【创作赢红包】Java Web 实战 18 - 计算机网络之网络层协议 and 数据链路层协议
文章目录
- 网络层协议
-
- 1. IP 协议
-
- 1.1 报头结构
- 1.2 IP 协议的地址管理
-
- 动态分配 IP 地址 (DHCP)
- IP 地址转换 (NAT)
- IPv6
- 1.3 IP 地址的组成
- 2. 路由选择
- 数据链路层
-
- 1. 以太网协议
- 2. 以太网帧格式
-
- 2.1 mac 地址
- 2.2 两个特殊的以太网数据帧
- DNS 域名解析系统
- 六 . 经典面试题 : 从浏览器中输入 URL 开始 , 到最终看到页面 , 中间都发生了哪些事情 ?
大家好 , 这篇文章继续给大家讲解网络层协议以及数据链路层协议的相关内容 , 还会给大家带来一道景点面试题 - 从浏览器中输入 URL 开始 , 到最终看到页面 , 中间都发生了哪些事情 ?
大家准备好 , 我们要发车啦~

网络层协议
网络层协议的工作主要是两方面 :
- 地址管理
- 路由选择 (规划路径)
在网络层中 , 最核心的协议就是 IP 协议
在传输层中 , 最主要的协议就是 TCP 协议
在网络层中 , 最主要的协议就是 IP 协议
故我们把整个网络协议栈叫做 TCP-IP 协议栈
都被冠名了 , 那肯定是非常重要
1. IP 协议
1.1 报头结构
1.2 IP 协议的地址管理
IP 地址能够保证唯一吗 ? 能否给每个主机都分配一个唯一的 IP 地址呢 ?
并不能 , 32 位的数字 , 表示的范围是 42 亿 9 千万
那目前全球的上网的设备数量已经远远超过了 42 亿 9 千万 , 所以 32位 的 IP 地址已经远远不够用了
那如何解决 IP 地址不够用的问题呢 ?
动态分配 IP 地址 (DHCP)
需要上网的设备就分配 , 不上网就不分配
这个方法治标不治本 , 但是现在还在沿用
IP 地址会变的 , 就是因为 DHCP
IP 地址转换 (NAT)
把 IP 地址分成两个大类
- 内网 IP (局域网里面使用的 IP) : 不同局域网之间的内网 IP 可以重复
- 外网IP (广域网里面使用的 IP) : 但是要保证外网 IP 要保持唯一
同一个局域网中的 IP 地址不能相同 , 但是不同局域网里面的 IP 允许重复
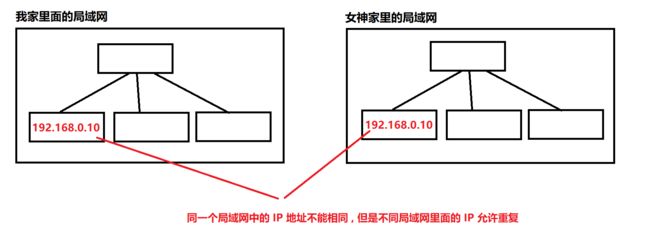
但是如果 IP 地址重复了 , 一个包裹应该传给谁呢 ?
