深度探索 Flink SQL
文章将从用户的角度来讲解 Flink 1.9 版本中 SQL 相关原理及部分功能变更,希望加深大家对 Flink 1.9 新功能的理解,在使用上能够有所帮助。
新 TableEnvironment
FLIP-32 中提出,将 Blink 完全开源,合并到 Flink 主分支中。合并后在 Flink 1.9 中会存在两个 Planner:Flink Planner 和 Blink Planner。
在之前的版本中,Flink Table 在整个 Flink 中是一个二等公民。而 Flink SQL 具备的易用性,使用门槛低等特点深受用户好评,也越来越被重视,Flink Table 模块也因此被提升为一等公民。而 Blink 在设计之初就考虑到流和批的统一,批只是流的一种特殊形式,所以在将 Blink 合并到 Flink 主分支到过程中,社区也同时考虑了 Blink 的特殊设计。
新 TableEnvironment 整体设计

从图 1 中,可以看出,TableEnvironment 组成部分如下:
- flink-table-common:这个包中主要是包含 Flink Planner 和 Blink Planner 一些共用的代码。
- flink-table-api-java:这部分是用户编程使用的 API,包含了大部分的 API。
- flink-table-api-scala:这里只是非常薄的一层,仅和 Table API 的 Expression 和 DSL 相关。
- 两个 Planner:flink-table-planner 和 flink-table-planner-blink。
- 两个 Bridge:flink-table-api-scala-bridge 和 flink-table-api-java-bridge,从图中可以看出,Flink Planner 和 Blink Planner 都会依赖于具体的 Java API,也会依赖于具体的 Bridge,通过 Bridge 可以将 API 操作相应的转化为 Scala 的 DataStream、DataSet,或者转化为 JAVA 的 DataStream 或者 DataSet。
新旧 TableEnvironment 对比
在 Flink 1.9 之前,原来的 Flink Table 模块,有 7 个 Environment,使用和维护上相对困难。7 个 Environment 包括:StreamTableEnvironment,BatchTableEnvironment 两类,JAVA 和 Scala 分别 2 个,一共 4 个,加上 3 个父类,一共就是 7 个。
在新的框架之下,社区希望流和批统一,因此对原来的设计进行精简。首先,提供统一的 TableEnvironment,放在 flink-table-api-java 这个包中。然后,在 Bridge 中,提供了两个用于衔接 Scala DataStream 和 Java DataStream 的 StreamTableEnvironment。最后,因为 Flink Planner 中还存在着 toDataSet() 类似的操作,所以,暂时保留 BatchTableEnvironment。这样,目前一共是 5 个 TableEnvironment。
因为未来 Flink Planner 将会被移除,BatchTableEnvironment 就会被废弃,这样,未来就剩下 3 个 Environment 了,整个 TableEnvironment 的设计将更加简洁明了。
新 TableEnvironment 的应用
本节中,将介绍新的应用场景以及相关限制。
下图详细列出了新 TableEnvironment 的适用场景:

第一行,简单起见,在后续将新的 TableEnvironment 称为 UnifyTableEnvironment。在 Blink 中,Batch 被认为是 Stream 的一个特例,因此 Blink 的 Batch 可以使用 UnifyTableEnvironment。
UnifyTableEnvironment 在 1.9 中有一些限制,比如它不能够注册 UDAF 和 UDTF,当前新的 Type System 的类型推导功能还没有完成,Java、Scala 的类型推导还没统一,所以这部分的功能暂时不支持。可以肯定的是,这部分功能会在 1.10 中实现。此外,UnifyTableEnvironment 无法转化为 DataStream 和 DataSet。
第二行,StreamTableEnvironment 支持转化成 DataStream,也可以注册 UDAF 和 UDTF。如果是 JAVA 写的,就注册到 JAVA 的 TableEnvironment,如果是用 Scala 写的,就注册到 Scala 的 TableEnvironment。
注意,Blink Batch 作业是不支持 Stream TableEnvironment 的,因为目前没有 toAppendStream(),所以 toDataStream() 这样的语义暂时不支持。从图中也可以看出,目前操作只能使用 TableEnvironment。
最后一行,BatchTableEvironment 能够使用 toDataSet() 转化为 DataSet。
从上面的图 2 中,可以很清晰的看出各个 TableEnvironment 能够做什么事情,以及他们有哪些限制。
新 Catalog 和 DDL
构建一个新的 Catalog API 主要是 FLIP-30 提出的,之前的 ExternalCatalog 将被废弃,Blink Planner 中已经不支持 ExternalCatalog 了,Flink Planner 还支持 ExternalCatalog。
新 Catalog 设计
下图是新 Catalog 的整体设计:

