amoeba安装与实现amoeba for mysql读写分离
原创文章,请尊重作者辛勤劳动。
运行环境
l CentOS6.3
l Jdk1.6.0_30
l amoeba-mysql-binary-2.2.0
l amoeba:192.168.88.17
l master1:192.168.88.10
l slave1:192.168.88.11
一: 安装jdk1.5以上版本
1.1 卸载centos服务器自带版本jdk
1.1.1 查看服务器自带jdk版本号
[root@amoeba1 ~]# java –version

1.1.2 查看java信息
[root@amoeba1 ~]# rpm -qa | grep java

1.1.3 卸载java文件
[root@amoeba1 ~]# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.x86_64
1.1.4 再次查看java版本,已经删除
[root@amoeba1 ~]# java –version
![]()
1.2 安装jdk
1.2.1 创建/usr/java文件夹,将jdk安装文件拷贝到此目录
[root@amoeba1 ~]# mkdir /usr/java
[root@amoeba1 ~]# cd /usr/java
1.2.2 赋予权限
[root@amoeba1 java]# chmod 777 jdk-6u30-linux-x64-rpm.bin
1.2.3 安装jdk
[root@amoeba1 java]# ./jdk-6u30-linux-x64-rpm.bin
1.2.4 配置环境变量
[root@amoeba1 java]# vi /etc/profile
在配置文件最后面添加下面3条语句
export JAVA_HOME=/usr/java/jdk1.6.0_30
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin

1.2.5 配置完成后,重启服务器
[root@amoeba1 java]# reboot
1.3 重启完成后查看新安装jdk版本
[root@amoeba1 ~]# java –version

二: 安装amoeba
2.1下载amoeba,http://sourceforge.net/projects/amoeba/files/,我用的版本是amoeba-mysql-binary-2.2.0.tar
2.2 创建amoeba文件夹,将文件解压到此文件夹
[root@amoeba1 ~]# mkdir /usr/local/amoeba
[root@amoeba1 ~]# cd /usr/local/amoeba/
[root@amoeba1 amoeba]# tar -zxvf amoeba-mysql-binary-2.2.0.tar.gz
2.3 验证是否安装成功
[root@amoeba1 amoeba]# /usr/local/amoeba/bin/amoeba start
三:参数配置
[root@amoeba1 amoeba]# cd /usr/local/amoeba/conf/
[root@amoeba1 conf]# ls
![]()
l Amoeba.xml:主配置文件,配置数据源和amoeba的自身参数
l dbServer.xml:需要至少配置一个dbServer,每个dbServer将是物理数据库Server的衍射
l log4j.xml:日志文件
l rule.xml:配置所有Query路由规则的信息
l functionMap.xml:配置用于解析Query中的函数所对应的Java实现类