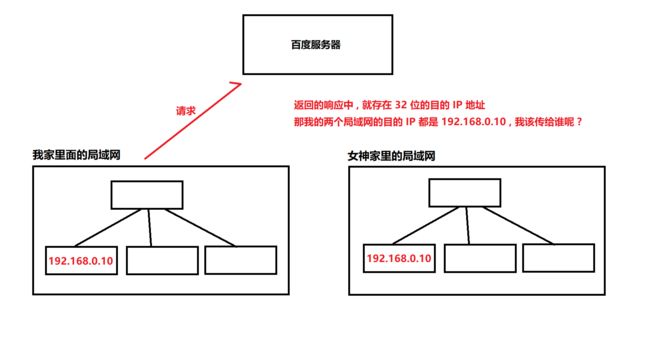
为了进行区分 , 我们想了个办法
(图片描述的是一个简化的版本 , 中间的每一个设备都会对 IP 地址进行转换的)
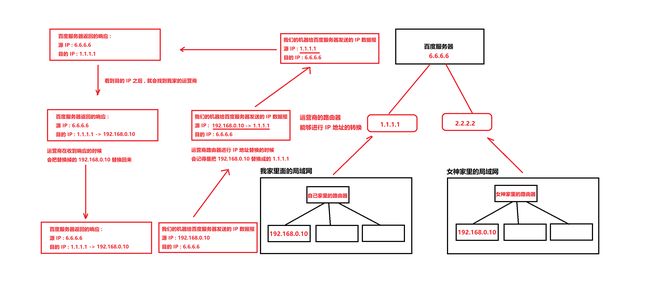
这就是 NAT 机制 , 本质就是用一个外网 IP 代表一大批内网的设备
当前世界的现状 , 就是 DHCP(动态分配 IP 地址) + NAT (IP 地址的替换) , 这就保证了不同设备的 IP 地址不同
约定内网 IP 有三类 :
- 10.*
- 172.16.* - 172.31.*
- 192.168.*
其他的就是外网 IP 了
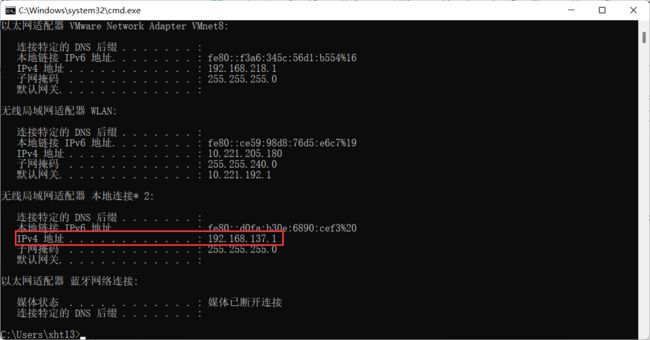
在 cmd 中 , 输入 ipconfig 就可以看到我们电脑在局域网中的 IP 地址了
IPv6
lPv6 是解决 IP 不够用问题的终极方案
lPv6 相当于是另一个网络层的协议 , 和 IPv4 可以视为是完全不同的两个协议 , 而不是 IPv4 的升级版
IPv6 使用 16 字节(128 位) 这样的值表示 IP 地址了 , 而 IPv4 是 4 个字节的
IPv6 的恐怖之处就在于给地球上的每一粒沙子都分配一个 IPv6 地址都是绰绰有余的
但是这里有一个很大的问题 : IPv6 和 IPv4 是不兼容的
现存的支持 IPv4 的网络设备 (路由器 , 网卡 , 交换机 …) 不一定支持 IPv6
1.3 IP 地址的组成
IP 地址 , 是一个四个字节的整数 .
为了更好的进行组网 , 对于这个 IP 又做出了一些更详细的划分
把一个 IP 分成两段 : 前一半叫做网络号 , 后一半叫做主机号
网络号用来表示当前局域网 , 主机号用来区分当前局域网当中的每一台主机
具体的分发还有不同的策略
分法1 : 这种方法很少见 , 主要就是存在于教科书中 (太奢侈了)
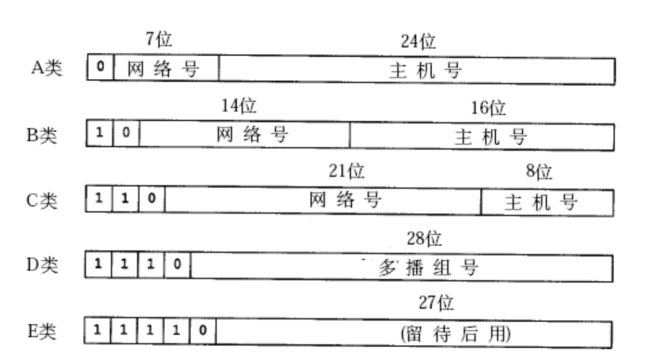
分法2 : 现在主流的划分方式 -> CIDR , 引入了子网掩码来区分 , 哪个部分是网络号 , 哪个部分是主机号
子网掩码也是一个 32 位的整数
左侧都是 1 , 右侧都是 0
子网掩码通常都是这个样子的 : 255.255.255.0
前三个字节都是全 1 , 最后一个字节都是 0 , 标记为 1 的部分就表示了这部分 IP 是网络号
我们的 网络号 可以理解为是子网掩码和 IP 地址进行了按位与操作
255.255.255.0
192.168.0.10 &
-------------------------
192.168.0.0 -> 网络号
我们要求 :
同一个局域网内部 , 设备之间的网络号 , 都是一样的 , 主机号是不同的
两个相邻的局域网 , 网络号是不同的.
