以支持云开发
我们本课程讲解当下最流行的xxl-job和elastic-job
3、xxl-job和elastic-job对比
PS:看不懂的先看下面的实践操作再回过头来看
3.1 支持集群部署方式
X-Job:集群部署唯一要求为:保证每个集群节点配置(db和登陆账号等)保持一致。调度中心通过db配置区分不同集群。
执行器支持集群部署,提升调度系统可用性,同时提升任务处理能力。集群部署唯一要求为:保证集群中每个执行器的配置项 “xxl.job.admin.addresses/调度中心地址” 保持一致,执行器根据该配置进行执行器自动注册等操作。
E-Job:重写Quartz基于数据库的分布式功能,改用Zookeeper实现注册中心
作业注册中心: 基于Zookeeper和其客户端Curator实现的全局作业注册控制中心。用于注册,控制和协调分布式作业执行。
3.2 多节点部署任务执行方式
X-Job:使用Quartz基于数据库的分布式功能 E-Job:将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job将在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。
3.3 日志可追溯
X-Job:支持,有日志查询界面 E-Job:可通过事件订阅的方式处理调度过程的重要事件,用于查询、统计和监控。Elastic-Job目前提供了基于关系型数据库两种事件订阅方式记录事件。
3.4 监控告警
X-Job:调度失败时,将会触发失败报警,如发送报警邮件。
任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔
E-Job:通过事件订阅方式可自行实现
作业运行状态监控、监听作业服务器存活、监听近期数据处理成功、数据流类型作业(可通过监听近期数据处理成功数判断作业流量是否正常,如果小于作业正常处理的阀值,可选择报警。)、监听近期数据处理失败(可通过监听近期数据处理失败数判断作业处理结果,如果大于0,可选择报警。)
3.5 弹性扩容缩容
X-Job:使用Quartz基于数据库的分布式功能,服务器超出一定数量会给数据库造成一定的压力 E-Job:通过zk实现各服务的注册、控制及协调
3.6 支持并行调度
X-Job:调度系统多线程(默认10个线程)触发调度运行,确保调度精确执行,不被堵塞。 E-Job:采用任务分片方式实现。将一个任务拆分为n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。
3.7 高可用策略
X-Job:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行; E-Job:调度器的高可用是通过运行几个指向同一个ZooKeeper集群的Elastic-Job-Cloud-Scheduler实例来实现的。ZooKeeper用于在当前主Elastic-Job-Cloud-Scheduler实例失败的情况下执行领导者选举。通过至少两个调度器实例来构成集群,集群中只有一个调度器实例提供服务,其他实例处于”待命”状态。当该实例失败时,集群会选举剩余实例中的一个来继续提供服务。
3.8 失败处理策略
X-Job:调度失败时的处理策略,策略包括:失败告警(默认)、失败重试; E-Job:弹性扩容缩容在下次作业运行前重分片,但本次作业执行的过程中,下线的服务器所分配的作业将不会重新被分配。失效转移功能可以在本次作业运行中用空闲服务器抓取孤儿作业分片执行。同样失效转移功能也会牺牲部分性能。
3.9 动态分片策略
X-Job:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时传递分片参数;可根据分片参数开发分片任务;
E-Job:支持多种分片策略,可自定义分片策略
默认包含三种分片策略: 基于平均分配算法的分片策略、 作业名的哈希值奇偶数决定IP升降序算法的分片策略、根据作业名的哈希值对Job实例列表进行轮转的分片策略,支持自定义分片策略
elastic-job的分片是通过zookeeper来实现的。分片的分片由主节点分配,如下三种情况都会触发主节点上的分片算法执行: a、新的Job实例加入集群 b、现有的Job实例下线(如果下线的是leader节点,那么先选举然后触发分片算法的执行) c、主节点选举”
3.10 总结和结论
共同点: E-Job和X-job都有广泛的用户基础和完整的技术文档,都能满足定时任务的基本功能需求。 不同点: X-Job 侧重的业务实现的简单和管理的方便,学习成本简单,失败策略和路由策略丰富。推荐使用在“用户基数相对少,服务器数量在一定范围内”的情景下使用 E-Job 关注的是数据,增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源。但是学习成本相对高些,推荐在“数据量庞大,且部署服务器数量较多”时使用
4、xxl-job实践
4.1 下载源码
①、GitHub:https://github.com/xuxueli/xxl-job
②、码云:xxl-job: 一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
解压后导入IDEA:

4.2 执行数据库脚本
因为xxl-job使用Quartz基于数据库开发的,所以需要先初始化数据库脚本:
注意:因为我们的数据库默认情况下,InnoDB 引擎单一字段索引的长度最大为 767 字节,而脚本中创建表“xxl_job_registry”使用的联合索引已经超过了这个长度,所以需要先配置MySQL的my.cnf文件,将索引约束性扩展到最大(3072字节):
[mysqld]
innodb_large_prefix = ON
innodb_file_format = BARRACUDA
#重启MySQL服务同时将源码中的SQL脚本增加行记录格式为动态:
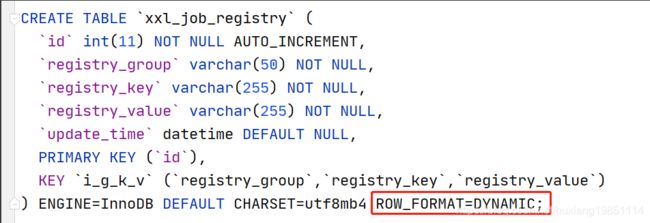
执行完后可以看到如下表结构(不同的xxl-job版本表结构不一样!):
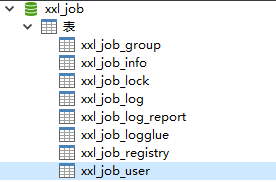
4.3 配置调度中心文件
调度中心就是源码中的 xxl-job-admin 工程,我们需要将其配置成自己需要的调度中心,通过该工程我们能够以图形化的方式在统一管理任务调度平台上调度任务,负责触发调度执行。
我们主要修改application.properties配置文件两个地方:
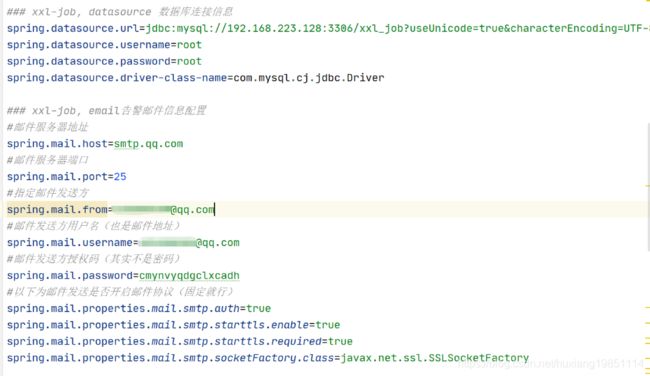
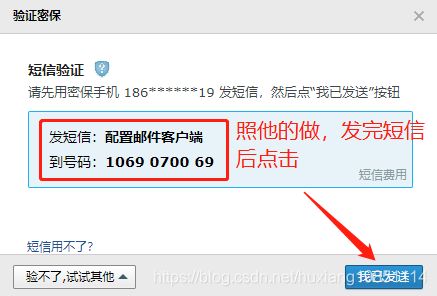
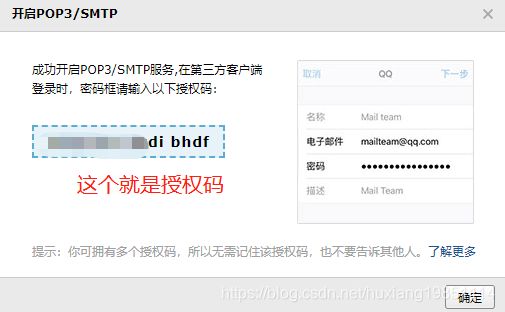
其中邮件发送方授权码,我们以QQ邮件服务器为例,其他的自行百度:
1)、
2)、
3)、
4)、
5)、
4.4 部署调度中心
该工程是一个springboot项目,我们只需要在IDEA中执行 XxlJobAdminApplication 类即可运行该工程
访问:http://localhost:8080/xxl-job-admin,可以看到任务调度中心面板了

4.5 创建执行器项目
其实在源码中,作者提供了各个版本的 执行器项目,作者推荐的也是springboot版本的执行器项目
我们大概看下其中的配置,以后我们要自定义执行器,把该项目拷贝或者就在这个项目上改都行:
1)、引入依赖坐标

2)、执行器spring配置
3)、Spring配置类XxlJobConfig,初始化执行器实例到Spring容器
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}4)、Job处理器类实例化:SampleXxlJob

