ElasticSearch安装、启动、操作及概念简介
ElasticSearch快速入门
文件链接:https://pan.baidu.com/s/15kJtcHY-RAY3wzpJZIn4-w?pwd=0k5a
提取码:0k5a
有些软件对于安装路径有一定的要求,例如:路径中不能有空格,不能有中文,不能有特殊符号,等等。
为了避免不必要的麻烦,也懒得一一辨别踩坑,我们人为作出「统一的约定」:
- 解压版的软件,一律安装在没中文、没空格的路径~~~
Elasticsearch 只有解压版本,没有安装版
Elastic 官网:https://www.elastic.co/cn/
Elastic 有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash 等,前面说的三个就是大家常说的 ELK 技术栈。

Elasticsearch 具备以下特点:
- 分布式,无需人工搭建集群(solr 就需要人为配置,使用 Zookeeper 作为注册中心);
- Restful 风格,一切 API 都遵循 Restful 原则,容易上手;
- 近实时搜索,数据更新在 Elasticsearch 中几乎是完全同步的。
kibana 从 7.11 开始升级了 node.js 的版本,因此,从这个版本开始不再支持 win7,也就是说,win7 能使用的 kibana 的最后的版本是 7.10.2 。
1. 安装 Elasticsearch
文件链接:https://pan.baidu.com/s/15kJtcHY-RAY3wzpJZIn4-w?pwd=0k5a
提取码:0k5a
1.1 下载解压
1.2 配置
本步骤是可选操作:如果机子内存足够大也可以不改配置
我们进入 elasticsearch-7.11.1/config 目录:
需要修改的配置文件有两个:
- elasticsearch.yml
- jvm.options
1.2.1 jvm.options
Elasticsearch 基于 Lucene 的,而 Lucene 底层是 java 实现,若本机内存不够需要配置 jvm 参数。
在jvm.options.d文件下创建配置文件(文件后缀是options即可)例如heap.options
-
内存占用太多了,我们调小一些:
-Xms512m -Xmx512m
1.2.2 elasticsearch.yml
elasticsearch.yml 配置文件暂时不用改动。
1.3 运行
进入 elasticsearch-7.11.1\bin 目录
双击 elasticsearch.bat,启动成功时(启动失败可以从下面的文章链接去解决问题),会显示 started 字样,并且可我们在浏览器中访问:http://127.0.0.1:9200,可见类似如下内容:
{
"name" : "DESKTOP-T540P",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "XvelzExUQgud2iqO9QLA4w",
"version" : {
"number" : "7.11.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"build_date" : "2021-01-13T00:42:12.435326Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
启动如果出现闪退,您可以看这篇文章解决elasticsearch.bat启动闪退的详细解决方案