相邻的局域网 : 同一个路由器连接的两个局域网
比如 :
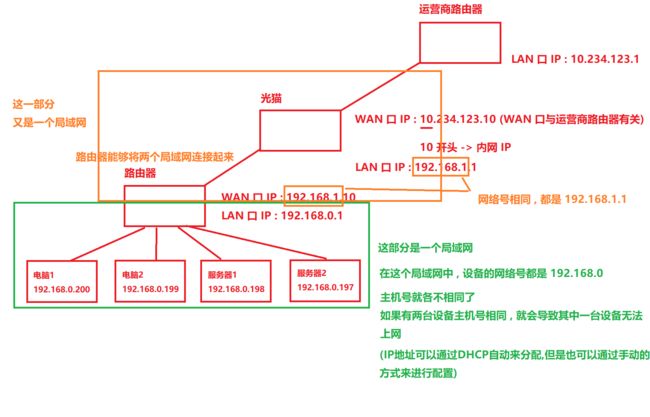
在这里面 , 有两个特殊的网络号
192.168.0.1 / 192.168.1.1
主机号为 .1 的 IP , 通常来作为 “网关”
网关指的就是入口出口
192.168.0.0 / 192.168.1.0
主机号为 .0 的 IP 也就是网络号 (表示当前局域网 / 网段)
192.168.0.255 / 192.168.1.255
主机号为 .255 的 IP 是广播 IP
我往 192.168.0.255 这个 IP 地址上发送数据报 , 此时整个 192.168.0 这个局域网中的所有设备 , 都会收到这个包
UDP 实现广播就可以搭配这个广播 IP
127.0.0.1 / 127.* 表示环回 IP , 表示主机自己
以上知识作为常识了解即可 , 面试不太常见
2. 路由选择
路由选择就和地图寻路差不多
比如说 : 我想从北京大学到中国人民大学 , 就有很多种路线
在路线规划的过程中 , 就是路由选择
路由器上进行路径规划的时候 , 没有那么多空间来保存全局的信息的
全局信息指的就是具体有多少条路径 , 每条路径都是怎么走的
路由器的配置是很低的 , 每个路由器只能知道位置信息的一部分
例如 : 路由器 , 能够知道和他相邻的一些设备 , 怎么走 , 或者最多可以知道 相邻的 相邻的 设备怎么走
路由器这里的数据转发就类似于原始的寻路方式 : “问路”
根据地图 , 知道了大概的方向 , 之后就可以不断的问路
每个人都知道的位置是有限的 , 但是每个人都有自己熟悉的区域 , 他可以告诉你一个大概的方向
经历了一系列的问路 , 就会非常接近目的地了
每次问路 , 就相当于经历了一次 “路由转发”
每个人脑子里记住的一些位置信息 , 称为 “路由表”
问路的时候 , 要去的中国人民大学 , 就是 目的IP
路由器就会根据目的 IP 在路由表中匹配 , 看能不能匹配到 . (按照网段的方式匹配的)
如果匹配到了,就会按照指定的方向继续往下转发.
