Linux 内存地址分布
文章目录
- 一、背景
-
- 1.1 深入浅出了解(.text、.data、.bss、堆空间、栈空间)的含义
- 二、转载:linux 内存空间(三) 内存地址范围和例子
- 三、其他资料
一、背景
对程序内存理解只停留在栈内存、堆内存阶段,整体和系统性理解不够,这里计划系统性学习,掌握以下内容:
- Linux 程序内存分布 (硬件、内核、系统&驱动、应用)
- Linux 内核内存管理
- Linux 可执行文件格式
1.1 深入浅出了解(.text、.data、.bss、堆空间、栈空间)的含义
- 关于嵌入式系统内存地址空间的一些疑问(.text、.data、.bass、堆\栈空间)
接下来所说的是嵌入式系统的内存地址空间的布局,简单的说就是我们写好的代码,在编译过程种中,把代码里不同的变量、函数相应的保存在每个段中(.text、.data、.bss),至于堆空间、栈空间是代码在芯片上运行时才存在的。
- text:代码段。包含了操作系统和应用程序的所有代码。
- data:数据段。存放了操作系统和应用程序当中所有带有初始值且不为零的全局变量。
- bss:bss段。存放了操作系统和应用程序当中所有未带初始化或者初始化为0的全局变量。
- 堆空间:动态分配的内存空间。在系统运行时,可以通过malloc/free之类的函数来申请或者释放一段连续的内存空间
- 栈空间:保存运行上下文以及函数调用时的局部变量和形参。
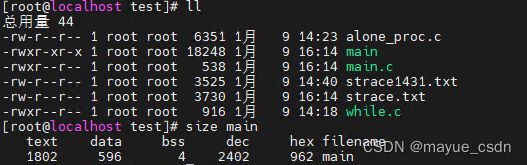
bss段中的值全部赋为了0。程序中就不存在没有初始化的全局变量了,你不初始化,bss段也会帮你初始化为0。
size a.out
![]()
查看ELF文件包含哪些:变量、函数、文件、依赖哪些动态库,相关命令如下:
readelf -S app
objdump -f app
objdump -h app
objdump -s app
file app
nm app
参考资料:
- linux 查看动态库/程序依赖的库
- linux 查看静态库和动态库定义了有哪些函数
- linux 查看静态库和动态库定义了哪些变量
- Linux查看静态库/动态库定义的函数,以及查找函数对应的静态库/动态库
二、转载:linux 内存空间(三) 内存地址范围和例子
- 原文地址: linux 内存空间(三) 内存地址范围和例子
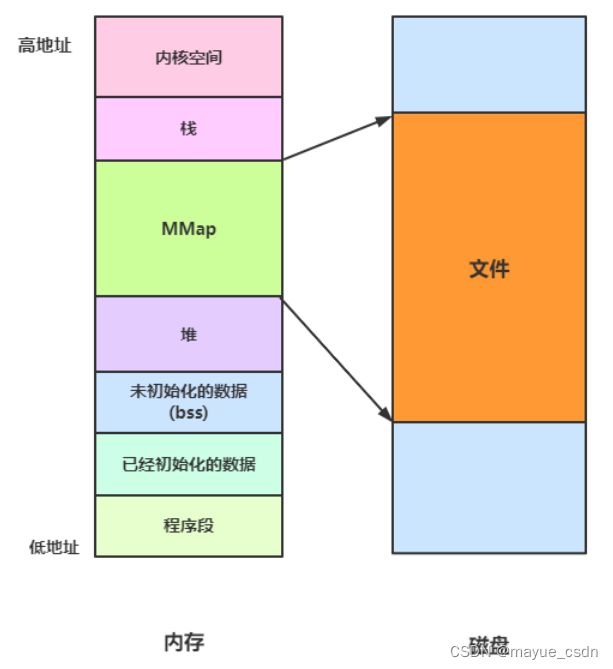
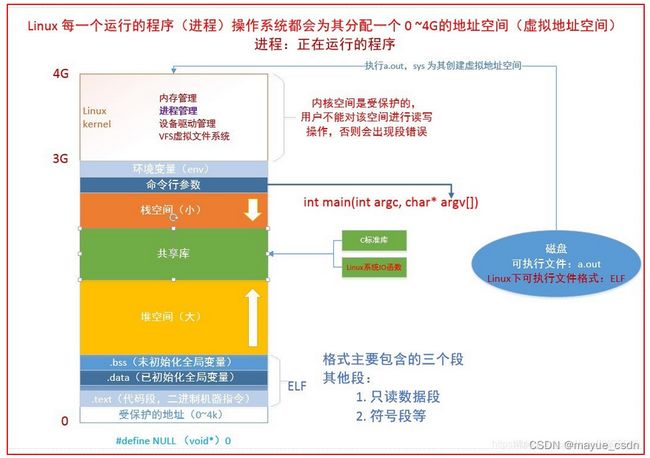
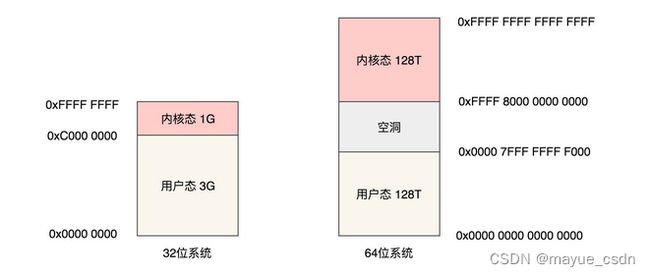
先放一张虚拟地址空间分布图(图截至深入理解计算机系统第三版):对于这张图有好多种不同的画法和呈现方式。