l rullFunctionMap.xml:配置路由规则中需要使用到的特定函数的实现类
这里我们通过修改amoeba.xml和dbServer.xml来实现读写分离,修改log4j.xml来节约服务器资源。
3.1 修改amoeba.xml
3.1.1 配置server
[root@amoeba1 amoeba]# cd /usr/local/amoeba/conf/
[root@amoeba1 conf]# vi amoeba.xml
| 配置项 |
是否必选 |
默认值 |
说明 |
| port | 否 |
8066 |
amoeba server绑定的对外端口 |
| ipAddress |
否 |
空 |
Amoeba绑定的IP |
| user |
是 |
空 |
客户端连接到Amoeba的用户名 |
| password |
否 |
空 |
客户端连接到Amoeba的密码 |
| readThreadPoolSize |
否 |
16 |
负责读客户端、database server端网络数据包线程数 |
| clientSideThreadPoolSize |
否 |
16 |
负责读执行客户端请求的线程数 |
| serverSideThreadPoolSize |
否 |
16 |
负责处理服务端返回数据包的线程数 |
我配置的数据是:将端口号修改为了3306,用户root,密码123456,ip:192.168.88.17
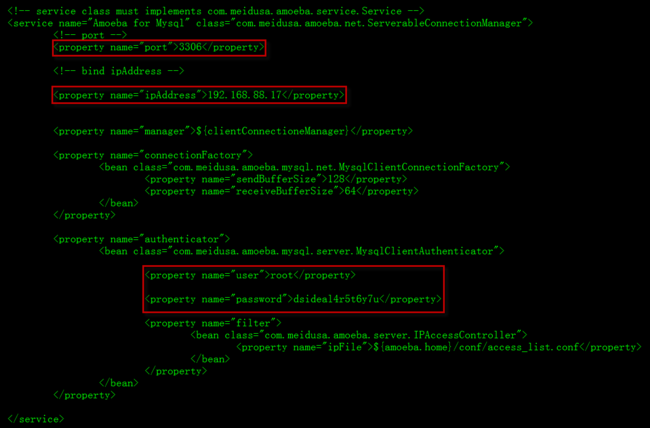
3.1.2 注释amoeba for monitor,因为我们不需要这个功能,只需要amoeba for mysql
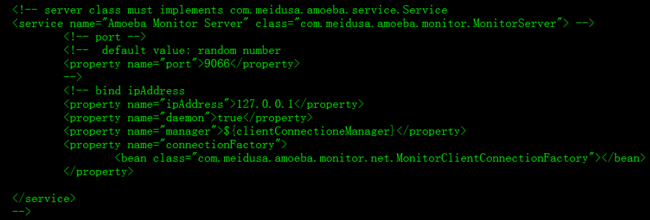
3.1.3 配置runtime,具体意义参看3.1.1图标
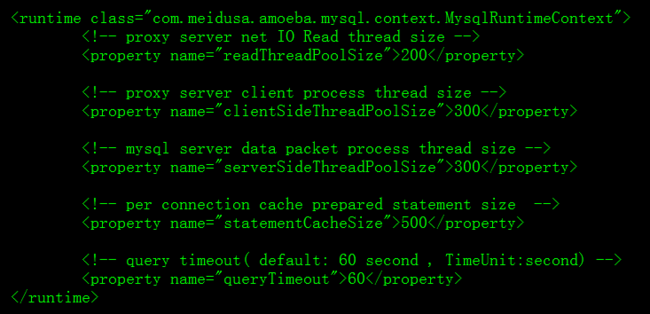
3.1.4 配置connectionManager:需要至少配置一个ConnectionManager,每个ConnectionManager将作为一个线程启动,ConnectionManager负责管理所注册在自身的Connection,负责他们的空闲检测、死亡检测、IO Event
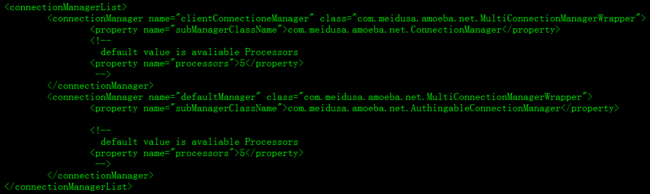
3.1.5 配置默认引用其他配置文件,这里需要修改读写分离的数据库name值
| 配置项 |
是否必选 |
默认值 |
说明 |
| class |
是 |
空 |
QueryRouter实现类,Amoeba for Mysql (com.meidusa.amoeba.mysql.parser.MysqlQueryRouter) |
| functionConfig |
否 |
空 |
用于解析sql函数的配置文件,如果不配置则将不解析包含函数sql或者解析的不完整 |
| ruleConfig |
否 |
空 |
数据切分规则配置文件,如果不配置则sql数据切分功能将不能用 |
| needParse |
否 |
true |
是否对sql进行parse,如果false则将不能使用数据切分、读写分离等功能 |
| defaultPool |
是 |
空 |
needParse=false,无法解析query,不满足切分规则的,writePool | readPool = null情况。所有sql将在默认的dbServer上面执行。 |
| writePool |
否 |
空 |
启用needParse功能,并且没有匹配到数据切分规则,则update、inster、delete语句将在这个pool中执行 |
| readPool |
否 |