如果没有匹配到 , 会有一个默认的方向 (叫做下一跳地址 , 这是路由表中的默认选项)
路由转发基本过程类似于 “问路” -> 一跳一跳(hop by hop)进行转发的~
这些都是属于工作用不到 , 面试不会考的东西
主要目标还是了解一些 IP 协议常识性东西即可
数据链路层
1. 以太网协议
以太网协议就是插网线的协议
平时插的网线 , 也叫 “以太网线”
2. 以太网帧格式
2.1 mac 地址
我们之前介绍过 , 数据链路层是负责两个相邻节点之间的路径规划的
网络层是负责两个点之间的路径规划的
那一般情况下 , 数据链路层的源 mac 和目的 mac 是会经常变化的 , 而网络层的源 IP 和 目的 IP 一般是不会变化的
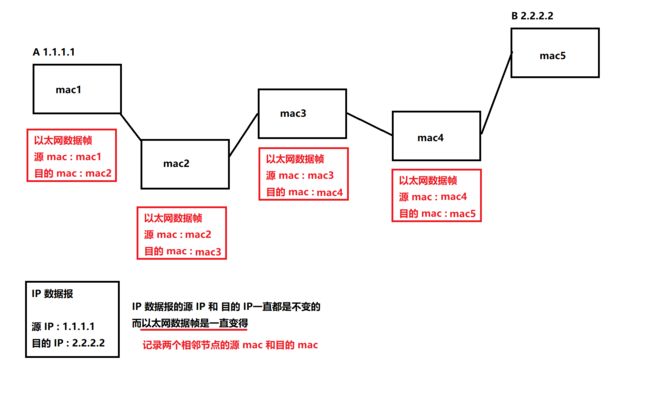
2.2 两个特殊的以太网数据帧

我们需要重点关注应用层和传输层
了解网络层和数据链路层即可
DNS 域名解析系统
DNS (“域名解析”) 是应用层的协议 , 他的用途是很大的
域名其实就是网址 , 域名是为了简化 IP 地址的书写的
IP 地址 , 虽然写成了点分十进制 , 更方便理解了 . 但是仍然不是特别的直观 !
为了进一步的简化对于 IP 的理解 , 方便传播 , 就引入了 “域名”
使用域名还有其他好处
域名可以通过 DNS 系统自动转换成对应的 IP 地址 . 如果未来 IP 地址有变化 , 比如机器迁移了 , 用户还是可以正常访问的
比如说 外网 IP 更换了 , 通过域名解析系统 , 用户不用考虑 IP 地址是否变化都可以正常访问
那 DNS 如何完成转换的呢 ?
最早的 DNS 系统 , 是一个文件 , 称为 hosts 文件 .
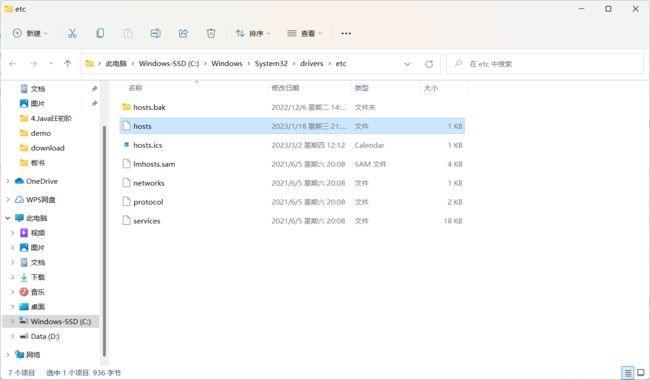
这个文件就是一个最早的域名解析系统 , 我们可以打开看一下
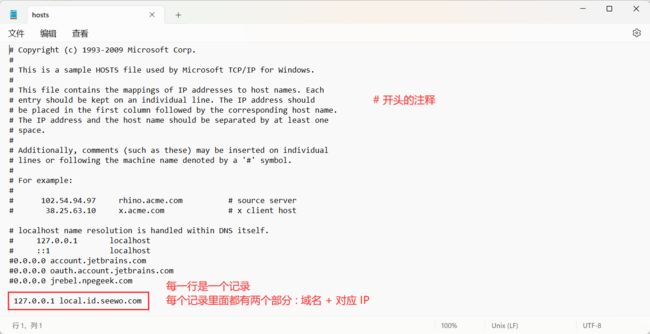
这个方式比较的原始 , 现在基本上都不用了
但是他还好使 , 还是生效的
因此 , 我们更科学的办法 , 就是使用专门的 DNS 服务器 , 来保存这个文件
使用服务器把这些映射关系都存储好 , 哪个电脑需要 DNS 解析 , 就访问这个 DNS 服务器即可
但是全世界要上网的设备也非常多 , 每个设备上网的时候都要请求 DNS 服务器 , 那 DNS 服务器能够扛得住这么大的请求量吗 ?