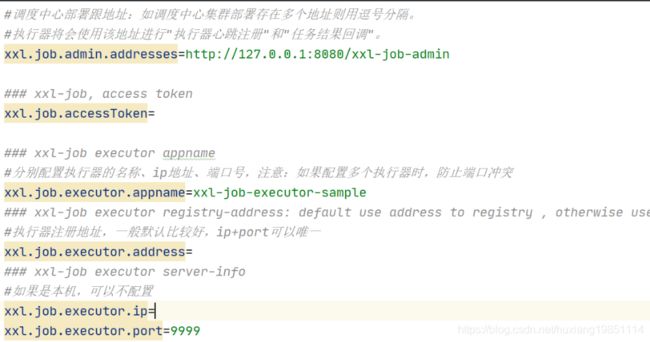
4.6 配置执行器
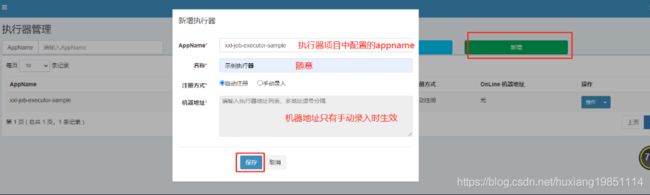
4.7 配置job任务

4.8 启动执行器项目和job任务测试
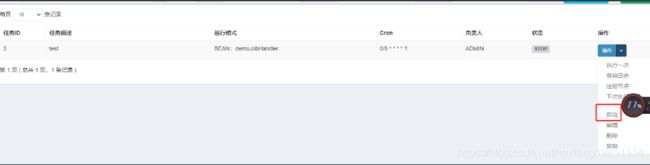
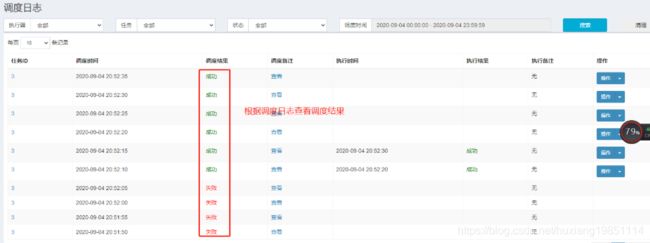
报错时可以收到告警邮件:
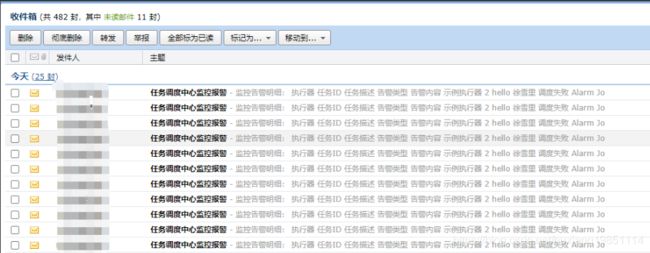
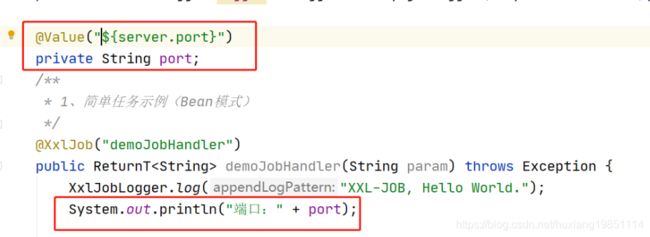
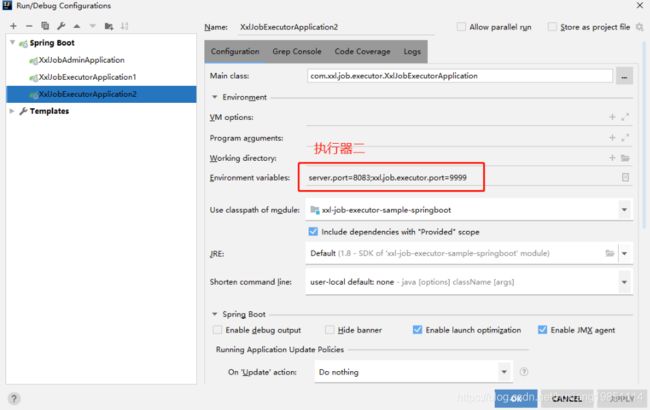
4.9 执行器集群模式测试
1)、通过打印不同端口来测试执行器集群的路由模式
2)、修改启动参数

