【Few-Shot Segmentation论文阅读笔记】Prototype Mixture Models for Few-Shot Semantic Segmentation, ECCV, 2020
Abstract
Target Probelm:Single Prototype ===> semantic ambiguity problem
为此,本文提出了Prototype Mixture Models (PMMs)
- PMMs使用多个prototype用来分别对应不同的image regions, 进而提高其语义表征能力
- 使用EM算法来估算prototype, 使得PMMs能够富含丰富的channel-wised和spatial语义信息
- PMMs既可以作为representations, 也可以作为classifier, 能够有效的激活query image中包含的前景信息,同时有效抑制背景区域。
代码: https://github.com/Yang-Bob/PMMs
1. Introduction
Inspiration
目前Few-shot segmentation方法主要是基于metric-learning framework, 并主要采用了prototype model。现有方法有以下两点不足:
- prototype model主要是基于global average pooling(GAP) guided by ground-truth masks来计算prototype的。但是在GAP算法中,the spatial layout of objects is completely dropped ==> easily mix semantic from various parts
- Single prototype 不足以包含充足的信息,表征能力有限
两点不足均会导致Semantic ambiguity problem.
Main Work:
为了解决这一问题,本文提出了PMMs。在训练过程中,我们使用EM算法来估计prototypes, 并分别为foreground和background进行建模,计算对应的multiple prototypes,以提高模型的判别能力。
优点:
- 一方面,PMM可以作为spatially squeezed representation, which match (P-Match) with query features to activate feature channels related to the object class.
- 另一方面,each prototype vector可以看作一个C维的线性分类器,将P-Conv与query features进行element-wised乘,可以生成相应的probability map.
综上,PMMs既包含了channel-wised语义信息,也包含了spatial语义信息,极大的提高了对query image进行语义分割的准确性。
2. Related Work
Few-Shot Segmentation + Key references (需要阅读的)
- Ref 12-19, 35
- 12. Tokmakov, P., Wang, Y., Hebert, M.: Learning compositional representations for few-shot recognition. In: IEEE ICCV. (2019) 6372–6381
- 13. Nguyen, K., Todorovic, S.: Feature weighting and boosting for few-shot segmen- tation. In: IEEE ICCV. (2019) 622–63
- 14. Shaban, A., Bansal, S., Liu, Z., Essa, I., Boots, B.: One-shot learning for semantic segmentation. In: BMVC. (2017)
- 15. Zhang, X., Wei, Y., Yang, Y., Huang, T.: Sg-one: Similarity guidance network for one-shot semantic segmentation. CoRR abs/1810.09091 (2018)
- 16. Dong, N., Xing, E.P.: Few-shot semantic segmentation with prototype learning. In: BMVC. (2018) 79
- 17. Hao, F., He, F., Cheng, J., Wang, L., Cao, J., Tao, D.: Collect and select: Semantic alignment metric learning for few-shot learning. In: IEEE ICCV. (2019) 8460–8469
- 18. Wang, K., Liew, J., Zou, Y., Zhou, D., Feng, J.: Panet: Few-shot image semantic segmentation with prototype alignment. (2019) 622–631
- 19. Zhang, C., Lin, G., Liu, F., Yao, R., Shen, C.: Canet: Class-agnostic segmenta- tion networks with iterative refinement and attentive few-shot learning. In: IEEE CVPR. (2019) 5217–5226
- 35. Rakelly, K., Shelhamer, E., Darrell, T., Efros, A.A., Levine, S.: Conditional net- works for few-shot semantic segmentation. In: ICLR Workshop. (2018)
- Ref 31, 4 (ASPP), 19, 32
- 31. Snell, J., Swersky, K., Zemel, R.S.: Prototypical networks for few-shot learning. In: NeurIPS. (2017) 4077–4087
- 4. Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Seman- tic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4) (2018) 834–84
- 32. Banerjee, A., Dhillon, I.S., Ghosh, J., Sra, S.: Clustering on the unit hypersphere using von mises-fisher distributions. J. Mach. Learn. Res. 6 (2005) 1345–1382
3. Proposed Method
本文提出的算法也遵循Metric-Learning Framework, 由两个branch组成,分别是support branch和query branch。两个branch的Feature Extraction network共享权重,分别从support image和query image中提取对应的feature map, S, Q ∈××, 其中×代表resolution of feature map, 代表channels.

