性能调优通用逻辑
调优准备
定目标:根据线上预估访问量评估单场景QPS及混合场景QPS,和对应的RT值
环境区分:
测试环境单机压测进行链路问题排查问题,通常需要把单机打到CPU到100%,如果CPU到不了100%且请求已经各种超时或RT高于目标值,就得排查系统中瓶颈。换句话说,单机一定要调优到CPU是瓶颈且占用CPU的QPS、代码是合理的,参考指标4核8g的虚拟机空跑tomcat在1200QPS左右。
线上环境进行全链路压测摸排水位及瓶颈,通常会摸排到redis、db的使用问题或上下游其他服务瓶颈,如redis value过大等
链路mock
影子表:写场景避免压测数据干扰线上数据,在线上库1比1生成相同结构的表,表名增加下划线等方式区分,通过压测标路由到影子表写入或读取
登录态:压测需要模拟大量用户进行访问,登录态可采用提前生成或通过压测标mock
非调优目标下游:可通过长效缓存并进行预热的方式,或通过mock+等待下游平均耗时的方式
耗时统计
cat埋点,已封装注解CatTransaction,用于方法的耗时统计
调优方法,压测表象为RT高、超时多、异常多、QPS波动大,当CPU未满时可依次排查前几项(注:目的是压到CPU为瓶颈,当CPU不为瓶颈时一定存在某个资源点存在瓶颈,需要依次解决这个瓶颈问题)
线程池
jstack -l pid > 1.stack
确认runnable、blocked线程数(特殊情况也会是waiting),是否各worker线程池(如rpc、http)已打满
通常是需要有自己代码调用路径的栈信息才是有效的,除非引用了第三方包还没到自己代码就都阻塞了
在压测高峰区间多次连续dump stack,确认频繁出现的栈及对应的代码逻辑,通常来说就是问题卡口
可以通过top -Hp pid,查看当前进程下所有线程的占用CPU情况,如果有某个线程长期占用CPU高得重点关注,可以用线程pid号转到线程dump中的16进制对标找到栈信息
举例,如下是压权限链路线程dump的两个线程快照,且多次dump时有较多线程处于该位置waiting,再经代码逻辑发现是在等redis的response及反序列化执行结果,进一步排查redisson的线程发现较多堵在序列化,基本可以定位问题是redis存的单条数据过大
磁盘IO
# iostat -x 1 10 Linux 2.6.18-92.el5xen 02/03/2009 avg-cpu: %user %nice %system %iowait %steal %idle 1.10 0.00 4.82 39.54 0.07 54.46 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08 sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36 sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16 rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s rsec/s: 每秒读扇区数。即 delta(rsect)/s wsec/s: 每秒写扇区数。即 delta(wsect)/s rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算) wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算) avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio) avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。 await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio) svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio) %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。idle小于70% IO压力就较大了,一般读取速度有较多的wait.
常规应用基本都是写日志过多导致,因为写日志会抢锁、大多数情况到不了IO压力这一步,特殊场景有写本地文件的也需要多注意下
内存
常规case就是老年代被打满,出现频繁FGC,但是容易混淆是因为老年代被打满导致RT高,还是因为RT高导致老年代被打满。
前者大概率是频繁生成较大对象或者全局变量中在持续添加对象,通过memory dump基本都可以定位到问题
后者需要关注外部依赖的耗时是不是太高,导致临时对象gc不掉进入老年代,然后在老年代的对象暴涨后由于栈引用在等外部依赖的结果依然无法gc
还有一种极端情况,memory dump出来的结果很正常,但是存在大量无根对象,这种需要关注下fgc的线程是不是被阻塞了(如某对象的finnalize方法中等锁)
可通过jstat轮询jvm内存和gc情况,快速确认瞬时机器jvm情况
jstat -gcutil pid 1000 1000
第一个1000是1000次,第二个1000是1s一次
重点关注Old区、FGC次数、FGC耗时
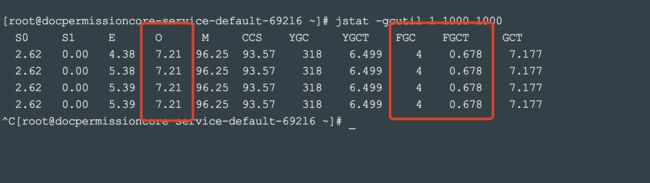
常规情况可以通过查看前20排名的对象快速定位,处理速度远超dump全量后导入到分析工具处理
jmap -histo pid | head -20
其中bytes是包含该对象所引用的所有对象大小总和,重点关注超过1G的
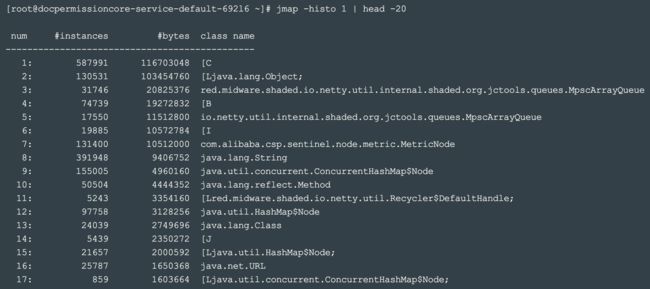
上述方法无法定位到内存问题点时,得全量dump并下载,成本高
jmap -J-XX:MaxHeapSize=512m -dump:format=b,file=xxx.bin pid
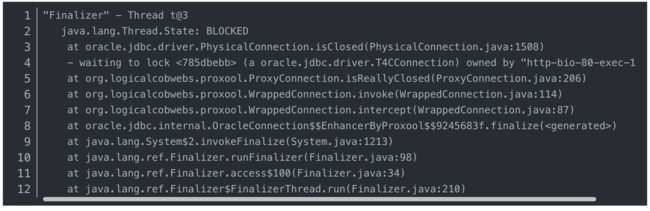
举例,通常内存问题是较好排查的,这里举个极端case,gc不掉的问题
下面的finalizer线程被block在jdbc释放锁,原因是proxool框架建立连接、获取连接、关闭连接都会占用锁,高流量进来后,finalizer线程因为无法抢到锁所以一直无法执行fgc,导致OOM
连接数
tcp连接层面的bug,一般不太会出现,有一例case是在centos6内核存在bug,导致tcp四次挥手时出现大量close_wait和time_waiting,会出现新的连接建连超时,如果压单机出现压测端大量超时且服务端负载极低可以查看下连接情况。正常情况下应该会有少量time_wait等待超时关闭。
netstat -anp pid

外部依赖,DB、redis
通过线程dump基本都可以定位到外部IO耗时较多的点位,不赘述
压测机器性能问题
上面资源都排查过依然出现CPU不满,QPS低且压测端RT高,要关注下压测机器本身是否存在问题
CPU
调优到CPU可以打满,基本看到希望了,下一步是要关注下当前占用CPU高的模块是否合理
如果是序列化占用较多,需要关注下技术方案上的让步,如何更合理设计数据结构,减少序列化成本,不要轻易考虑换序列化框架,通常用ali的fastjson足矣