云计算大数据之 Kafka集群搭建
云计算大数据之 Kafka集群搭建
版权声明:
本文为博主学习整理原创文章,如有不正之处请多多指教。
未经博主允许不得转载。https://blog.csdn.net/qq_42595261/article/details/83376616
Kafka简介
kafka是最初由Linkedin公司开发,使用Scala语言编写,Kafka是一个分布式、分区的、多副本的、多订阅者的日志系统(分布式MQ系统),可以用于web/nginx日志,搜索日志,监控日志,访问日志等等。
kafka目前支持多种客户端语言:java,python,c++,php等等。
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
Kafka好处
可靠性 - Kafka是分布式,分区,复制和容错的。
可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
Kafka非常快,并保证零停机和零数据丢失。
KafKa架构
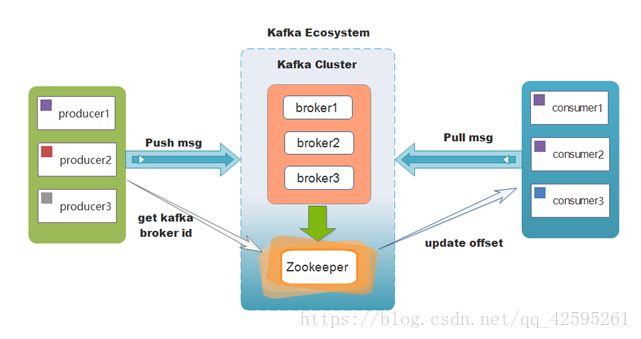
Kafka支持消息持久化,消费端为拉模型,消费状态和订阅关系由客户端端负责维护,消息消费完后不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
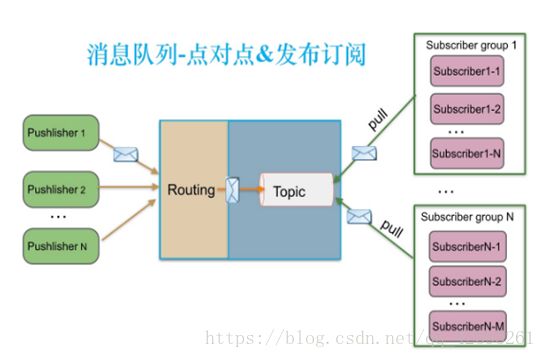
Kafka名词
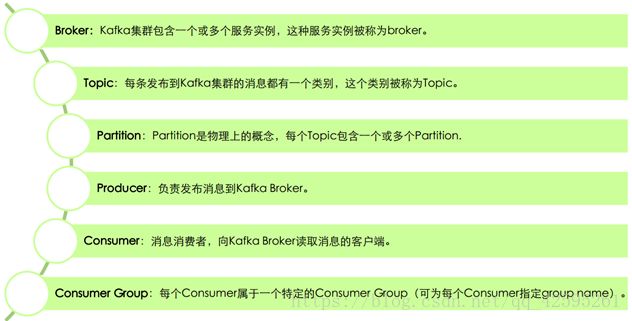
Kafka核心组件:Replications、Partitions 和Leaders
副本(Replications):Kafka允许用户为每个topic设置副本数量,副本数量决定了有几个broker来存放写入的数据。如果你的副本数量设置为3,那么一份数据就会被存放在3台不同的机器上,那么就允许有2个机器失败。一般推荐副本数量至少为2,这样就可以保证增减、重启机器时不会影响到数据消费。如果对数据持久化有更高的要求,可以把副本数量设置为3或者更多。
分区(topic):Kafka中的topic是以partition的形式存放的,每一个topic都可以设置它的partition数量,Partition的数量决定了组成topic的log的数量。Producer在生产数据时,会按照一定规则(这个规则是可以自定义的)把消息发布到topic的各个partition中。
Leader:上面将的副本都是以partition为单位的,不过只有一个partition的副本会被选举成leader作为读写用。
关于如何设置partition值需要考虑的因素。一个partition只能被一个消费者消费(一个消费者可以同时消费多个partition),因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于同时运行的consumer的数量。另外一方面,建议partition的数量大于集群broker的数量,这样leader partition就可以均匀的分布在各个broker中,最终使得集群负载均衡。在Cloudera,每个topic都有上百个partition。需要注意的是,kafka需要为每个partition分配一些内存来缓存消息数据,如果partition数量越大,就要为kafka分配更大的heap space。
Kafka的topic&parititions:
消息发送时都被发送到一个topic,其本质就是一个目录,而topic由是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
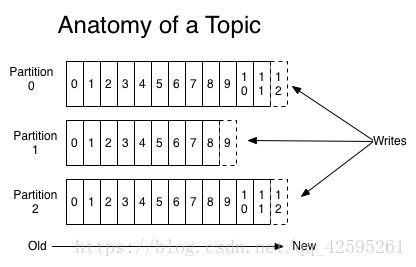
我们可以看到,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
Kafka集群会保存所有的消息,不管消息有没有被消费;我们可以设定消息的过期时间,只有过期的数据才会被自动清除以释放磁盘空间。比如我们设置消息过期时间为2天,那么这2天内的所有消息都会被保存到集群中,数据只有超过了两天才会被清除。
Kafka需要维持的元数据只有一个–消费消息在Partition中的offset值,Consumer每消费一个消息,offset就会加1。其实消息的状态完全是由Consumer控制的,Consumer可以跟踪和重设这个offset值,这样的话Consumer就可以读取任意位置的消息。
把消息日志以Partition的形式存放有多重考虑,第一,方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;第二就是可以提高并发,因为可以以Partition为单位读写了。