空 |
启用needParse功能,并且没有匹配到数据切分规则,则select语句将在这个pool中执行 |
| LRUMapSize |
否 |
1000 |
statment cache , 存放sql解析后得到的statment |
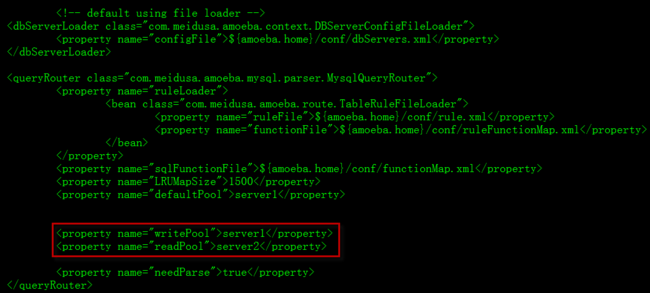
3.2 配置dbServer.xml
3.2.1 配置文件信息:
Each dbServer needs to be configured into a Pool,If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration: add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfig such as 'multiPool' dbServer
一台mysqlServer 需要配置一个pool,如果多台 平等的mysql需要进行loadBalance,平台已经提供一个具有负载均衡能力的objectPool:com.meidusa.amoeba.mysql.server.MultipleServerPool,简单的配置是属性加上 virtual="true",该Pool 不允许配置factoryConfig或者自己写一个ObjectPool。
3.2.2 配置 factoryconfig,配置amoeba访问信息,注意默认的注释问题,要把密码注释去掉
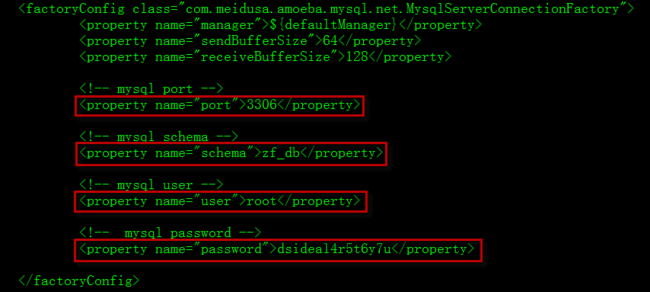
3.2.3 配置连接池信息
| 配置项 |
是否必选 |
默认值 |
说明 |
| className |
否 |
com.meidusa.amoeba.net.poolable.PoolableObjectPool |
连接池实现类 |
| maxActive |
否 |
8 |
最大活动连接数,如果达到最大活动连接数,则会等待 |
| maxIdle |
否 |
8 |
最大空闲连接数,如果超过则将会关闭多余的空闲连接 |
| minIdle |
否 |
0 |
最小空闲连接数,连接池将保持最小的空闲连接,即使这些连接长久不用 |
| testOnBorrow |
否 |
false |
当连接在使用前 |
| testWhileIdle |
否 |
false |
是否检测空闲连接数,这个参数启动的时候下列两个参数才有效 |
| minEvictableIdleTimeMillis |
否 |
30分钟 |
连接空闲数多少时间将被驱逐(关闭)(time Unit:ms) |
| timeBetweenEvictionRunsMillis |
否 |
-1 |
用于关闭空闲连接每间隔多少时间检查一次空闲连接(time Unit:ms) |
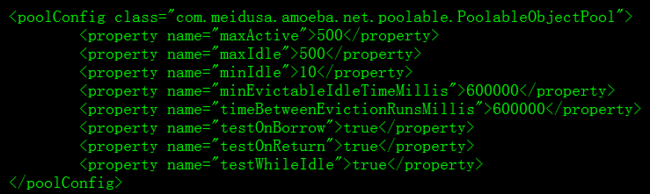
3.2.4 配置读写数据库name名和ip地址
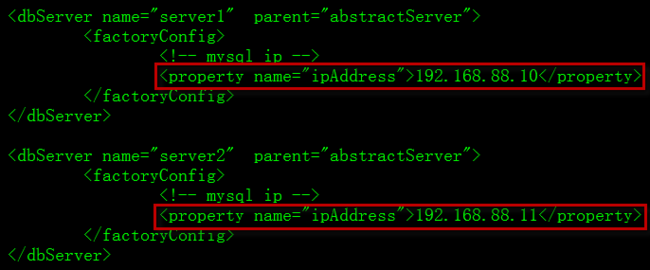
3.2.5 配置读写分离连接池:Amoeba提供读写分离pool相关配置。并且提供负载均衡配置。可配置slave1、slave2形成一个虚拟的virtualSlave,该配置提供负载均衡、failOver、故障恢复。
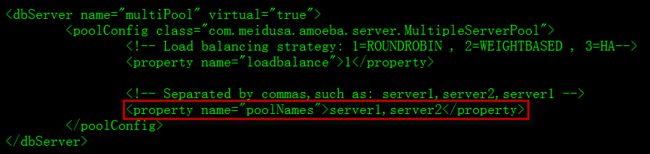
3.3 配置log4j.xml文件
3.3.1 在可用性测试已经完成的情况下, 建议将log4j.xml 中关于日志输出level为info的全部设置成warn或者error级别. 日志是非常消耗系统性能的, 在没有必要的情况下可以不使用debug.
