JavaEE企业级应用开发教程——第四章 MyBatis的关联映射和缓存机制(黑马程序员第二版)(SSM)
第四章 MyBatis的关联映射和缓存机制
MyBatis的关联映射是指将多个表之间的关联关系映射到Java对象之间的关联关系,从而方便进行复杂的数据库操作。关联映射可以分为一对一、一对多、多对一和多对多四种类型。
MyBatis的缓存机制是指将查询结果缓存到内存中,下次查询相同的数据时可以直接从缓存中读取,从而提高查询效率。MyBatis的缓存机制分为一级缓存和二级缓存两种。
关联映射和缓存机制的作用是提高MyBatis的查询效率,特别是在进行复杂的数据库操作时更为明显。同时也可以降低数据库的压力,提高系统的稳定性和性能。
4.1 关联映射概述
一对一关联映射是指两个表之间只有一条关联记录,例如一个人只有一个身份证。一对多关联映射是指一个表中的一条记录可以对应另一个表中的多条记录,例如一个部门可以有多个员工。多对一关联映射是指多条记录可以对应另一个表中的一条记录,例如多个员工属于同一个部门。多对多关联映射是指两个表之间有多条关联记录,例如一个学生可以选修多门课程,一门课程也可以被多个学生选修。
在Java对象中,可以使用以下方式表示不同的关联关系:
一对一关联:使用一个对象作为属性表示关联对象,例如一个部门对象中包含一个负责人对象。
public class Department {
private Integer id;
private String name;
private Employee manager; // 一对一关联,部门的负责人
// 省略getter和setter方法
}
public class Employee {
private Integer id;
private String name;
private Department department; // 一对一关联,员工所在的部门
// 省略getter和setter方法
}一对多关联:使用一个集合作为属性表示关联对象列表,例如一个部门对象中包含多个员工对象。
public class Department {
private Integer id;
private String name;
private List employees; // 一对多关联,部门的员工列表
// 省略getter和setter方法
}
public class Employee {
private Integer id;
private String name;
private Department department; // 一对一关联,员工所在的部门
// 省略getter和setter方法
} 多对多关联:使用一个集合作为属性表示关联对象列表,例如一个学生对象中包含多个课程对象,一个课程对象中也包含多个学生对象。
public class Student {
private Integer id;
private String name;
private List courses; // 多对多关联,学生选修的课程列表
// 省略getter和setter方法
}
public class Course {
private Integer id;
private String name;
private List students; // 多对多关联,选修该课程的学生列表
// 省略getter和setter方法
} 需要注意的是,在进行关联映射时,Java对象的属性名称应与数据库中的字段名保持一致。如果不一致,可以通过MyBatis的映射配置来指定映射关系。
一级缓存是指在同一个SqlSession中进行的查询会话,MyBatis会将查询结果缓存到内存中,下次查询相同的数据时可以直接从缓存中读取。一级缓存是默认开启的,可以通过配置文件进行关闭。二级缓存是指在多个SqlSession之间共享查询结果缓存,可以提高查询效率。二级缓存需要在MyBatis的配置文件中进行配置,支持多种缓存实现方式,例如内存缓存、Redis缓存等。
4.2 一对一查询
在现实生活中,一对一关联关系是十分常见的。例如一个人只能有一个身份证,同时一个身份证也只对应一个人。人与身份证之间的关联关系如图4-3所示。在MyBatis中,通过
元素的属性如下:
以下是
属性名 |
描述 |
property |
当前实体类中与关联实体类相关联的属性名 |
javaType |
关联实体类的类型 |
resultMap |
关联实体类对应的结果集映射,可以嵌套使用 |
select |
关联查询语句,查询结果必须是一条记录,将结果映射到关联实体类 |
column |
当前实体类中的属性在数据库中对应的字段名 |
notNullColumn |
当前实体类中的属性在数据库中对应的字段名,不能为null |
foreignColumn |
关联实体类在数据库中对应的字段名 |
fetchType |
加载关联实体类的方式,有立即加载和延迟加载两种方式 |
lazy |
是否启用延迟加载 |
autoMapping |
是否启用自动映射 |
