腾讯云Kafka海量服务自动化运营实践
腾讯云CKafka是基于Apache Kafka 的分布式、高可扩展以及高吞吐的云端Kafka服务。腾讯云CKafka针对开源Kafka进行了多种优化,其中包括无锁队列优化、异步刷盘优化、多版本支持以及GC优化等优化手段,对开源Kafka性能达到了数倍的提高。与用户自己部署Kafka相比,腾讯云CKafka无需用户关心Kafka集群细节,用户无需维护Kafka集群直接使用,同时为用户提供丰富的监控指标。由于腾讯云CKafka与社区Kafka的协议一致,用户只需要够买实例后便可无缝接入。再者,CKafka允许用户动态进行实例的升降配,按需付费。最后腾讯云CKafka与腾讯云存储以及大数据EMR套件打通,使用方便。
当前腾讯云CKafka运行规模已经达到了日消息万亿的级别,同时日吞吐量已经达到了PB级别,单集群最高峰值可达数十亿。
在运营云端CKafka不同集群以及如此繁多的节点时候,我们遇到了的问题可以归纳为以下几点:
1)如何选择云端CKafka版本
2)如何合理的创建分配实例才能实现资源的有效利用
3)怎样实现实例动态升降配
4)如何实现集群的负载均衡
5)怎样合理规划分区的创建、新增以及迁移
下文就针对这五个问题分别阐述腾讯云CKafka是如何解决的。
多版本生产/消费兼容
由于云端面对的用户不同,必然会出现对Kafka不同版本的要求。当前最新Kafka版本已经为1.1.0版本,对于底层存储而言,主要是不同版本会有不同的消息格式。

图1. 用户版本的选择
第一种方案是部署多套Kafka集群以满足不同版本的要求,但是这种做法的代价是每当用户购买实例的时候必须提供其使用版本,同时用户必须持续使用这种Kafka版本。否则只能通过重新购买不同版本的实例才可以实现版本的替换。其次在运维过程中,由于每个节点有版本号的特异性,不同版本的节点不允许加入非对应版本的集群。在集群节点调度时不再对集群透明,所以在后续对集群维护的时候也增加了维护成本。
第二种方法也是目前CKafka使用的方法,改造Kafka底层以完成多种消息格式的存储。底层不再拒绝不同版本的消息,根据magic字段获取消息的格式进行相应处理。在不同版本之间的生产/消费进行消息的转换以满足要求。这样用户即使使用不同版本也可以在同一个实例下完成,集群调度也不会有节点特异性的问题。
提高资源利用率
伴随着服务的运营以及越来越多的实例售卖,后端发现集群出现了资源浪费的情况。由于CKafka是按照实例进行售卖,实例售卖又具有两个纬度,分别为带宽与磁盘。每个实例的服务能力会分布在不同节点上,不合理的资源分配将会造成两种资源的浪费。
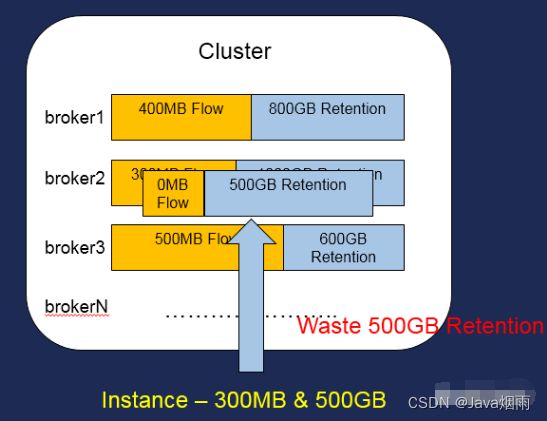
图2. 实例分配浪费场景
CKafka目前采用类似装箱算法的方式进行实例分配,根据不同情况计算每次分配的权值,尽力保证每次的带宽售卖与磁盘的售卖比例保持在1:1的状态,选择合理的分配方式进行分配。分配分为以下3种情况:
a) 本次分配后,剩余的容量不足以进行一个最小实例的售卖,这种情况需要对计算结果进行降权处理。
b) 本次分配后,剩余的资源恰好足够一个最小实例的售卖,这种情况属于理想情况,我们赋予一个较大的常数权值。