本人暂时还是测试环境,所以未修改此项配置
3.4 开启防火墙amoeba设置的端口,本人amoeba服务器没有安装mysql,因此自定义的amoeba是3306端口,开启如下
[root@amoeba1 ~]# vi /etc/sysconfig/iptables
编辑文件,在
-A INPUT -j REJECT --reject-with icmp-host-prohibited之前
加入
-A INPUT -p tcp -m state --state NEW -m tcp --dport 3306 -j ACCEPT
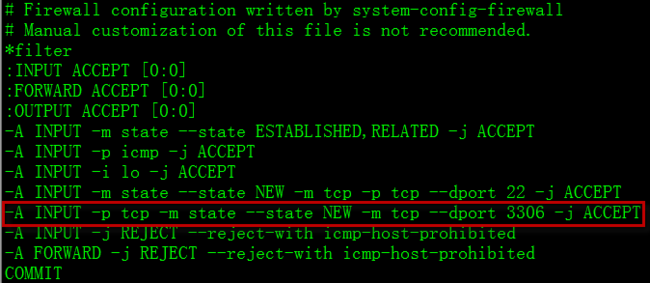
重启防火墙服务
[root@amoeba1 ~]# service iptables restart

四:读写分离测试
4.1 测试思路:因为两个是在两个主从数据库上实现读写分离,向主数据库写入操作,从数据库通过数据库复制同步主数据库内容,读取时读取从数据库数据,因此,我在主从数据库上建立同样的表,然后断开从数据库的复制,在主从数据库分别插入不同数据,再连接amoeba服务器,写入第三条语句,此时主数据库有1,3两条数据,从数据库只有2一条数据,证明写入是master数据库,读取是slave数据库。
4.1.1 开启amoeba
[root@amoeba1 ~]# /usr/local/amoeba/bin/amoeba start

4.1.2 在主从数据库复制成功的前提下,在主数据库创建一张测试表,从数据库自动复制此操作
#主数据库,进入mysql
[root@mysql1 ~]# /usr/local/mysql/bin/mysql -u root -p123456
mysql> use zf_db;
mysql> create table test_amoeba(id int);
mysql> select * from test_amoeba;
![]()
4.1.3 从数据库查看是否成功创建test_amoeba测试表
#从数据库
[root@mysql2 ~]# /usr/local/mysql/bin/mysql -u root -p123456
mysql> use zf_db;
mysql> select * from test_amoeba;
![]()
证明:主从复制成功
4.1.4 从数据库断开主从数据库复制
#从数据库
mysql> stop slave;
4.1.5 主数据库插入一条语句,数值1
#主数据库
mysql> INSERT INTO test_amoeba VALUES (1);
mysql> SELECT * FROM test_amoeba;