每个服务器 , 在给客户端提供服务的时候 , 都需要消耗一定的硬件资源 (比如 : CPU / 内存 / 网络带宽…) , 并且每个服务器能提供的硬件资源是有上限的
那如何解决 DNS 服务器访问量太高的问题呢 ?
- 主机在请求 DNS 之后 , 会对映射关系在本地进行缓存
域名 -> IP 这个映射关系 , 虽然会变 , 但是频率比较低 , 我们就可以对这个映射关系进行缓存
这就可以大大的减少客户端访问 DNS 服务器请求的数量
- 在全世界 , 架设很多的 DNS 镜像服务器
最初的 DNS 服务器 , 称为 “根服务器”
其他的 DNS 服务器 , 从根服务器上同步数据 , 叫做 “镜像服务器”
镜像服务器在世界上非常非常多 , 一般各种大的网络运营商都会在自己业务的各个片区里面去部署镜像服务器
DNS 既是一个协议 , 也是一套系统 (分布式的服务器系统)
咱们的电脑要想能够正确上网 , 就需要配置好使用的 DNS 服务器 .
一般来说 DNS 服务器的地址都是自动获取到的 , 当然也可以手动配置
你如果是自动获取 , 那你获取到的地区级别的 DNS 服务器 , 有可能会挂了(挺常见的)
比如 : 电脑能使用 QQ , 但是不能打开网页 , 十有八九就是 DNS 服务器挂了
因为打开网页需要针对域名进行解析 , 解析不了就自然无法访问了
但是 QQ 是直接使用 IP 地址和 QQ 的服务器进行交互的 , 他不涉及 DNS 之间的转换
六 . 经典面试题 : 从浏览器中输入 URL 开始 , 到最终看到页面 , 中间都发生了哪些事情 ?
可以参考这篇文章 : 输入 URL 之后的流程
- 浏览器是客户端 , 在这里输入 URL 就会访问对应的服务器
应用层的角度 :
- DNS 解析
- 构造 HTTP 请求
- 传输层的角度 : 对应到 TCP 协议 .
- 先三次握手 , 建立连接
- 传输数据 (确认应答 , 超时重传 , 滑动窗口 , 流量控制 , 拥塞控制.……)
- 网络层的角度 : 网络数据报转发过程 . (一跳一跳的方式来转发 -> 路由表,路由表匹配规则,下一跳相关内容)
- 数据链路层的角度 : 以太网数据帧 , mac 地址 , mac 在转发过程中如何变化 , MTU 以及 MTU影响到的 IP 分包.
- 物理层的角度 : 上述数据会转成 “光信号” “电信号” 进行编码、传输
- 总结 : 发送的过程中 , 涉及到从上到下 , 封装
接收方 , 涉及到从下到上的分用
上述过程是客户端给服务器发送请求的
过后面服务器还要根据请求计算响应 , 把响应按照类似的流程转发给客户端程序
上述回答 , 是站在 “后端开发” 角度来看待的问题
站在前端开发的角度 , 或者网络工程师的角度来看待 , 回答的方式仍然不同
这篇文章 , 到这里就结束了
如果有收获的话 , 请一键三连~