c) 本次分配后,如果不属于上述两种情况,则采用带宽售卖比例与磁盘售卖比例的比值作为权值计算参数计算权值。
根据上述三种情况进行节点的选择,达到两种资源售卖的相对均衡。
用户动态升降配
在用户使用CKafka的初期往往会购买一个相对较小的实例进行功能性测试,在完成功能性测试之后会希望进行实例升级以达到生产环境的标准。实例的升降配分为两种情况:其一是实例所在的机器有足够的资源完成本次升级要求,这种情况在节点上直接扣除资源可以完成升级操作。第二种情况是当前实例所在机器资源不足以完成本次实例升级,需要进行实例的迁移才可以完成实例升级。
这种情况下,我们会根据迁移后的服务节点数量生成多种迁移方案,每种方案下迁移的代价是不同的。当从少数机器迁移往多数机器时,每个机器所需要的服务能力会更小。迁移的时候,我们第一步会计算每种迁移方案下,应该选择的节点。这个节点的选择由我们前面提到的权值计算方式得出。
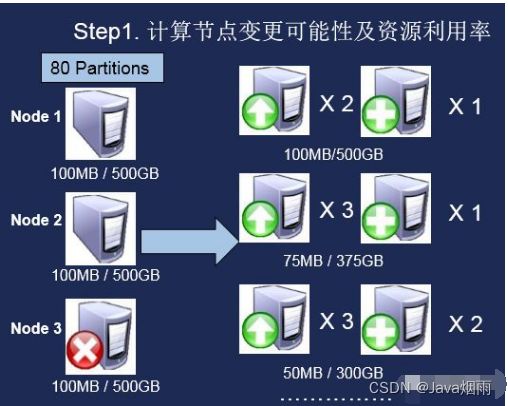
图3.迁移方案计算
得到所有迁移方案后,我们会开始计算每种方案的迁移代价,然后按照迁移代价最小的迁移方式进行实例的迁移。迁移完毕后就可以完成实例的升级,当前迁移主要考虑的指标为迁移的Partition的落盘数据大小,Partition迁移的数量为该实例所有Partition平均分布在服务其节点上的一个平均值。这里需要注意的是迁移过程分步迁移,从数据量小的Partition开始迁移,这样可以保证整个迁移过程相对可控,同时也能便于迁移的回滚。
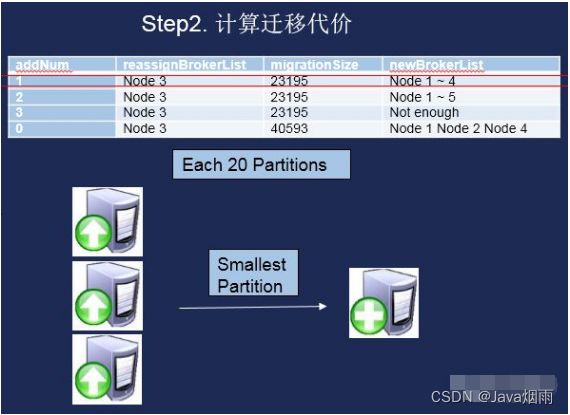
图4.迁移代价计算
集群的负载均衡
对于一个CKafka集群,生产过程中避免不了对集群中节点的新增以及减少,我们在如下几种情况会考虑增加一个集群中的节点:
1)实例能力的扩展
当集群中剩余的资源不足以进行新的实例创建或者不足支持实例的升级时,我们会在集群中添加机器增加资源,支持后续的售卖以及实例迁移扩容。
2)节点资源碎片的整理
当节点存在资源碎片的时候,可以通过新增机器,将部分现有的机器上的实例进行迁移,对剩余的资源碎片进行重新整合以满足售卖要求。
3)集群节点间的机器负载均衡
当集群的机器某些资源消耗达到设置的阈值时,通过增加机器对现有实例进行迁移。降低整个集群中的节点负载。
在以下情况我们会对集群中节点进行移除:
1)实例的缩容
当用户购买实例后发现,实例的服务能力大于自己所需要能力时,这时候需要对实例进行缩容,有些缩容会将Partition迁移到更少的机器上。当缩容后发现某些节点已经不存在服务的实例了。这时候我们会进行节点移除减少成本。
2)节点异常
生产过程中避免不了节点的硬件异常情况,这种时候我们会将服务在该节点上的实例进行一个实例的迁移然后下架机器。
分区管理 - 创建、新增、迁移
前面提到的所有操作,都离不开最基本的Partition操作。对于CKafka运营过程中,会从整个Partition的生命周期入手进行管理。
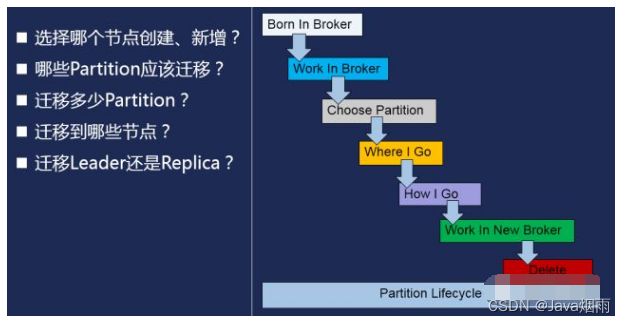
图5.Partition的迁移选择
1)分区的创建:
对于每个实例的Partition新增,我们都会优先选择该实例后端对应服务器上Partition最少的节点进行创建。这样可以避免分区不均匀情况。即使每次实例创建Partition的时候都只创建少量Partition,也能保证分配到Partition最少的机器上。
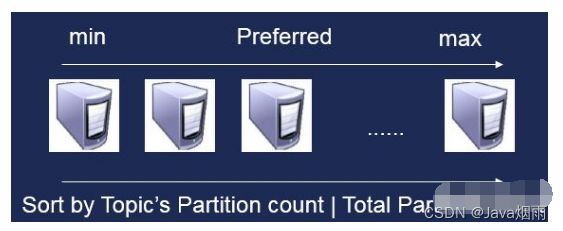
图6.Partition的创建选择
1)分区的迁移:
a)迁移的目的
由于分区的迁移在消息量大的情况下代价也是巨大的,所以每次迁移前必须考虑这个迁移是否必要的,是否可以不迁移来解决当前问题。当前我们迁移主要为了解决以下几种问题:服务异常,这种情况必须迁移实例下的Partition,否则后续服务可能会受到影响;实例扩缩容,这种情况下必须迁移实例部分Partition,否则无法满足用户升级的需求;负载均衡,这种不属于必须的迁移。即使不迁移也能保证集群工作,只不过迁移后集群会在一个更健康的环境下工作。
b)迁移的方式
Leader迁移:这种迁移涉及Partition的角色切换,这种迁移的代价较Replica迁移偏小。角色切换后,新节点的CPU以及网卡出流量会增加。这是因为压缩和解压缩的操作只会存在于Partition节点,同时Partition的消费只会发生在Leader节点上。
关于Leader迁移主要考虑两点:Leader的分布以及Leader的网络出流量。迁移的第一步会优先计算出Leader应该迁移的个数以及迁移的目的地,个数是根据Leader的数量以及Broker的数量求平均值计算出来,从Leader数目多的节点迁往Leader数目少的节点。再者会考虑每个Partition的Leader出流量,优先将出流量多的Partition和出流量少的Partition进行组合分配。这样就可以达到一个相对均衡的分配状态。
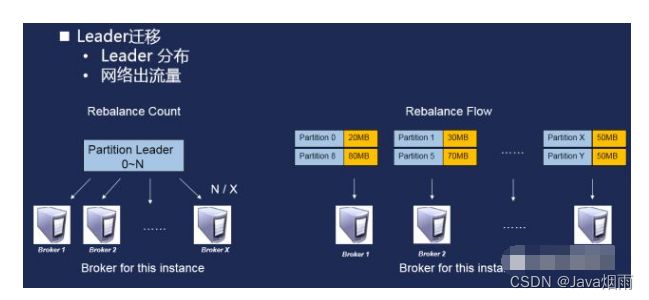
图7. Leader迁移方式
Replica迁移:这种迁移涉及Partition的数据搬迁,这种迁移的代价较大。涉及数据的全量转移,在数据量大的时候往往导致迁移时间过久。其次每次迁移将会占用新机器上一个Partition所应该占用的所有资源。
关于Replica的迁移主要考虑两点:迁移后节点的利用率以及数据迁移的代价 。在迁移前第一步先计算迁移Partition的数量,我们希望Partition尽量平均分布在 服务其的所有节点上。根据迁移后一个实例可能占用节点的数量不同生成多种迁移方案,同时根据装箱售卖权值计算出哪些节点是符合本次迁移目的地候选的。接下来考虑每种迁移方案的代价,这里主要考虑的是迁移的数据总量,优先选择数据迁移少的迁移方案进行Replica的迁移操作。

图8. Replica迁移方式
自动化控制中心架构
为了满足日常运维指标以及告警的实际需求,以及自动化调度功能实现,整个自动化控制中心架构的实现如下:
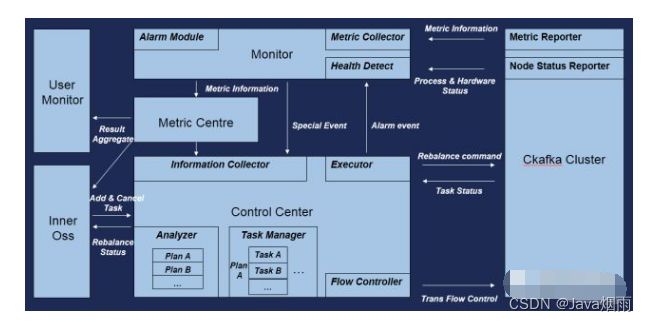
图9. CKafka控制中心架构图
-
CKafka Cluster