 |
 |
 |
 |
通过上面这几张图,我们应该清晰认识到linux中内存是如何分布的,那么这里有几点需要注意:
1:用户态在低地址,内核态在高地址。
2: 64位的系统,目前一般使用了48位。用户态高16位都是0, 内核态高16位一直是FFFF。 都用剩下的48位来表示128T。1T==102410241024*1024。 剩下的8位直接上也只用了7位, 第48位来表示是内核空间还是用户空间。加一起 48位表示的就是128T。
其中,0x0000000000000000~0x00007fffffffffff 表示用户空间, 0xFFFF800000000000~ 0xFFFFFFFFFFFFFFFF 表示内核空间,共提供 256TB(2^48) 的寻址空间。
这两个区间的特点是,第 47 位与 48~63 位相同,若这些位为 0 表示用户空间,否则表示内核空间。所以上面那个话64位的内存分布图有点问题。用户态128T的最高地址不对。
3:堆申请空间往上涨,栈申请空间往下涨,栈的地址肯定比堆的地址高。 然后栈和堆中间还有一段区域用来共享:文件映射, mmap使用。 这儿有个问题:为什么堆往上涨,而栈往下涨?
下面是几个小例子来帮助理解地址分配的:
例子1:
malloc的分配内存有两个系统调用,一个brk,一个mmap,brk是将.data的最高地址指针_edata往高地址走,mmap则是在进程的虚拟地址空间(在堆和栈之间的内存映射区域)找一块空间。这两种都是没有实际分配物理内存,只有当真正使用的时候才发生缺页中断,分配物理内存。 http://blog.yufeng.info/archives/tag/mmap上提到了通过MAP_POPULATE来实现mmap函数直接预分配物理内存的方法,这个就不展开说了。
一般情况下,我们使用malloc,如果小于128k,则使用brk分配,如果大于128k,则使用mmap在堆和栈之间找一个空闲空间分配。我们可以看看一个例子:
int main(int argc, char **argv)
{
int stackPoint = 3;
printf("the stack address:%lx",&stackPoint)
printf("begin\n");
m = malloc(64 * 1024);
getchar();
n = malloc(256 * 1024);
getchar();
printf("end\n");
free(m);
free(n);
return 0;
}
下面是strace抓取的结果:

第一步运行函数:
![]()
第一个malloc调用brk系统调用,这是/proc/56358/maps的内容如下,_edata的指针应该从0x0097a000升到了0x0099b000, heap的范围就是这个。