3)、手动录入执行器地址

4)、选择任务调度路由模式,这里我们选择轮询模式**
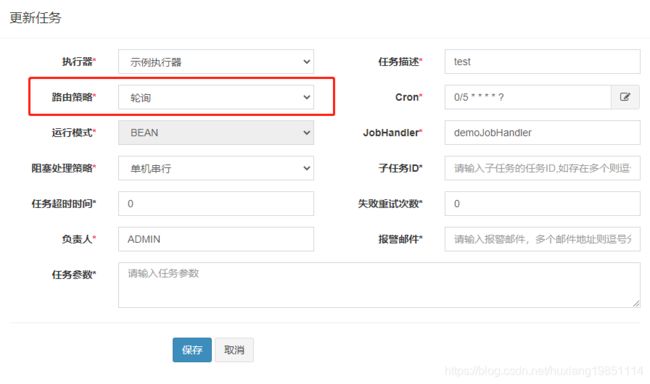
从控制台可以观察打印的端口信息是否符合轮询!当然,你也可以选择其他模式进行测试,非常简单
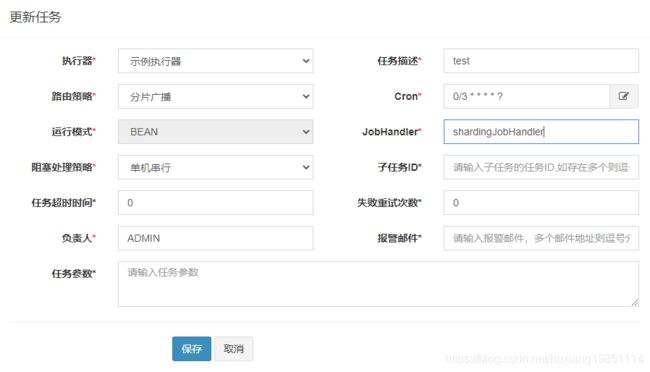
4.10 分片广播路由模式

除了分片广播,其他的路由策略都很容易看出来策略的实现方式。
分片广播策略下,有两个很重要的数据分片总数和当前分片数
分片总数:任务集群中任务服务的数量
当前分片数:当前的下标,同一片任务机器中,这个数字都不一样。
我们使用作者提供的demo测试:

调度中心配置:
控制台打印:

显然调度中心每次调度任务都会响应到所有的定时任务上,只是不同的服务命中的分片不一样。分片的值是调度中心分配的。所以你可以利用这种机制同时执行所有集群节点都需要执行的任务
5、Elastic-job实践
Elastic Job官网:http://elasticjob.io/index_zh.html
5.1 简单入门
我们这里还是以Spring Boot作为项目基本骨架讲解,官方推荐的也是Spring Boot,并且也提供了多种示例demo:

官方示例demo下载地址:https://github.com/apache/shardingsphere-elasticjob/tree/master/examples
5.1.1 引入elastic-job核心依赖包
com.dangdang
elastic-job-lite-core
com.dangdang
elastic-job-lite-spring
org.springframework.boot
spring-boot-starter-web
${springboot.version}
5.1.2 定义定时任务job类
package com.ydt.sprinbootelasticjobliteexample.job;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import org.springframework.stereotype.Component;
/**
* 定时任务job类,实现SimpleJob(简单任务)接口
*/
@Component
public class SpringSimpleJob implements SimpleJob {
public void execute(final ShardingContext shardingContext) {
System.out.println("执行简单定时任务示例:" + shardingContext.toString());
}
}
5.1.3 定义ZK注册中心配置类
package com.ydt.sprinbootelasticjobliteexample.config;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnExpression;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Zookeeper注册中心配置类,只有配置了注册中心服务列表时,该类才会被实例化
*/
@Configuration
@ConditionalOnExpression("'${regCenter.serverList}'.length() > 0")
public class RegistryCenterConfig {
//注册中心服务列表
@Value("${regCenter.serverList}")
private String serverList;
//注册中心节点命名空间,为null时会直接在zookeeper根目录下创建
@Value("${regCenter.namespace}")
private String namespace;
//初始化Bean后执行ZookeeperRegistryCenter类init方法,启动zookeeper客户端
@Bean(initMethod = "init")
public ZookeeperRegistryCenter regCenter() {
return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList, namespace));
}
}
5.1.4 定义简单任务配置类
package com.ydt.sprinbootelasticjobliteexample.config;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.lite.spring.api.SpringJobScheduler;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
public class SimpleJobConfig {
//zookeeper注册中心对象
@Resource
private ZookeeperRegistryCenter regCenter;
//定时任务job类
@Autowired
private SpringSimpleJob simpleJob;
//定时任务cron表达式
@Value("${simpleJob.cron}")
private String cron;
//分片总数:定时任务被划分的执行体数
@Value("${simpleJob.shardingTotalCount}")
private int shardingTotalCount;
//定时任务参数
@Value("${simpleJob.shardingItemParameters}")
private String shardingItemParameters;
@Bean
public SimpleJob simpleJob() {
return new SpringSimpleJob();
}
//实例化Bean后执行JobScheduler类init方法,执行任务调度
@Bean(initMethod = "init")
public JobScheduler simpleJobScheduler() {
return new SpringJobScheduler(simpleJob, regCenter,
getLiteJobConfiguration());
}
//获取定时任务配置对象,包括表达式,分片数,分片任务参数
private LiteJobConfiguration getLiteJobConfiguration() {
return LiteJobConfiguration.newBuilder(
new SimpleJobConfiguration(
JobCoreConfiguration.newBuilder(
simpleJob.getClass().getName(),
cron,
shardingTotalCount
).shardingItemParameters(shardingItemParameters)
.build(),
simpleJob.getClass().getCanonicalName()
)
).overwrite(true).build();
}
}
5.1.5 配置spring文件
regCenter:
serverList: ydt1:2181
namespace: elastic-job-lite-springboot
simpleJob:
cron: 0/5 * * * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou5.1.6 启动Application测试
执行简单定时任务示例:ShardingContext(jobName=com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob, taskId=com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob@-@0,1,2@-@READY@[email protected]@-@17856, shardingTotalCount=3, jobParameter=, shardingItem=0, shardingParameter=Beijing)
执行简单定时任务示例:ShardingContext(jobName=com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob, taskId=com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob@-@0,1,2@-@READY@[email protected]@-@17856, shardingTotalCount=3, jobParameter=, shardingItem=1, shardingParameter=Shanghai)
执行简单定时任务示例:ShardingContext(jobName=com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob, taskId=com.ydt.sprinbootelasticjobliteexample.job.SpringSimpleJob@-@0,1,2@-@READY@[email protected]@-@17856, shardingTotalCount=3, jobParameter=, shardingItem=2, shardingParameter=Guangzhou)ok,可以看到三个分片任务已经都执行了,恭喜你,入门了!
5.2 实现数据流式处理
5.2.1 概念解析
流式作业,每次调度触发的时候都会先调fetchData获取数据,如果获取到了数据再调度processData方法处理数据。
流式任务类型:业务实现两个接口:抓取(fetchData)和处理(processData)数据,DataflowJob在运行时有两种方式,流式的和非流式的,通过属性streamingProcess控制
a.流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则本次作业将一直运行下去;
b.非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业;
模拟一个场景需求:从数据库中分页查询数据然后进行显示处理,一直到数据库中没有数据为止!
5.2.2 模拟数据库数据
POJO
package com.ydt.sprinbootelasticjobliteexample.pojo;
public class User {
private int id ;
private String name ;
private String sex;
private long length;
public User(int id, String name, String sex, long length) {
this.id = id;
this.name = name;
this.sex = sex;
this.length = length;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public long getLength() {
return length;
}
public void setLength(long length) {
this.length = length;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
", length=" + length +
'}';
}
}模拟数据工具类
package com.ydt.sprinbootelasticjobliteexample.utils;
import com.ydt.sprinbootelasticjobliteexample.pojo.User;
import java.util.ArrayList;
import java.util.List;
public class DataFlowUtil {
public static List datas = new ArrayList<>();
/**
* 模拟数据库数据
*/
static {
for (int i = 0; i < 300; i++) {
int j = i%4;
switch (j){
case 0: {
datas.add(new User(i , "老胡" + i , "男性", i));
break;
}
case 1:{
datas.add(new User(i , "老胡" + i , "男孩", i));
break;
}case 2:{
datas.add(new User(i , "老胡" + i , "男人", i));
break;
}
default:{
datas.add(new User(i , "老胡" + i , "男神", i));
break;
}
}
}
}
}
5.2.3 定义流式作业Job任务类
package com.ydt.sprinbootelasticjobliteexample.job;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import com.ydt.sprinbootelasticjobliteexample.pojo.User;
import com.ydt.sprinbootelasticjobliteexample.utils.DataFlowUtil;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* 流式作业Job任务类,需要实现DataflowJob接口数据抓取和处理接口方法
*/
@Component
public class SpringDataflowJob implements DataflowJob {
/**
* 模拟每次从数据库抓取10条数据,因为流式处理是多线程并行模式进行数据获取,所以需要加上synchronized
* @param shardingContext
* @return
*/
public synchronized List fetchData(ShardingContext shardingContext) {
List users = new ArrayList<>();
Iterator iterator = DataFlowUtil.datas.iterator();
while(iterator.hasNext()) {
User user = iterator.next();
if(users.size() <= 10){
if(StringUtils.equals(shardingContext.getShardingParameter(),user.getSex())){
users.add(user);
iterator.remove();
}
}
}
System.out.println("当前数据库还剩"+DataFlowUtil.datas.size()+"条数据没有抓取");
return users;
}
/**
* 模拟处理数据
* @param shardingContext
* @param list
*/
public void processData(ShardingContext shardingContext, List list) {
System.out.println("本次抓取的数据已经给您送来了:" + list);
}
}
5.2.4 定义流式作业配置类
package com.ydt.sprinbootelasticjobliteexample.config;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.dataflow.DataflowJobConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.lite.spring.api.SpringJobScheduler;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import com.ydt.sprinbootelasticjobliteexample.job.SpringDataflowJob;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
public class DataFlowJobConfig {
//zookeeper注册中心对象
@Resource
private ZookeeperRegistryCenter regCenter;
//定时任务job类
@Autowired
private SpringDataflowJob dataflowJob;
//定时任务cron表达式
@Value("${dataflowJob.cron}")
private String cron;
//分片总数:定时任务被划分的执行体数
@Value("${dataflowJob.shardingTotalCount}")
private int shardingTotalCount;
//定时任务参数
@Value("${dataflowJob.shardingItemParameters}")
private String shardingItemParameters;
//实例化Bean后执行JobScheduler类init方法,执行任务调度
@Bean(initMethod = "init")
public JobScheduler dataflowJobScheduler() {
return new SpringJobScheduler(dataflowJob, regCenter,
getLiteJobConfiguration());
}
//获取定时任务配置对象,包括表达式,分片数,分片任务参数,是否流式作业
private LiteJobConfiguration getLiteJobConfiguration() {
return LiteJobConfiguration.newBuilder(
new DataflowJobConfiguration(
JobCoreConfiguration.newBuilder(
dataflowJob.getClass().getName(),
cron,
shardingTotalCount
).shardingItemParameters(shardingItemParameters).build(),
dataflowJob.getClass().getCanonicalName(),
true
)
).overwrite(true).build();
}
}
5.2.5 配置spring文件
#增加如下配置
dataflowJob:
cron: 0/5 * * * * ?
shardingTotalCount: 4
shardingItemParameters: 0=男性,1=男孩,2=男人,3=男神5.2.6 启动测试