CKafka针对底层不同消息格式进行了分析处理,允许不同版本生产者与消费者之间交叉使用。CKafka会对这些不同版本做兼容以及转换,对于用户完全透明。集群负责上报两大类数据,第一种是生产/消费过程中的监控数据,此处具体到每个Partition级别,涵盖Partition的生产/消费以及数据堆积等情况,Consumer Group消费进度。第二种是相对偏向硬件负载的机器信息,比如机器的CPU、内存、IO以及网卡流量等信息,同时还会监控进程的存活情况。
-
Monitor
负责收集CKafka上报的数据,对于生产/消费过程中的监控数据进行数据的汇总。汇聚成节点、集群等多纬度的数据供日常监控。同时进行Barad数据的上报,在Barad上根据实例、Topic纬度进行汇总。当遇到节点异常时进行异常告警,同时通知控制中心进行节点实例迁移调度。在节点异常的情况下需要对于节点上所有服务的Partition进行全量迁移。
-
Metric Center
当前是采用Barad做数据汇总,将数据根据多维度聚合展示给用户。用户前端控制台可以针对多种指标进行告警设置。
-
Inner OSS
运营控制台处可以感知到当前集群所有实例分配情况,当实例创建时由OSS进行整个创建操作。若出现资源不足的情况下,OSS会通知管控中心进行集群中资源的整合或者进行实例迁移,当迁移完毕后完成相关请求工作。同时OSS也可以手动触发/取消迁移调度操作,每个迁移操作进度也能从此处得知。
-
Control Center
管控中心主要根据不同事件进行不同的调度处理:
1)根据上报信息确认是否需要进行均衡调度,如果超过指定的阈值条件则触发集群负载均衡;
2)集群资源需要进行整理或资源不足以完成实例升配,此时进行合理的实例迁移,完成资源整合或者转移相关资源达成目标;
3)节点异常事件,此时遍历此节点上存在的所有实例资源,进行实例迁移保证后续服务。
调度过程由Analyzer模块进行方案的生成,方案主要根据后端服务节点不同而确定,并且根据不同的触发条件计算迁移代价确定最优方案。 当Analyzer模块生成最佳方案后,每个方案又会分解成多个小任务进行执行,这是因为这样可以保证迁移过程任务相对独立便于取消,同时如果需要回滚那么过程相对可控,其次这样在迁移过程中对现有节点上的用户服务影响最小。这些细粒度任务由Task Manager模块进行管理,Task Manager模块会将任务进行存储以便后续查看操作记录以及进行任务回滚。为了保证不对现有服务造成冲级,管控系统增加Flow Control模块动态的针对流量进行控制,根据迁移的实例规格以及迁移目标节点的负载,对迁移的流量进行合理分配,防止迁移过程造成对现有用户的影响。
小结
针对CKafka的Broker节点底层改造以及利用自动化控制中心对迁移的合理管控,有效解决CKafka运营过程中遇到的实例分配、升降配、迁移以及集群负载均衡调度等一系列问题,为海量节点运营提供了自动化运营手段。对于当前调度方案还有不足的地方:首先希望能够从更多的纬度去进行调度管理,比如CPU/内存/IO等。其次当前调度是基于已经发生异常的情况下才会进行调度工作,后续希望通过集群负载、资源占用以及实例增长量对集群的负载趋势做预判,提前完成迁移以及均衡。
如果本文对你有帮助,别忘记给我个3连 ,点赞,转发,评论,
咱们下期见!答案获取方式:已赞 已评 已关~
学习更多JAVA知识与技巧,关注与私信博主(03)