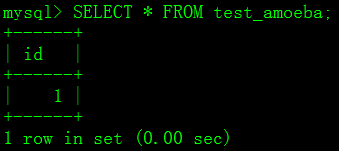
4.1.6 从数据库查看test_amoeba数据,因为已经断开复制,所以此时从数据库应该是没有值的
#从数据库
mysql> select * from test_amoeba;
![]()
4.1.7 从数据库在test_amoeba表中插入数值2
#从数据库
mysql> INSERT INTO test_amoeba VALUES (2);
mysql> select * from test_amoeba;
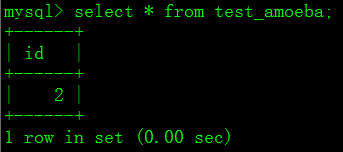
4.1.8 查询主数据库test_amoeba数据情况
#主数据库
mysql> select * from test_amoeba;
4.1.9 查询从数据test_amoeba数据情况
#从数据库
mysql> select * from test_amoeba;
注:此时主从数据库的数据是不一致的,以便我们证明amoeba的读写分离
4.1.10 使用mysql可视化软件连接amoeba服务器
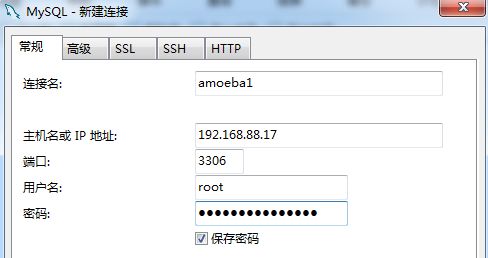
连接测试
注:如果没有成功,请注意amoeba服务器的iptables是否开启amoeba的端口
4.1.11 查看amoeba数据库显示内容
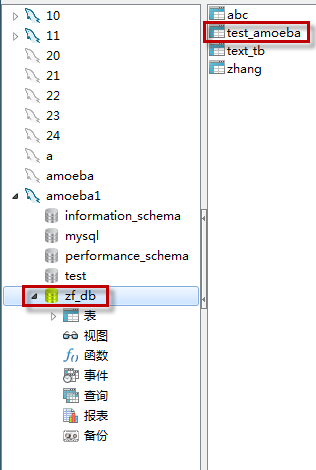
4.1.12 在amoeba服务器,向test_amoeba表写入数据
#amoeba服务器

4.1.13 查询主数据test_amoeba数据
#主数据库
mysql> select * from test_amoeba;
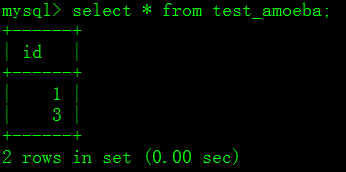
证明:通过amoeba服务器,我们写入数据进入到主数据库test_amoeba表中
4.1.14 查询从数据库test_amoeba数据
#从数据库
mysql> select * from test_amoeba;
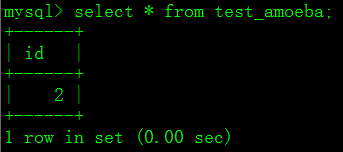
证明:在未开启主从数据库复制的情况下,向amoeba服务器写入数据时,从数据库未写入数据
4.1.15 连接amoeba服务器,查询test_amoeba数据
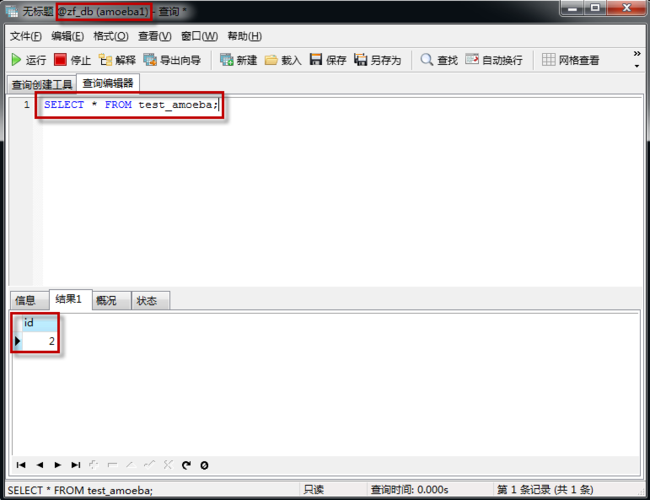
只能看到id为2的一条数据
证明:我们连接amoeba服务器时,读的数据是slave服务器的数据,因此,我们主从数据库的读写分离成功!