3.1 Prototype Mixture Models (PMMs)
对应代码:PMM.py的generate_prototype()函数

PMM models:
a probability mixture model which linearly combined probabilities from the distributions.
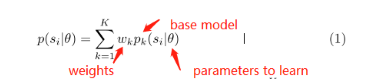
表示第k个base model, 即:一个a probability model based on kernel distance function, 可以被表示为:
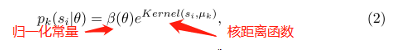
核距离函数可以使用:Gaussian模型(RBF距离)或者VMF模型(cosine距离)。
由于本文算法是基于metric-learning framework的,因此采用vector distance function更合适,即VMF模型的cosine距离:
![]()
==> 可以被表示为:
![]()
is the mean vector of the k-th model, 即我们所说的prototype。
该基模型的参数是:![]()
![]()
![]()
Models Learning: 使用EM算法估计+和−作为prototypes vectors:

注意:本文中PMM model (公式(1))中的mixture coefficient 使用相同权重。
另外,可以看出,每个prototype vector都是the mean of a cluster samples ==> 即:每个prototype都代表一个region around an object part in the original image for the reception field effect.
3.2 Few-Shot Segmentation

P-Match (PMMs as Representation)
代码:PMM.py discriminative_model
每个foreground prototypes都包含着an object part对应的表征信息,将其组合在一起则可包含更多的表征信息,尽可能表示complete object extent。因此,foreground prototypes可以用来match and activate the query features Q.

P-Conv (PMMs as classifiers)
每个prototype vector都包含着discriminative information, 都可以看作一个classifier.

之后,再与′进行concatenate, 得到activated query map ′′:
![]()
至此,the semantic information across channels and discriminative information related to object parts are collected from the support feature to activate the query feature Q in a dense comparison manner.
最后,将activated query map ′′ 输入ASPP,再输入卷积层 ==> 生成predicted mask.
Segmentation Model Learning
分割模块is implemented in an E2E framework, see Algorithm 1:

3.3 Residual Prototype Mixture Models (RPMM)
Implement an ensemble model by stacking multiple PMMs ==> RPMM.
RPMM leverages the residual from the previous query branch to supervised the next query branch for fine-grained segmentation.
好处:不仅可以进一步提高模型性能,也定义了一种新的model ensemble strategy.

4. Experiments
对比方法:CANet[19] without iterative optimization
Training过程中:
- 使用4种Data Augmentation的方法:
- Normalization, horizontal flipping, random cropping, random resizing.
- EM算法: iterates 10 rounds for each image
- Cross-entropy loss +SGD
- Momentum =0.9, learning rate = 0.0035, iteration times = 200,000
数据集:
- PASCAL 5i [14]+[34]: 包含20类,分为4组
- COCO-20i [13]: 80类,分为4组,每组20类
评估标准: IoU
4.1 Model Analysis
Fig 6 可视化了
- Probability maps produced by positive prototypes of PMMs
- Activation maps
- Segmentation masks
对比可以发现:CANet使用单一的prototype来activate object tends to miss object parts/whole objects. 而PMMs能够alleviate seantic ambiguity problem.

Fig7对比分割结果和Baseline Method:
- P-Match能够提高recall rate by segmenting more target pixels.
- PMMs reduce False Positive pixels by introduce background prototypes.
- RPMMs能够进一步提高分割结果

4.2 消融实验
Table 1
- PMMs
- 说明PMMs的P-Match Models 优于 global average pooling, 说明PMMs能够产生更好的prototypes.
- Background & foreground prototypes能够提高performance.
- RPMMs, 说明了the effectiveness of the residual ensemble strategy

Table 2: Number of prototypes
为什么k=5反而效果下降?
原因:PMMs是在一张support image上进行分析和生成prototypes, 而一张图片包含的信息和表征能力有限,k越大,则可能会导致过拟合的风险。

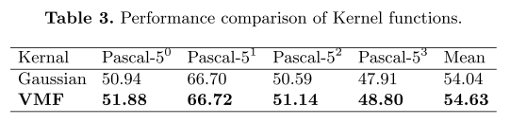
Table3:Kernel function
VMF kernel is better than Gaussian.
Inference Speed:
模型大小:OSLSM[14] (272.6M) >> RPMM (19.6M)>PMMs (19.5M) >略大于 CANet[19] (19M)
Inference速度:k=3时,PMM的速度是26FPS,RPMM是20FPS;而CANet是29FPS
4.3 Performance

Conclusion
PMMs 结合了 diverse image regions with multiple prototypes to solve the semantic ambiguity problem.
- Training过程中结合了丰富的channel-wise和spatial semantic information from support images
- Inference阶段,match PMMs with query images in a duplex manner 实现了准确的分割
- 在Pascal-5i和COCO 20i上均取得较好效果
- 并且可以扩展到Few-shot learning问题
Comments
文章的优点在于
- 既利用了multiple prototypes
- 又采用了background+foreground prototypes信息对query feature进行激活
(代码写的很好,值得学习)