可以看到,新的 Catalog 有三层结构,最顶层是 Catalog 的名字,中间一层是 Database,最底层是各种 MetaObject,如 Table,Partition,Function 等。当前,内置了两个 Catalog 实现:MemoryCatalog 和 HiveCatalog。当然,用户也可以实现自己的 Catalog。
Catalog 能够做什么事情呢?首先,它可以支持 Create,Drop,List,Alter,Exists 等语句,另外它也支持对 Database,Table,Partitioon,Function,Statistics 等等操作。基本上,常有的 SQL 语法都已经支持。
CatalogManager 正如它名字一样,主要是用来管理 Catalog,且可以同时管理多个 Catalog。也就是说,可以通过在一个相同 SQL 中,跨 Catalog 做查询或者关联操作。
例如,支持对 A Hive Catalog 和 B Hive Catalog 做相互关联,这给 Flink 的查询带来了很大的灵活性。
CatalogManager 支持的操作包括:
- 注册 Catalog (registerCatalog)
- 获取所有的 Catalog (getCatalogs)
- 获取特定的 Catalog (getCatalog)
- 获取当前的 Catalog (getCurrentCatalog)
- 设置当前的 Catalog (setCurrentCatalog)
- 获取当前的 Database (getCurrentDatabase)
- 设置当前的 Database (setCurrentDatabase)
Catalog 虽然设计了三层结构,但在使用的时候,并不需要完全指定三层结构的值,可以只写 Table Name,这时候,系统会使用 getCurrentCatalog,getCurrentDatabase 获取到默认值,自动补齐三层结构,这种设计简化了对 Catalog 的使用。如果需要切换默认的 Catalog,只需要调用 setCurrentCatalog 就可以。
在 TableEnvironment 层,提供了操作 Catalog 的方法,例如:
- 注册 Catalog (registerCatalog)
- 列出所有的 Catalog (listCatalogs)
- 获取指定 Catalog(getCatalog)
- 使用某个 Catalog(useCatalog)
在 SQL Client 层,也做了一定的支持,但是功能有一定的限制。用户不能够使用 Create 语句直接创建 Catalog,只能通过在 yarn 文件中,通过定义 Description 的方式去描述 Catalog,然后在启动 SQL Client 的时候,通过传入 -e + file_path 的方式,定义 Catalog。目前 SQL Client 支持列出已定义的 Catalog,使用一个已经存在的 Catalog 等操作。
DDL 设计与使用
有了 Catalog,就可以使用 DDL 来操作 Catalog 的内容,可以使用 TableEnvironment 的 sqlUpdate() 方法执行 DDL 语句,也可以在 SQL Client 执行 DDL 语句。
sqlUpdate() 方法中,支持 Create Table,Create View,Drop Table,Drop View 四个命令。当然,insert into 这样的语句也是支持的。
下面分别对 4 个命令进行说明:
1、Create Table:可以显示的指定 Catalog Name 或者 DB Name,如果缺省,那就按照用户设定的 Current Catalog 去补齐,然后可以指定字段名称,字段的说明,也可以支持 Partition By 语法。最后是一个 with 参数,用户可以在此处指定使用的 Connector,例如,Kafka,CSV,HBase 等。with 参数需要配置一堆的属性值,可以从各个 Connector 的 Factory 定义中找到。Factory 中会指定有哪些比选属性,那些可选属性值。
需要注意的是,目前 DDL 中,还不支持计算列和 Watermark 的定义,后续的版本中将会继续完善这部分。
Create Table [[catalog_name.]db_name.]table_name (
a int comment 'column comment',
b bigint,
c varchar
)comment 'table comment'
[partitioned by(b)]
With(
update-mode='append',
connector.type='kafka',
...
)
2、Create View:需要指定 View 的名字,然后紧跟着是 SQL。View 将会存储在 Catalog 中。
CREATE VIEW view_name AS SELECT xxx
3、Drop Table & Drop View:和标准 SQL 语法差不多,支持使用 IF EXISTS 语法,如果未加 IF EXISTS,Drop 一个不存在的表,会抛出异常。
DROP TABLE [IF EXISTS] [[catalog_name.]db_name.]table_name
4、SQL Client 中执行 DDL:大部分都只支持查看操作,仅可以使用 Create View 和 Drop View。Catalog,Database,Table,Function 这些只能做查看。用户可以在 SQL Client 中 Use 一个已经存在的 Catalog,修改一些属性,或者做 Description,Explain 这样的一些操作。
CREATE VIEW
DROP VIEW
SHOW CATALOGS/DATABASES/TABLES/FUNCTIONS l USE CATALOG xxx
SET xxx=yyy
DESCRIBE table_name
EXPLAIN SELECT xxx
DDL 部分,在 Flink 1.9 中其实基本已经成型,只是还有一些特性,在未来需要逐渐的完善。
Blink Planner
本节将主要从 SQL/Table API 如何转化为真正的 Job Graph 的流程开始,让大家对 Blink Planner 有一个比较清晰的认识,希望对大家阅读 Blink 代码,或者使用 Blink 方面有所帮助。然后介绍 Blink Planner 的改进及优化。