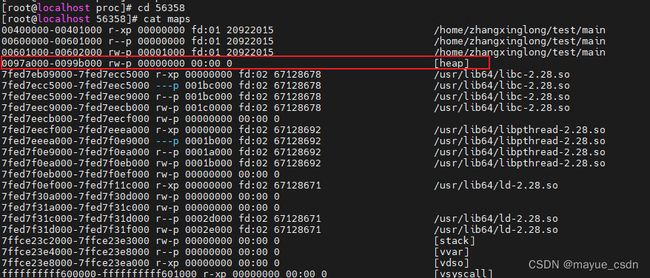
第二个malloc调用mmap系统调用,strace的内容如下:
mmap(NULL, 266240, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fed7f2c9000
第二个malloc调用mmap调用,这是/proc/56358/maps的内容如下:
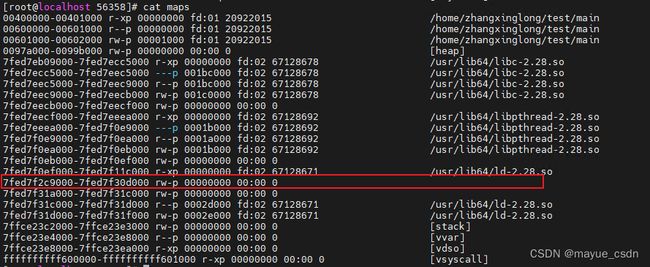
这里可以看到,分配256K时,是从高地址开始,往下分的。 也就是从7fed7f30d000往下减了266240个地址。 这个和256K有点出入,不确定为啥,先不关注。
但是我们可以看到,确实是在堆和栈的中间,从高往低分配了一段空间。将mmap分配的内存合并到内存映射区域当中。
你看最后释放的时候,从那个分配的地址开始直接释放一段很大的空间。
![]()
接着我们可以看下下面这个例子:
#include 按理说应该两次调用mmap才对,但是实际上如下:
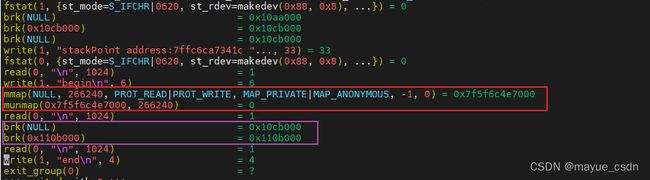
第二次调用的是brk。这是为什么?
因为M_MMAP_THRESHOLD可以动态调整。
M_MMAP_THRESHOLD是设置mmap的阈值,但是glic中 M_MMAP_THRESHOLD 是可以动态调整的( 在128KB 到 64MB之间调整 ),当申请并释放了一块大小为N KB的内存之后, , 会调整到N 到 (N + 4)KB。可以手动设置 M_MMAP_THRESHOLD的值防止动态调整(mallopt).
顺便备两篇博文:
https://blog.csdn.net/unix21/article/details/15341597
https://yq.aliyun.com/articles/26650
例子2:
我们知道,在32位机器上linux操作系统中的进程的地址空间大小是4G,其中0-3G是用户空间,3G-4G是内核空间。其实,这个4G的地址空间是不存在的,(这句话怎么理解不存在呢?想想要是64位系统,岂不是要128T了?这里说的不存在是指物理内存不一定有这么大,不一定存在。物理内存具体多大看硬件资源。) 所以我们常说的多少位系统,他的内存多大,都是说的虚拟内存空间。
那虚拟内存空间是什么呢,它与实际物理内存空间又是怎样对应的呢,为什么有了虚拟内存技术,我们就能运行比实际物理内存大的应用程序,它是怎么做到的呢?
呵呵,这一切的一切都是个迷呀,下面我们就一步一步解开心中的谜团吧! 我们来看看,当我们写好一个应用程序,编译后它都有什么东东?