2. elasicsearch 概念
2.1数据分类和查询方式
我们生活中的数据总体分为两种:
| # | 数据类型 | 说明 |
|---|---|---|
| 1 | 结构化数据 | 指具有固定格式或有限长度的数据,如数据库,元数据等。 |
| 2 | 非结构化数据 | 指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件 |
- 结构化数据的查询方式
最常见的结构化数据也就是数据库中的数据。
结构化数据很容易查询,因为结构化的数据存储是有规律的。以数据库数据为例,它们有行,有列,有格式/类型,连数据的长度都是固定的。
非结构化数据的查询方式
-
顺序扫描法(Serial Scanning)
想象一下你在 Word 文档中使用
Ctrl + f进行搜索。所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
这个过程是相当慢的。
-
全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
从非结构化数据中提取出来的信息,通常也就是你所关注的核心信息,或者是搜索关键字。
例如:字典。字典有两套索引:拼音表和部首检字表。拼音表就是提取的各个文字的读音信息而组成的索引;部首检字表就是提取的各个文字的偏旁部首信息而组成的索引。
Note:一份非结构化数据,可以不止有一份索引。这种先建立索引,再对索引进行搜索的过程就叫全文检索(全文检索通常使用倒排索引来实现)(Full-text Search)。
正排索引和倒排索引区别
正排索引:由key查询实体的过程,使用正排索引
倒排索引:与正排索引相反,由item查询key的过程,使用倒排索引
举个例子
举个例子,假设有3个网页: url1 -> “我爱南京” url2 -> “我爱到家” url3 -> “到家美好” 这是一个正排索引: Map结构如下 分词之后: url1 -> {我,爱,南京} url2 -> {我,爱,到家} url3 -> {到家,美好} 这是一个分词后的正排索引: 分词后倒排索引: Map结构如下 我 -> {url1, url2} 爱 -> {url1, url2} 南京 -> {url1} 到家 -> {url2, url3} 美好 -> {url3} 由检索词item快速找到包含这个查询词的网页Map就是倒排索引虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
2.2 全文检索
可以使用 Lucene 实现全文检索。Lucene 是 apache 下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
Lucene 只是一个库(类似于汽车发动机),而非独立的产品。通过 Lucene 实现搜索功能,但你仍需作大量的其他的工作。Solr 和 ElasticSearch 都是基于 Lucene 的搜索引擎产品。
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google 等搜索引擎、论坛站内搜索、电商网站站内搜索等
3. elasticsearch简介
Elasticsearch 是一个基于 Lucene 的搜索服务器,它采用 Java 语言编写,使用 Lucene 构建索引、提供搜索功能,并以 Apache 许可条款发布。
Elasticsearch 对外提供了 RESTful API ,以使你能通过多种形式操作它。
Elasticsearch 的优点
- 分布式
- 全文检索
- 近实时搜索和分析
- 高可用
- RESTful API
3.1 核心概念
你完全可以将 Elasticsearch 当作一个数据库(NoSQL)来看待,以便于你的理解,也更方便与你通过现象看到它的本质。实际上在很多使用场景中,Elasticsearch 确实就是在扮演 NoSQL 数据库的角色。
类似于数据库的层次结构,Elastic Search 也是如此:
mysql es
└── database └── index
└── table └── type
└── row └── document
另外,在 SQL 数据库中被我们称作『列』的东西,实际上也被称作『字段』,只不过我们更习惯于使用前者。而 Elastic Search(和 Lucene)则是使用后一种称呼。
3.2 概念的弱化
虽然和 RDMS(关系型数据库) 中的概念有一一对应的关系,但是 Elasticsearch 正在一步步弱化 type 的概念,并计划在未来移除 type 这个概念。
这种情况下就类似于,数据库中人为约定:一个 database 里默认有且仅有一个 table 。此时,这个 table 叫什么,实际上就无关紧要了。即便是有这样的奇怪的约定,但是实际上仍不影响我们使用 MySQL,因为你仍然可以建多个 database 。
- 在
6.0的时候,已经默认只能支持一个索引中有且仅有一个 type 了; - 到了
7.0的时候,如果你在命令中指定 type 时,Elasticsearch 会提示你 type 被废弃(deprecated),建议使用 _doc 关键字替代。 - 更有甚至,很多原来需要填写 type-name 的地方,不仅仅是可以使用 _doc 替代,甚至连 _doc 都不用出现都是 ok 的。
3.3 es的restful风格api
Elastic Search 的一个特点就是对外提供 Restful API 来对其进行操作,因此,它直接利用 HTTP 的四种不同请求方式来表示当前操作是增删改查中的哪一种。
| HTTP 请求方式 | 操作 |
|---|---|
| POST | 新增操作,类似于 INSERT |
| DELETE | 删除操作,类似于 DELETE |
| PUT | 修改操作,类似于 UPDATE |
| GET | 查询操作,类似于 SELECT |
3.4 ES 中的数据类型
和数据库中的字段(列)有数据类型的概念一样,ElasticSearch 中 document 的每个『字段』也有数据类型的概念。ElasticSearch 支持的数据类型有:
-
字符串型:text,keyword
text 会被分词器分词;keyword 不会被分词器分词
-
数字:long, integer, short, double, float
-
日期:date
-
逻辑:boolean
再复杂一些的数据类型有:
- 对象类型:object
- 数组类型:array
- 地理位置:geo_point,geo_shape
3.5 其它
和数据库一样,Elastic Search 也有 集群、节点、分片、备份的概念。
另外,Elasticsearch 流行的原因之一就是其内置了集群功能,即它本身『天生』就是分布式的。即便你在单机上只有一个节点,Elasticsearch 也将它当做一个集群来看待。默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
4. 对ElasticSearch 操作(Postman操作)
4.1 操作索引
4.1.1 创建索引
对比关系型数据库,创建索引就等于创建数据库。
在postman 中,向ES服务器发送PUT 请求:http://127.0.0.1:9200/shopping
4.1.2 查询索引
在postman 中,向ES服务器发送GET请求:http://127.0.0.1:9200/shopping
查看ES 中所有索引 ,向ES服务器发送GET请求:http://127.0.0.1:9200/_cat/indices?v
4.1.3 删除索引
向ES服务器发送DELETE 请求:
http://127.0.0.1:9200/shopping
4.2 操作文档
4.2.1 创建文档
在postman 中,向ES服务器发送POST 请求:
http://127.0.0.1:9200/shopping/_doc
请求体
{
"title":"小米手机",
"category":"小米",
"image":"http://127.0.0.1/9000/phone/1111.jpg",
"price":3333.00
}