下面是一个
假设有两个实体类:Order(订单)和Customer(客户),它们之间存在一对一的关系。在Order类中,定义了一个customer属性,表示该订单的客户信息。
Order类代码示例:
public class Order {
private Integer orderId;
private String orderNo;
private Customer customer;
// 省略 getter 和 setter 方法
}在MyBatis的映射文件中,可以通过
在上面的映射文件中,
在
使用上述的映射文件,查询Order对象时,可以得到关联的Customer对象的属性值。
嵌套查询
嵌套查询是指将关联查询分成两步来完成。第一步查询当前对象所需的基本信息,第二步通过查询到的信息再去查询关联对象的详细信息。这种方式虽然需要进行两次查询,但是可以避免一次查询中出现大量的重复数据。
下面是一个简单的嵌套查询的示例,假设有两张表,一张为用户表 user,一张为订单表 order,每个用户可能有多个订单:
在上面的代码中,我们定义了一个名为 userOrderMap 的 resultMap,其中包括了 User 对象的基本属性映射以及嵌套查询 orders 的配置。在 orders 中,我们使用了 select 属性指定了查询关联对象的 SQL 语句,column 属性指定了关联列,resultMap 属性指定了处理关联结果集的 resultMap。
嵌套结果
除了嵌套查询,
下面是一个使用嵌套结果的例子:
在上面的代码中,我们定义了一个名为 userOrderMap 的 resultMap,其中包括了 User 对象的基本属性映射以及嵌套结果 orders 的配置。在 orders 中,我们使用了 resultMap 属性指定了处理关联结果集的 resultMap。这里的 orders 属性是 User 类中的一个 List 属性,对应于 Order 类的一个集合。这样,查询结果中每个 User 对象的 orders 属性将包含一个 Order 对象的集合。
4.3 一对多查询
与一对一的关联关系相比,开发人员接触更多的关联关系是对多(或多对一)。例如,一个用户可以有多个订单,多个订单也可以归一个用户所有。用户和订单的关联关系如图4-6所示。
在 MyBatis 中,通过
property:指定集合属性的名称。
ofType:指定集合属性中存储的对象类型。
resultMap:指定处理子对象的
。
select:指定查询子对象的 SQL 语句。
下面给出一个简单的例子:
在这个例子中,我们定义了一个名为 userMap 的 resultMap,其中包括了 User 对象的基本属性映射以及嵌套查询 orders 的配置。在 orders 中,我们使用了 select 属性指定了查询关联对象的 SQL 语句,ofType 属性指定了关联对象的类型,以及处理关联结果集的
嵌套查询方式
通过嵌套查询的方式,将一对多关联关系的多的一方查询出来,再设置到一的一方的对象中。
property:指定一的一方的属性名,表示将查询结果设置到哪个属性中。
ofType:指定多的一方的类型,即List集合中的元素类型。
select:指定查询多的一方的SQL语句。
column:指定连接两个表的列,即多的一方表的外键列。
fetchType:指定加载的时机,取值为lazy(懒加载)或eager(立即加载),默认为lazy。
以下是使用嵌套查询的
嵌套结果方式
通过嵌套结果的方式,将一对多关联关系的多的一方查询出来,以List的形式设置到一的一方的对象中。
property:指定一的一方的属性名,表示将查询结果设置到哪个属性中。
ofType:指定多的一方的类型,即List集合中的元素类型。
resultMap:指定处理多的一方的
元素的id。
以下是使用嵌套结果的
4.4 多对多查询
在 MyBatis 中,多对多关联关系的处理需要借助中间表来完成。假设有两个表 A 和 B,它们之间的多对多关系需要中间表 AB 来维护。AB 表通常包含两个外键,一个指向 A 表,另一个指向 B 表。
下面是一个简单的多对多关联关系的示例,假设有两个表:Student 和 Course,它们之间的关系需要通过中间表 student_course 来维护:
CREATE TABLE student (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE course (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE student_course (
student_id INT,
course_id INT,
PRIMARY KEY (student_id, course_id),
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);为了在 MyBatis 中处理多对多关联关系,我们需要使用