5.3 Console控制台
5.3.1 下载源码包
下载地址:https://github.com/apache/shardingsphere-elasticjob
解压后,进入根目录

在该目录打开cmd窗口,输入:mvn clean install -Dmaven.test.skip=true 打包
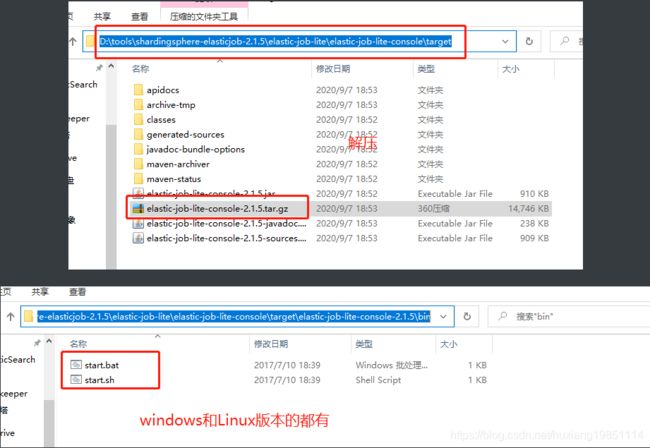

5.3.2 启动访问
访问地址:http://127.0.0.1:8899/
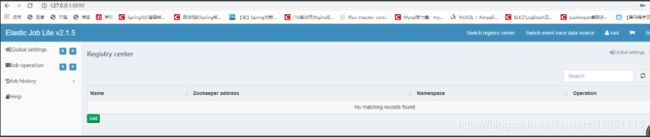
配置注册中心

比如点击停止后,定时任务控制台会打印:

当然你还可以修改cron表达式,失效等操作!
5.4 zookeeper集群控制
5.4.1 zookeeper集群部署
略,详情请移步zookeeper课件查看
5.4.2 配置注册中心集群
regCenter:
serverList: ydt1:2181,ydt2:2181,ydt3:2181
namespace: elastic-job-lite-springboot5.4.3 测试
当们断开其中leader节点,会出现网络抖动并且重连新的leader,这个期间定时任务是不可用的,一旦服务可用,则可以将之前错过的任务重复执行:
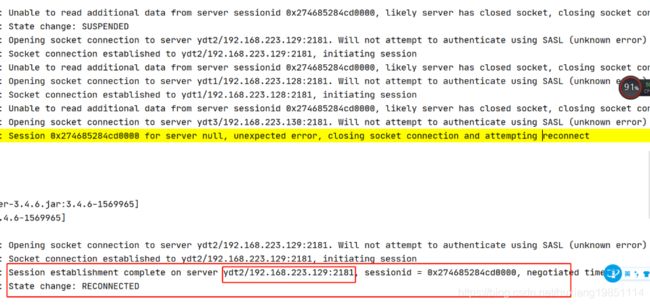
当再关闭一台zookeeper服务时,集群已经不可用,job项目会不停的报错!
当zookeeper再次启动一台服务,进行集群选举后,定时任务又可以用了,达到了注册中心的高可用目的
5.5 分片策略
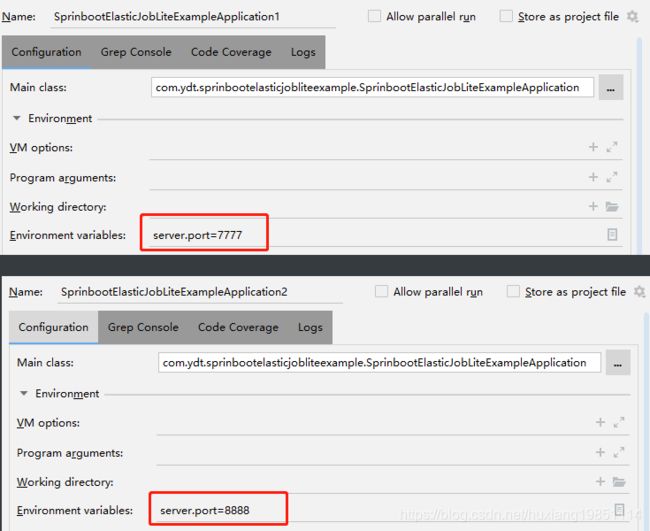
启动三个作业服务测试(不同端口),打印一下端口来标志作业服务调用:

5.5.1 平均分配
分片策略类:AverageAllocationJobShardingStrategy
基于平均分配算法的分片策略,也是默认的分片策略,作业数能被服务器数整除情况下均匀分配
如果分片不能整除,则不能整除的多余分片将依次追加到序号小(ip地址靠前)的服务器(本机多余的追加到端口号小的服务器)。
缺点:平均分片策略,当分片数小于作业服务器数时,作业会被永远分配在ip地址靠前的服务器,而导致IP地址靠后的服务器空闲。当分片数为8时,两台服务器打印信息分别如下:

当分片数为9时,打印信息如下:
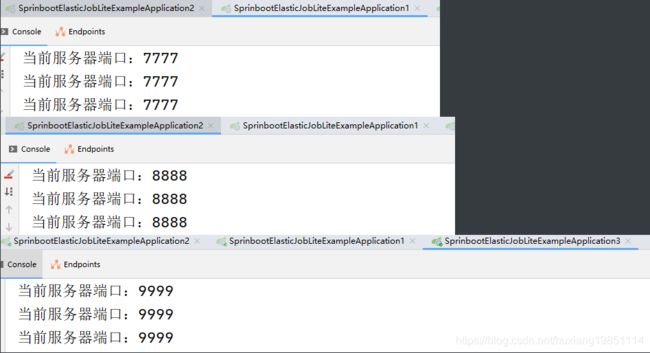
5.5.2 作业名哈希值奇偶数算法
分片策略类:OdevitySortByNameJobShardingStrategy
* 作业名的哈希值为奇数则IP升序.
* 作业名的哈希值为偶数则IP降序.
* 用于不同的作业平均分配负载至不同的服务器.
* 如:
* 1. 如果有3台服务器, 分成2片, 作业名称的哈希值为奇数, 则每台服务器分到的分片是: 1=[0], 2=[1], 3=[].
* 2. 如果有3台服务器, 分成2片, 作业名称的哈希值为偶数, 则每台服务器分到的分片是: 3=[0], 2=[1], 1=[].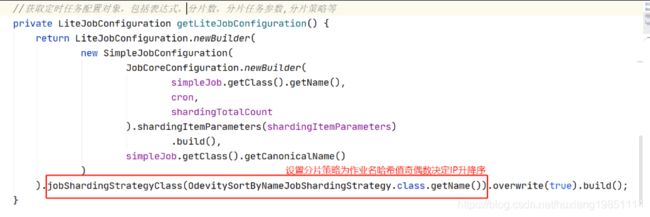
源码也非常简单