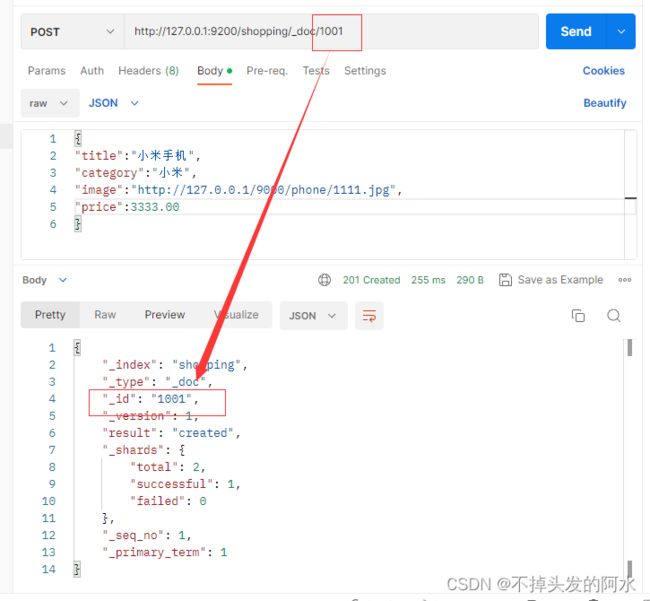
此时的请求会给这个文档自动生成一个id
指定id生成文档
向ES服务器发送PUT 请求:
http://127.0.0.1:9200/shopping/_doc/1001
请求体
{
"title":"小米手机1",
"category":"小米1",
"image":"http://127.0.0.1/9000/phone/1111.jpg",
"price":3333.00
}
4.2.1 查看文档
向ES服务器发送GET 请求:
http://127.0.0.1:9200/shopping/_doc/1001

向ES服务器发送GET 请求:
http://127.0.0.1:9200/shopping/_doc/1001/_source

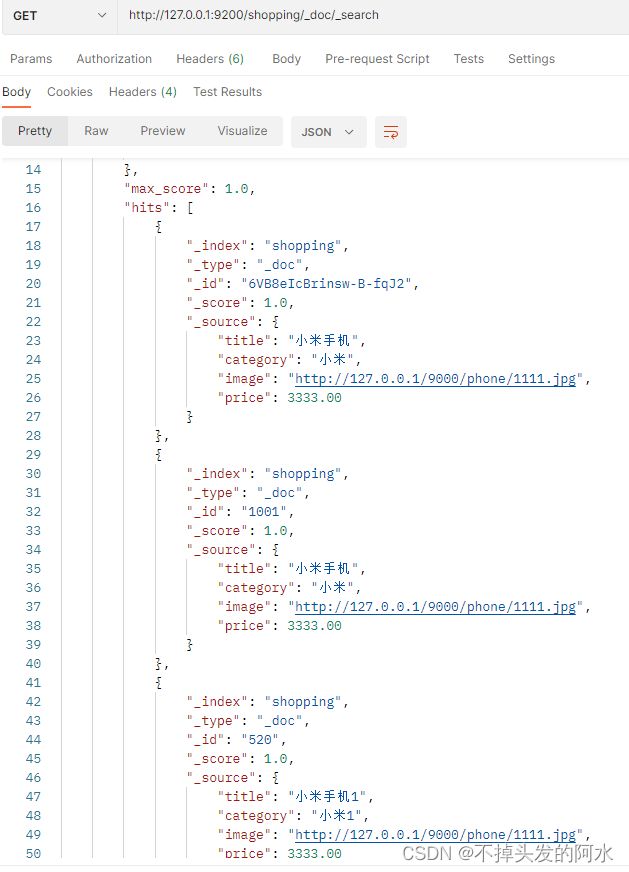
查询索引下所有文档数据,向ES服务器发送GET 请求:
http://127.0.0.1:9200/shopping/_doc/_search
4.2.3 删除索引
向ES服务器发送DELETE请求:
http://127.0.0.1:9200/shopping/_doc/6VB8eIcBrinsw-B-fqJ2