在上面的示例中,我们定义了两个 resultMap:studentMap 和 courseMap,分别用于处理 Student 对象和 Course 对象。其中,studentMap 包含了
property:指定了 Student 对象中包含 Course 对象的集合属性名称;
ofType:指定了集合中元素的类型;
select:指定了查询集合元素的 SQL 语句。
类似的,courseMap 也包含了
4.5 MyBatis缓存机制
MyBatis缓存机制是指MyBatis在执行数据库查询时,将查询结果暂时保存在内存中,以避免频繁访问数据库,提高查询性能的一种机制。
MyBatis提供了两级缓存机制:一级缓存和二级缓存。
4.5.1 一级缓存
一级缓存:也称为本地缓存,是SqlSession级别的缓存,它默认是开启的。一级缓存的作用域是同一个SqlSession,在同一个SqlSession中,如果多次查询同一个对象,第一次查询时会将查询结果存储在缓存中,下次查询时就可以直接从缓存中获取结果,而不用再次查询数据库。但是在同一个SqlSession中,如果执行了增删改操作,会清空一级缓存,防止误读。清空了缓存再查询就是到数据库查询了。
4.5.2 二级缓存
由4.5.1 节的内容可知,相同的Mapper 类使用相同的SQL语句如果 SqlSession 不同,则两个SqlSession查询数据库时,会查询数据库两次,这样也会降低数据库的查询效率。
为了解决这个问题,就需要用到 MyBatis的二级缓存。MyBatis 的二级缓存是 Mapper 级别的缓存,与一级缓存相比,二级缓存的范围更大,多个SqlSession可以共用二级缓存,并且二级缓存可以自定义缓存资源。
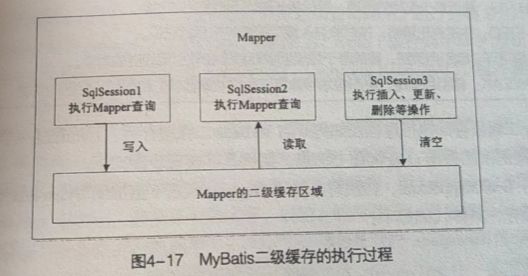
与MyBatis的一级缓存不同的是,MyBatis的二级缓存需要手动开启,开启二级缓存通常要完成以下两个步骤:
开启二级缓存的全局配置
在 MyBatis 配置文件(mybatis-config.xml)中添加以下配置:
其中,cacheEnabled 配置项用于开启二级缓存,cache 配置项用于指定二级缓存的实现方式。这里以使用 Ehcache 作为二级缓存为例。
开启当前Mapper的namespace 下的二级缓存
要开启某个 Mapper 的二级缓存,需要在该 Mapper 的 XML 文件中添加 cache 元素。例如:
其中,type 属性指定了使用的缓存实现类。org.apache.ibatis.cache.impl.PerpetualCache 是 MyBatis 内置的缓存实现类,也可以使用其他的缓存实现类,例如 Ehcache、Redis 等。
另外需要注意,开启 Mapper 的二级缓存时,也需要在 MyBatis 的全局配置文件中设置 cacheEnabled 为 true。例如:
这样,在使用该 Mapper 时,就会自动开启二级缓存。需要注意的是,当某个 Mapper 的二级缓存被开启时,如果对该 Mapper 进行了更新、插入、删除等操作,就会自动清空该 Mapper 的二级缓存。
属性名 |
是否必需 |
默认值 |
说明 |
type |
是 |
- |
缓存实现类的完全限定名 |
eviction |
否 |
LRU |
指定缓存的回收策略 |
flushInterval |
否 |
null |
缓存刷新间隔时间 |
size |
否 |
null |
缓存的最大数量 |
readOnly |
否 |
false |
是否只读 |
blocking |
否 |
false |
是否阻塞 |
其中,必填字段 type 指定了 MyBatis 使用哪个缓存实现类。其他字段都是可选项,下面是一些重要的属性:
eviction:指定缓存的回收策略,有 LRU、FIFO 和 SOFT 三种选择。LRU 表示 Least Recently Used,即最近最少使用,缓存将保留最近使用的元素,而最少使用的元素将被清除。FIFO 表示 First In First Out,即先进先出,缓存将按照插入顺序进行清除。SOFT 表示软引用,缓存元素将由 JVM 垃圾回收器自动回收。
flushInterval:指定缓存刷新的间隔时间,单位为毫秒。设置该属性可以定时刷新缓存,以避免缓存数据过期。
size:指定缓存的最大数量。当缓存元素的数量超过该值时,MyBatis 将从缓存中清除最近最少使用的元素。
readOnly:指定缓存是否只读。如果设置为 true,则不允许修改缓存中的元素,从而保证了缓存的一致性。
blocking:指定是否阻塞。如果设置为 true,则在缓存未命中时会等待数据的加载,直到缓存加载完成才会返回数据。
缓存命中率是指在一定时间范围内,缓存系统成功返回缓存数据的请求数与系统接收的所有缓存请求总数的比率。缓存命中率越高,说明缓存系统的效率越高,能够更快地响应请求,减轻后端数据库的负担,提高系统的吞吐量和性能。缓存命中率过低则会导致缓存失效,请求需要直接访问后端数据库,降低系统性能。因此,高效地管理缓存,提高缓存命中率是提高系统性能的关键因素之一。