KafKa单机版安装
1、解压zookeeper、kafka,配置环境变量(这里不做过多演示)
2、启动zookeeper、kafka(笔者安装在/usr/local/apps路径下)
启动zookeeper服务-自带的不需要安装
nohup zookeeper-server-start.sh /usr/local/apps/kafka_2.11-0.10.0.1/config/zookeeper.properties &
启动kafka的服务
nohup kafka-server-start.sh /usr/local/apps/kafka_2.11-0.10.0.1/config/server.properties &
测试:
由一个用户来生产数据。
让另一个用户来消费数据。
事先得有一个主题(因为所有的消费都必须存在一个主题)
如何创建一个主题(topic)
kafka-topics.sh --create --zookeeper localhost:2181 --topic mytopic --partitions 1 --replication-factor 1
解释:
--create指对topic的操作。如删除、创建、修改等等
--zookeeper指kafka和zookeeper关联的地址
--topic创建主题名字
--partitions该主题下的分区数
--replication-factor指的是该主题下的复本数
生成数据
kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic
消费数据
kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic
--from-beginning:如果没有加该参数,表示只读取最新的数据的, 如果加上了。将会从kafka中历史的第一条数据读取
Kafka集群搭建
1、上传 kafka 软件,并解压(命令如下):
tar -zxvf kafka_2.11-0.10.0.1.tgz
2、配 置 环 境 变 量 (配置过程不做过多操作)
vi /etc/profile
source /etc/profile
3、进入config目录下
cd config/
vi server.properties
修改默认分区

配置zookeeper端口(“keduo”为每台节点的名字,“2181”为端口, 有多少台就添加多少台)
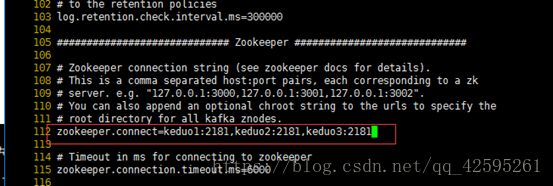
把keduo1的broke id修改成1,keduo2的修改成2,keduo3的修改成3(第一台为1,依次对应添加)
返回到keduox界面将keduo1的东西发送到Keduo2,和keduo3
scp -r kafka_2.11-0.10.0.1 root@keduo2:`pwd`/
scp -r kafka_2.11-0.10.0.1 root@keduo3:`pwd`/
然后进入keduo2中的kafka的config目录下
vi server.properties

然后将/etc/profile发送到keduo2和keduo3
scp /etc/profile root@keduo2:/etc/profile
scp /etc/profile root@keduo3:/etc/profile
然后统一生效环境变量
source /etc/profile
启动过程
先开启zkServer.sh start
然后查看是否开启zkServer.sh status
进入kafka的config,对所有主机启动kafka(启动命令如下)
nohup kafka-server-start.sh /usr/local/apps/kafka_2.11-0.10.0.1/config/server.properties &
然后查看进程(jps)
然后随便一台主机通过创建主题测试是否成功
由于不知道谁是Leader,所有三个主机都加上
kafka-topics.sh --create --zookeeper 10.32.24.X:2181,10.32.24.X:2181,10.32.24.X:2181 --topic mytopic1 --partitions 3 --replication-factor 3
然后一台主机做生产这一台消费者进行写入数据测试
kafka-console-producer.sh --broker-list 10.32.24.X:9092,10.32.24.X:9092,10.32.24.X:9092 --topic mytopic1
kafka-console-consumer.sh --zookeeper 10.32.24.X:2181,10.32.24.X:2181,10.32.24.X:2181 --topic mytopic1