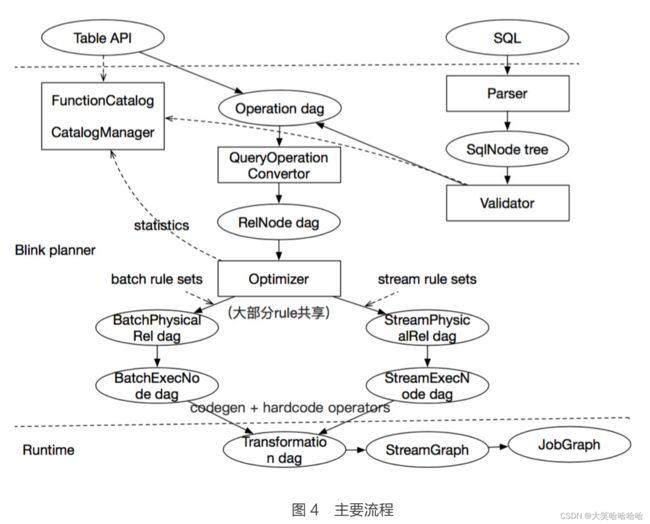
从上图可以很清楚的看到,解析的过程涉及到了三层:Table API/SQL,Blink Planner,Runtime,下面将对主要的步骤进行讲解。
Table API & SQL 解析验证:在 Flink 1.9 中,Table API 进行了大量的重构,引入了一套新的 Operation,这套 Operation 主要是用来描述任务的 Logic Tree。
当 SQL 传输进来后,首先会去做 SQL 解析,SQL 解析完成之后,会得到 SqlNode Tree (抽象语法树),然后会紧接着去做 Validator (验证),验证时会去访问 FunctionManager 和 CatalogManager,FunctionManager 主要是查询用户定义的 UDF,以及检查 UDF 是否合法,CatalogManager 主要是检查这个 Table 或者 Database 是否存在,如果验证都通过,就会生成一个 Operation DAG (有向无环图)。
从这一步可以看出,Table API 和 SQL 在 Flink 中最终都会转化为统一的结构,即 Operation DAG。
生成 RelNode:Operation DAG 会被转化为 RelNode (关系表达式) DAG。
优化:优化器会对 RelNode 做各种优化,优化器的输入是各种优化的规则,以及各种统计信息。当前,在 Blink Planner 里面,绝大部分的优化规则,Stream 和 Batch 是共享的。差异在于,对 Batch 而言,它没有 state 的概念,而对于 Stream 而言,它是不支持 sort 的,所以目前 Blink Planner 中,还是运行了两套独立的规则集 (Rule Set),然后定义了两套独立的 Physical Rel:BatchPhysical Rel 和 StreamPhysical Rel。优化器优化的结果,就是具体的 Physical Rel DAG。
转化:得到 Physical Rel DAG 后,继续会转化为 ExecNode,通过名字可以看出,ExecNode 已经属于执行层的概念了,但是这个执行层是 Blink 的执行层,在 ExecNode 中,会进行大量的 CodeGen 的操作,还有非 Code 的 Operator 操作,最后,将 ExecNode 转化为 Transformation DAG。
生成可执行 Job Graph:得到 Transformation DAG 后,最终会被转化成 Job Graph,完成 SQL 或者 Table API 的解析。
Blink Planner 改进及优化
Blink Planner 功能方面改进主要包含如下几个方面:
- 更完整的 SQL 语法支持:例如,IN,EXISTS,NOT EXISTS,子查询,完整的 Over 语句,Group Sets 等。而且已经跑通了所有的 TPCH,TOCDS 这两个测试集,性能还非常不错。
- 提供了更丰富,高效的算子。
- 提供了非常完善的 cost 模型,同时能够对接 Catalog 中的统计信息,使 cost 根据统计信息得到更优的执行计划。
- 支持 join reorder。
- shuffle service:对 Batch 而言,Blink Planner 还支持 shuffle service,这对 Batch 作业的稳定性有非常大的帮助,如果遇到 Batch 作业失败,通过 shuffle service 能够很快的进行恢复。
性能方面,主要包括以下部分:
- 分段优化。
- Sub-Plan Reuse。
- 更丰富的优化 Rule:共一百多个 Rule ,并且绝大多数 Rule 是 Stream 和 Batch 共享的。
- 更高效的数据结构 BinaryRow:能够节省序列化和反序列化的操作。
- mini-batch 支持(仅 Stream):节省 state 的访问的操作。
- 节省多余的 Shuffle 和 Sort(Batch 模式):两个算子之间,如果已经按 A 做 Shuffle,紧接着他下的下游也是需要按 A Shuffle 的数据,那中间的这一层 Shuffle,就可以省略,这样就可以省很多网络的开销,Sort 的情况也是类似。Sort 和 Shuffle 如果在整个计算里面是占大头,对整个性能是有很大的提升的。
Agg 分类优化
Blink 中的 Aggregate 操作是非常丰富的:
- group agg,例如:select count(a) from t group by b
- over agg,例如:select count(a) over(partition by b order by c) from t
- window agg,例如:select count(a) from t group by tumble(ts, interval ‘10’ second), b
- table agg,例如:tEnv.scan(‘t’).groupBy(‘a’).flatAggregate(flatAggFunc(‘b’ as (‘c’, ‘d’)))
下面主要对 Group Agg 优化进行讲解,主要是两类优化。
1、Local/Global Agg 优化
Local/Global Agg 主要是为了减少网络 Shuffle。要运用 Local/Global 的优化,必要条件如下:
- Aggregate 的所有 Agg Function 都是 mergeable 的,每个 Aggregate 需要实现 merge 方法,例如 SUM,COUNT,AVG,这些都是可以分多阶段完成,最终将结果合并;但是求中位数,计算 95% 这种类似的问题,无法拆分为多阶段,因此,无法运用 Local/Global 的优化。
- table.optimizer.agg-phase-strategy 设置为 AUTO 或者 TWO_PHASE。
- Stream 模式下,mini-batch 开启 ;Batch 模式下 AUTO 会根据 cost 模型加上统计数据,选择是否进行 Local/Global 优化。
select count(*) from t group by color
没有优化的情况下,下面的这个 Aggregate 会产生 10 次的 Shuffle 操作。