5.5.3 作业名哈希值轮转分片算法
分片策略类:RotateServerByNameJobShardingStrategy
根据作业名的哈希值对服务器列表进行轮转的分片策略,其内部也是采用平均分片算法。
在执行AverageAllocationJobShardingStrategy的分片之前,根据任务的哈希值与节点数量取模,将之前取模的结果依次加一的结果与节点数量重新取模对节点进行重新排序,再执行AverageAllocationJobShardingStrategy的分片。
源码解析:

5.6 作业监听
其实就相当于Spring里面前置后置处理器
//实例化Bean后执行JobScheduler类init方法,执行任务调度
@Bean(initMethod = "init")
public JobScheduler simpleJobScheduler() {
return new SpringJobScheduler(simpleJob, regCenter,
getLiteJobConfiguration(), new ElasticJobListener() {
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
System.out.println("作业前监听");
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
System.out.println("作业后监听");
}
});
}
5.7 数据源追踪调度历史
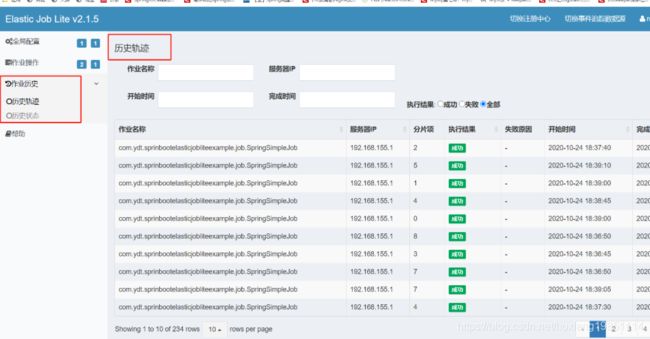
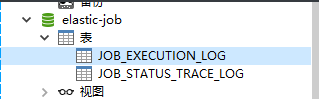
Elastic-Job提供了事件追踪功能,用于查询、统计和监控作业执行历史和执行状态。Elastic-Job-Lite在配置中提供了JobEventConfiguration,目前支持数据库方式配置。事件追踪所配置的DataSource数据库中会自动创建JOB_EXECUTION_LOG和JOB_STATUS_TRACE_LOG两张表以及若干索引
Elastic-Job目前使用的是注册式任务记录日志,所以需要初始化一个数据源以及数据源事件配置,我们使用druid:
5.7.1 添加pom依赖
com.alibaba
druid
1.1.22
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
5.7.2 初始化数据源实例
package com.ydt.sprinbootelasticjobliteexample.utils;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DataSourceProperties {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource getDataSource() {
return new DruidDataSource();
}
}
5.7.3 任务调度事件数据源配置
package com.ydt.sprinbootelasticjobliteexample.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.dangdang.ddframe.job.event.JobEventConfiguration;
import com.dangdang.ddframe.job.event.rdb.JobEventRdbConfiguration;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.annotation.Order;
@Configuration
@Order(1)
public class JobEventConfig {
@Autowired
private DruidDataSource dataSource;
@Bean
public JobEventConfiguration jobEventConfiguration() {
return new JobEventRdbConfiguration(dataSource);
}
}
5.7.4 在需要任务日志的job配置订阅

5.7.5 测试
启动服务后,第一次订阅时会在对应的数据库创建两个表:
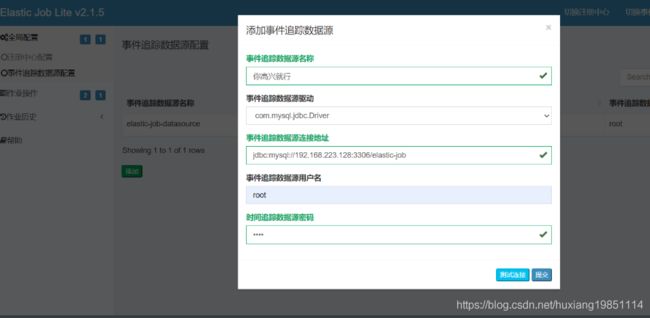
在控制台配置事件跟踪数据源:
现在你可以看到历史轨迹和历史状态了: