如何简单实现ELT?
在商业中,数据通常和业务、企业前景以及财务状况相关,有效的数据管理可以帮助决策者快速有效地从大量数据中分析出有价值的信息。数据集成(Data Integration)是整个数据管理流程中非常重要的一环,它是指将来自多个数据源的数据组合在一起,提供一个统一的视图。
数据集成可以通过各种技术来实现,本文主要介绍如何用ELT(extract, load, transform)实现数据集成。区别于传统的ETL和其他的技术,ELT非常适合为数据湖仓或数据集市提供数据管道,并且可以用更低的成本,根据需求,随时对大量数据进行分析。
接下来将通过一个简单的示例(Demo)介绍如何实现ELT流程,具体的需求是将原始的电影票房数据保存到数据仓库,然后再对原始数据进行分析,得出相关的结果并且保存在数据仓库,供数据分析团队使用,帮助他们预测未来的收入。
技术栈选择
-
Data Warehouse: Snowflake
Snowflake是最受欢迎,最容易使用的数据仓库之一,并且非常灵活,可以很方便地与AWS、Azure以及Google Cloud集成。 -
Extract:通过k8s的cronjob将数据库的数据存到S3。
这里的技术选型比较灵活,取决于源数据库的类型以及部署的平台。Demo中将源数据从数据库提取出来后放在AWS S3,原因是Snowflake可以很方便与S3集成,支持复制数据到仓库并且自动刷新。
-
Load:通过Snowflake的External Tables将S3中的数据复制进数据仓库。
-
Transform:dbt
dbt支持使用SQL来进行简单的转换,同时提供了命令行工具,使用dbt我们可以进行良好的工程实践比如版本控制,自动化测试以及自动化部署。但对于比较复杂的业务场景来说,转换的过程一般都通过自己写代码实现。
-
Orchestrator: Airflow
Airflow和Oozie相比有更加丰富的监控数据以及更友好的UI界面。
下图描述了如何使用上述技术栈实现ELT:
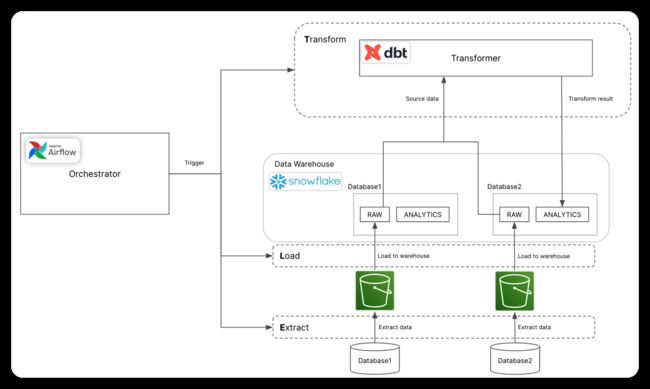
图中使用的Logo来自snowflake,dbt和Airflow的官方网站
工具介绍
Snowflake:数据存储
Snowflake是一个将全新的SQL查询引擎与一个专为云设计的创新架构相结合的数据云平台,它支持更快更灵活地进行数据存储、处理以及分析。
示例中将Snowflake作为数据仓库,存储原始数据电影院票房数量以及转换后的数据。
权限管理
和AWS类似,注册Snowflake后会持有一个拥有所有权限的root account。 如果直接使用此账号进行操作会非常危险,所以可以通过Snowflake提供的user和role来进行细粒度的权限管理。
最佳实践是用root account创建新的user并通过role赋予足够的权限,后续的操作都使用新创建的user来进行。
在下面的示例中,创建了一个名为TRANSFORMER的role,并且赋予它足够的权限。然后再创建一个使用这个role的user,在更方便地管理权限的同时,也实践了最小权限原则:
-- create role
CREATE ROLE TRANSFORMER COMMENT = 'Role for dbt';
-- grant permission to the role
GRANT USAGE, OPERATE ON WAREHOUSE TRANSFORMING TO ROLE TRANSFORMER;
GRANT USAGE, CREATE SCHEMA ON DATABASE PROD TO ROLE TRANSFORMER;
GRANT ALL ON SCHEMA "PROD"."RAW" TO ROLE TRANSFORMER;
GRANT ALL ON SCHEMA "PROD"."ANALYTICS" TO ROLE TRANSFORMER;
GRANT SELECT ON ALL TABLES IN SCHEMA "PROD"."RAW" TO ROLE TRANSFORMER;
GRANT SELECT ON FUTURE TABLES IN SCHEMA "PROD"."RAW" TO ROLE TRANSFORMER;
-- create user with role TRANSFORMER
create user user_demo password='abc123' default_role = TRANSFORMER must_change_password = true;
数据结构
每一个Snowflake的数据库都可以有多个schema,这里我们根据常见的实践,创建了schema RAW和ANALYTICS,分别用来存放原始数据和转换之后的数据:
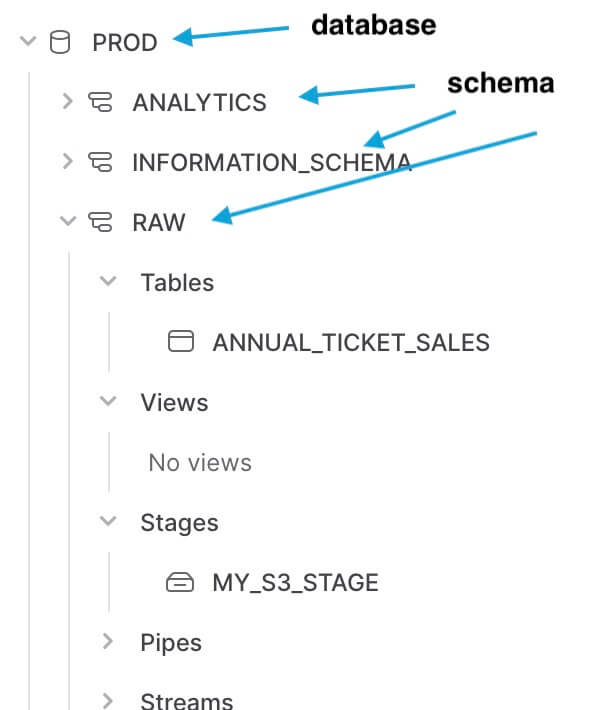
每一个schema下面都可以有table、view和stage等数据库object。
stage是snowflake提供的一个空间,它支持我们将数据文件上传到这里,然后通过copy命令把外部数据导入到Snowflake。图中MY_S3_STAGE就是Demo中用来加载存放在AWS S3中的数据文件的,我们过这个stage实现了ELT中的L(Loading)。
dbt (data build tool):原始数据转化
在完成了原始数据的Extract和Loading后,怎样根据需求对它们进行Transform从而获得隐藏在数据中的有效信息呢?
这里我们选择dbt来进行数据的转化,它是一个支持我们通过简单地编写select语句来进行数据转换的工具,在Demo中它帮助完成了历史票房数据的统计工作。
Model
一个model就是一个写在.sql文件中的select语句,通常会默认使用文件名作为transform结果的表名。下面是demo中的一个model,from语句后面跟着的是一个dbt提供的引用源数据的方法。在model目录里的配置文件中声明源数据表之后,就可以直接通过source()方法来引用source table了。
select *
from {{ source('ticket_sales','annual_ticket_sales') }}
where ticket_year > ‘2010’
Jinja Function
当需求变得更复杂时,如果仅仅通过SQL实现转换将会很困难,所以可以通过Jinja Function来实现在SQL中无法做到的事。
比如在有多个Model的dbt工程中,通常会有一些可以复用的逻辑,类似于编程语言中的函数。有了Jinja Function,就可以把要复用的逻辑提取成单独的Model,然后在其他Model中通过表达式{{ ref() }}来引用它:
select sum(total_inflation_adjusted_office) as total_sales
from {{ ref('annual_ticket_sales') }}
Materializations
在上一部分的场景中,通常不希望把可复用的逻辑持久化在数据仓库中。
这里就可以引入配置Materializations来改变dbt对于model的持久化策略,比如将此配置设置为Ephemeral:
{{ config(materialized=‘table’) }}
这样model就仅被当作临时表被其他model引用而不会被持久化在数据仓库中。如果设置为View,model就会被在数据仓库中创建为视图。除此之外这个配置还支持类型:Table以及Incremental**。**
Test
为了防止原始数据有脏数据,所以在这里引入测试帮助保证最后结果的正确性。dbt提供了两种级别的测试:
- Generic test:这是一种比较通用的测试,为字段级别,它通常可以加在对Source和Target的声明里,应用于某一个字段并且可以重复使用。比如在demo中,我们希望ticket_year这个字段不为空并且是不会重复的:
tables:
- name: annual_ticket_sales
columns:
- name: ticket_year
description: "Which year does the sales amount stands for"
tests:
- not_null
- unique
- name: tickets_sold
tests:
- not_null
- name: total_box_office
tests:
- not_null
- Singular Test:它是通过一段SQL语句来定义的测试,是表级别。
比如查询源数据表里total_box_office小于0的记录,当查询不到结果时表示测试通过:
select total_box_office
from {{source('ticket_sales','annual_ticket_sales')}}
where total_box_office < 0
Airflow:任务编排
有了把原始数据集成进数据仓库的方法,也完成了数据转化的工程, 那么如何才能让它们有顺序地、定时地运行呢?
这里我们选择用Airflow进行任务的编排,它是一个支持通过编程编写data pipeline,并且调度和监控各个任务的平台。
DAG
第一步就是为我们的ELT流程创建一个流水线,在Airflow中,一个DAG(Directed Acyclic Graph)就可以看作是一个pipeline。声明它的时候需要提供一些基本的属性,比如DAG name, 运行间隔以及开始日期等等。
Airflow支持使用Python语言编写pipeline的代码,因此也具有较强的扩展性。
Demo中我们设置这个DAG的开始日期是2022年5月20号,并且期望它每天运行一次:
default_args = {
'start_date': datetime(2022, 5, 20)
}
with DAG('annual_ticket_processing', schedule_interval='@daily',
default_args=default_args, catchup=True) as dag:
Task
流水线创建完成之后,我们需要将ELT的各个步骤加入到这个流水线中。这里的每一个步骤被称为Task,Task是Airflow中的基本执行单位,类似于pipeline中的step。在Demo中,在数据仓库中创建表、把原始数据加载到数据仓库、测试和数据转化分别是一个task。
在Airflow中,可以通过Operator快速声明一个task,Operator是一个提前定义好的模版,只需要提供必要的参数比如task id,SQL语句等即可。
下面这个task的功能是在Snowflake中创建表,需要提供的是一个连接Snowflake的Connection,要运行的SQL语句以及目标database和schema:
snowflake_create_table = SnowflakeOperator(
task_id='snowflake_create_table',
snowflake_conn_id='love_tech_snowflake',
sql=CREATE_TABLE_SQL_STRING,
database='PROD',
schema='RAW',
)
Task dependency
当我们对于task的运行顺序有特定要求时,比如为了保证最后报告的准确性,希望在对原始数据的测试通过之后再进行数据转化。这时可以通过定义task之间的依赖关系,来对它们的运行顺序进行编排,如下的依赖关系表示先在Snowflake创建数据表,然后将原数据加载到其中,完成后对于原始数据进行测试,如果测试失败就不会再运行后续的task:
snowflake_create_table >> copy_into_table >> dbt_test >> transform_data
Backfill
在平时的工作中,我们经常会遇到业务变动导致数据表里新增一个字段的情况,此时就需要将原始数据重新同步一遍。这时就可以利用Airflow提供的Backfill机制,帮助我们一次性回填指定区间内缺失的所有历史任务。
比如Demo中DAG的start date是5月20日,所以在打开开关之后,Airflow帮我们回填了start date之后的所有DAG run:

上图中DAG是在5月25日创建的,但Airflow却只从开始日期创建任务到24号,看起来缺失了25号的任务。原因是上图的24号是logical date(execution date),即trigger DAG run的日期。因为在定义DAG的时候将schedule_interval属性设置为daily,所以在25日(Actually Execute Date)当天只会执行24日(logical date)的任务。
监控和调试
Airflow提供了友好的UI界面让我们可以更方便地从各种维度监控以及调试,比如查看一年的运行情况:
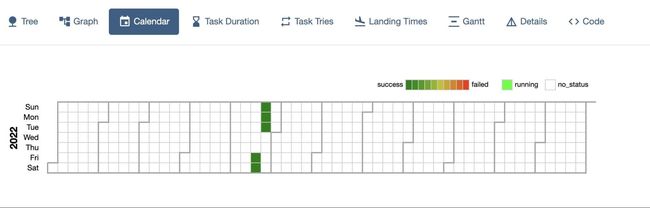
或者每一个task的运行时间:
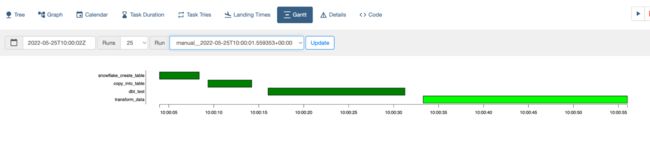
以及task的log:
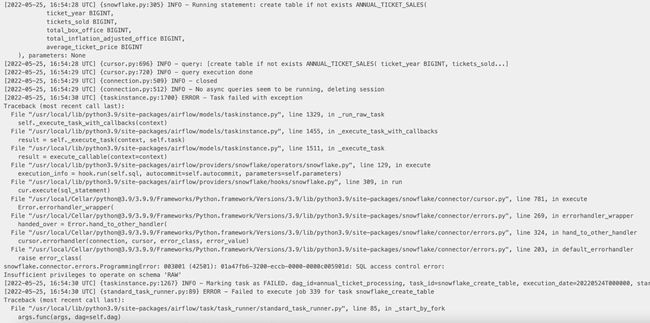
等等,这里只列举了其中几个,大家有兴趣的话可以自己探索。
Parallelism
通常我们需要把多个数据源的数据,集成到同一个数据仓库中便于进行分析,因为这些task之间互相没有影响,所以可以通过同步运行它们来提高效率。
这种场景下,一方面可以通过配置参数Parallelism来控制Airflow worker的数量,也就是同时可以运行的task的数量,另一方面也需要更改Executor的类型,因为默认的Sequential Executor只支持同时运行一个task。
假设task的依赖关系声明为:task_1 >> [task_3, task_2] >> task_4
,在更换到Local Executor并且设置parallelism为5之后,启动Airflow,可以发现Airflow会创建5个worker。这时再触发DAG run,task2和task3就可以同时运行了:
~ yunpeng$ ps -ax | grep 'airflow worker'
59088 ttys017 0:02.81 airflow worker -- LocalExecutor
59089 ttys017 0:02.82 airflow worker -- LocalExecutor
59090 ttys017 0:02.81 airflow worker -- LocalExecutor
59091 ttys017 0:02.82 airflow worker -- LocalExecutor
59092 ttys017 0:02.81 airflow worker -- LocalExecutor
DEMO运行结果
原始数据被加载到Snowflake的RAW schema中,dbt project可以随时引用这些数据:

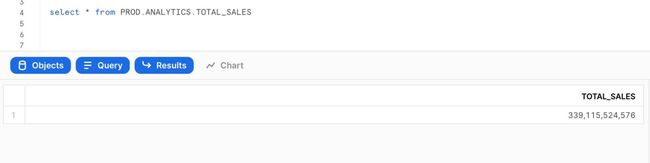
转换结果被持久化在ANALYTICS schema里,这些数据可以直接用来分析,也可以作为源数据被再次引用:
Repo link
dbt project: https://github.com/littlepainterdao/dbt_development
Airflow: https://github.com/littlepainterdao/airflow
本文整体比较基础,希望之前没有接触过ELT的同学可以通过这篇文章对它以及Snowflake,dbt和Airflow有初步的了解。
文/Thoughtworks 丁云鹏,张倬凡
原文链接:https://insights.thoughtworks.cn/how-to-implement-elt/