使用 Local/Global 优化后,会转化为下面的操作,会在本地先进行聚合,然后再进行 Shuffle 操作,整个 Shuffle 的数据剩下 6 条。在 Stream 模式下,Blink 其实会以 mini-batch 的维度对结果进行预聚合,然后将结果发送给 Global Agg 进行汇总。

2、Distinct Agg 优化
Distinct Agg 进行优化,主要是对 SQL 语句进行改写,达到优化的目的。但 Batch 模式和 Stream 模式解决的问题是不同的:
- Batch 模式下的 Distinct Agg,需要先做 Distinct,再做 Agg,逻辑上需要两步才能实现,直接实现 Distinct Agg 开销太大。
- Stream 模式下,主要是解决热点问题,因为 Stream 需要将所有的输入数据放在 State 里面,如果数据有热点,State 操作会很频繁,这将影响性能。
Batch 模式
第一层,求 distinct 的值和非 distinct agg function 的值,第二层求 distinct agg function 的值。
select color,count(distinct id),count(*) from t group by color
手工改写成:
select color, count(id), min(cnt)
from (
select color, id, count(*) filter (where $e = 2) as cnt
from (
select color, id, 1 as $e from t
union all
select coolor, null as id, 2 as $e from t
) group by color, id, $e
) group by color
转化的逻辑过程,如下图所示:

Stream 模式
Stream 模式的启用有一些必要条件:
- 必须是支持的 agg function:avg/count/min/max/first_value/concat_agg/single_value
- table.optimizer.distinct-agg.split.enabled (默认关闭)
select color,count(distinct id),count(*) from t group by color
手工改写成:
select color,sum(dcnt),sum(cnt)
from (
select color, count(distinct id) as dcnt, count(*) as cnt
from t
group by color, mod(hash_code(id), 1024)
) group by color
改写前,逻辑图大概如下:

改写后,逻辑图就会变为下面这样,热点数据被打散到多个中间节点上。
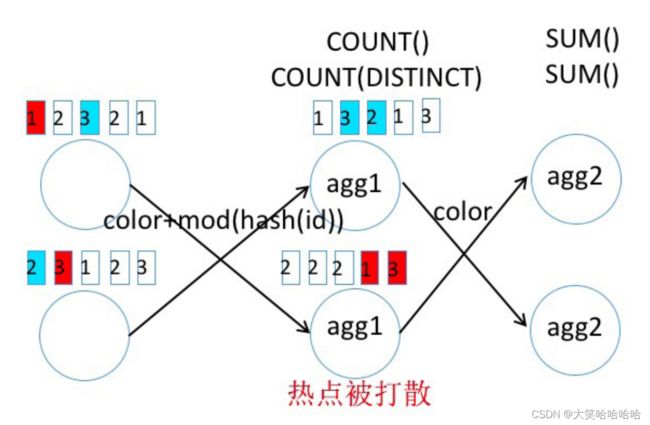
需要注意的是,示例中的 SQL 中 mod(hash_code(id),1024) 中的这个 1024 为打散的维度,这个值建议设置大一些,设置太小产生的效果可能不好。