其中text是放的是代码,data放的是初始化过的全局变量或静态变量,bss放的是未初始化的全局变量或静态变量
由于历史原因,C程序一直由下列几部分组成:
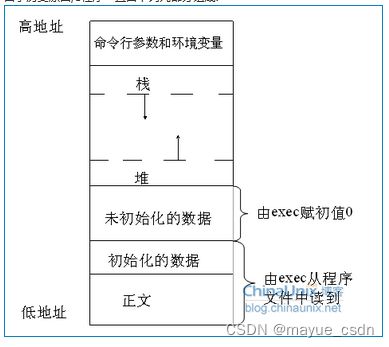
A.正文段。这是由cpu执行的机器指令部分。通常,正文段是可共享的,所以即使是经常执行的程序(如文本编辑程序、C编译程序、shell等)在存储器中也只需要有一个副本,另外,正文段常常是只读的,以防止程序由于意外事故而修改器自身的指令。
B.初始化数据段。通常将此段称为数据段,它包含了程序中需赋初值的变量。例如,C程序中任何函数之外的说明:int maxcount = 99;(全局变量)
C.非初始化数据段。通常将此段称为bss段,这一名称来源于早期汇编程序的一个操作,意思是"block started by symbol",在程序开始执行之前,内核将此段初始化为0。函数外的说明: long sum[1000];
使此变量存放在非初始化数据段中。 注意这个地方初始化和非初始化的区别。
D.栈。自动变量以及每次函数调用时所需保存的信息都存放在此段中。每次函数调用时,其返回地址、以及调用者的环境信息(例如某些机器寄存器)都存放在栈中。然后,新被调用的函数在栈上为其自动和临时变量分配存储空间。通过以这种方式使用栈,C函数可以递归调用。
E.堆。通常在堆中进行动态存储分配。由于历史上形成的惯例,堆位于非初始化数据段顶和栈底之间。
所以现在再来回想linux 内存地址划分的5个段就比较好理解了。
从上图我们看到栈空间是下增长的,堆空间是从下增长的,他们会会碰头呀?一般不会,因为他们之间间隔很大,如:
#include 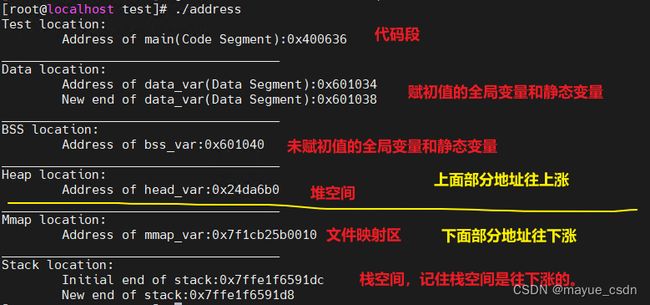
当我们多次运行上面代码时,发现test、Data、BSS这三个地址不变的,只有堆、mmap、栈的地址会变化。

下面是同时运行两次程序的结果:
 |
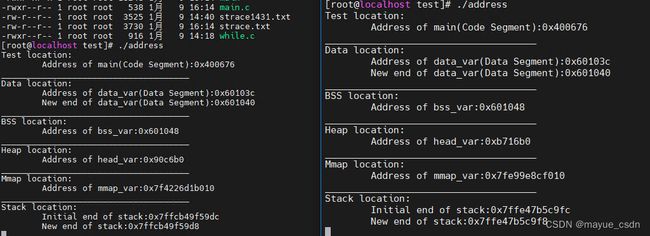 |
这里我们看到地址了,这个地址是虚拟地址,这些地址时怎么来的呢?其实在我们编译的时候,这些地址就已经确定了,如图中红线。
也就是说,我们不论我们运行a.out程序多少次这些地址都是一样的。我们知道,linux操作系统每个进程的地址空间都是独立的,其实这里的独立说得是物理空间上得独立。那相同的虚拟地址,不同的物理地址,他们之间是怎样联系起来的呢?我们继续探究…
在linux操作系统中,每个进程都通过一个task_struct的结构体描叙,每个进程的地址空间都通过一个mm_struct描叙,c语言中的每个段空间都通过vm_area_struct表示,他们关系如下 :

关于内存怎么从虚拟地址映射到物理内存的,后续有机会继续学习。
原文链接:https://blog.csdn.net/hustyangju/article/details/40541251
原文链接:https://blog.csdn.net/m200972391/article/details/79718709
三、其他资料
- 搜索:linux 0xc0000000 查内核空间管理,比如:概述 - Linux内存管理(一)
- 再谈应用程序分段: 数据段、代码段、BSS段以及堆和栈
- Linux操作系统知识讲解:走进linux 内存地址空间
- Linux内存描述之高端内存–Linux内存管理(五)