go语言切片函数参数传递+append()函数扩容
go语言切片函数参数传递+append()函数扩容
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
二叉树递归go代码:
var ans [][]int
func pathSum(root *TreeNode, targetSum int) ( [][]int) {
ans := make([][]int, 0)
path := []int{}
dfs(root, targetSum,path)
return ans
}
func dfs(node *TreeNode, left int,path []int) {
if node == nil {
return
}
left -= node.Val
path = append(path, node.Val)
if node.Left == nil && node.Right == nil && left == 0 {
ans = append(ans, append([]int(nil), path...))//在二维切片中添加一维切片
return
}
dfs(node.Left, left,path)
dfs(node.Right, left,path)
}
我的疑惑由这道题的代码产生,可以看到在dfs递归函数中,使用了参数path切片作为变量,而学过Go的都知道切片slice是引用类型,那么在函数传递时是引用传递吗。
可以知道path记录的是目前遍历过的数据,而我的疑惑就是对切片path一直添加了数据,那么为什么作为参数传进path后,在下层递归函数中的修改不会影响到上层path,以下是我查阅许多资料的解释。
1.Go中切片的结构体

如图所示,切片结构体包含了三部分,第一部分是指向底层数组的指针,其次是切片的大小len和切片的容量cap。
2.切片的扩容机制
切片的容量(cap)表示切片可以使用的底层数组的最大长度。当切片的长度(len)超过了容量时,切片就会自动扩容,即分配一个更大的底层数组,并将原有的数据复制过去。这个过程是由append函数完成的,我们不需要手动操作。
根据Go语言源码中的注释,切片扩容的规则如下:
如果原始容量小于1024,则新容量是原始容量的2倍;
如果原始容量大于等于1024,则新容量是原始容量的1.25倍;
如果连续扩容5次,且没有触发上述两种情况,则新容量是原始容量的1.5倍;
如果分配失败,则触发内存溢出。
**切片在函数内部进行扩容或缩容操作时,会导致切片指向一个新的底层数组,此时在函数内部和外部就不再共享同一个底层数组了。**因此当追加超出原本容量时,再改变切片内容后,对原来的数组是没有影响的
3.Go中的append函数


如上图可以看到,如果进行append后,
- 切片没有进行扩容,那么会直接添加或修改切片指向底层数组中后一位的值,故底层数组会受到改变;
- 而如果进行扩容,则会导致切片指向一个新的底层数组,对原来的数组是没有影响的
4.Go函数传参只有值传递一种方式,传地址必须加上*——其实也是传地址变量的值
看过有些博客说Go中切片是传地址,但其实这是错误的,
Go官方文档声明:Go中函数传参只有传值,传地址必须加上*,这其实也是传地址变量的值

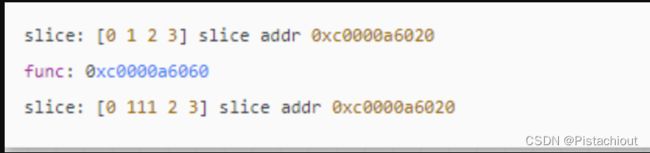
slice或者array作为函数参数传递的时候,本质是传值而不是传引用。传值的过程复制一个新的切片,这个切片也指向原始变量的底层数组。函数中无论是直接修改切片,还是append创建新的切片,都是基于共享切片底层数组的情况作为基础。也就是最外面的原始切片是否改变,取决于函数内的操作和切片本身容量。
递归代码分析
func dfs(node *TreeNode, left int,path []int) {
if node == nil {
return
}
left -= node.Val
path = append(path, node.Val)
if node.Left == nil && node.Right == nil && left == 0 {
ans = append(ans, append([]int(nil), path...))//在二维切片中添加一维切片
return
}
dfs(node.Left, left,path)
dfs(node.Right, left,path)
}
故在该递归函数dfs中,我们首先要知道,每次递归都是从左到右,递归完一条路径才会返回,故第一次递归时就会导致path达到叶子节点。且由path代表路径的定义,易知path的长度代表着当前遍历结点的深度。
在每一次传递的参数path都是传的切片值,而不是path的地址,故都是不同的切片值,只是指向的底层数组一样,且每次在函数内部进行append时,可能扩容,也可能不扩容
- 如果append后导致path扩容,会导致切片指向一个新的底层数组,此时在函数内部path和外部path就不再共享同一个底层数组了,因此不会影响上层递归函数的path
- 如果append后没有导致path扩容,那么会直接添加或修改切片指向底层数组中后一位的值;
- 如果是第一次遍历到当前深度,那么就会在底层数组中添加值,那么直接添加,并判断当前结点有无子树,若没有子树则加入ans中
- 如果已经遍历过当前深度,那么应该修改底层数组的切片后一位的值,这样确实会影响path的底层数组,但对所求的答案ans没有影响,因为修改之前的path路径已经在之前的递归中添加进了ans中;对之后的递归中的path也没有影响,因为之后的path在遍历到当前深度进行append时也会修改该深度的path值