第5周学习:ShuffleNet & EfficientNet & 迁移学习
ShuffleNet & EfficientNet & 迁移学习
- ShuffleNet V1 & V2
- EfficientNet网络
- Transformer里的 multi-head self-attention
- ShuffleNet & EfficientNet & 迁移学习
-
- Step 1:下载数据
- step 2:数据处理
- step 3:创建VGG Model
- step 4:修改最后一层,冻结前面层的参数
- step 5:训练并测试全连接层
- step 6:可视化模型预测结果(主观分析)
- AI艺术鉴赏挑战赛 - 看画猜作者
-
- data_count.py
- dataload.py
- train.py
- test.py
- ArtModel.py
- vote.py
ShuffleNet V1 & V2
ShuffleNet V1框架:卷积层、最大池化下采样、Stage2、Stage3、Stage4、全局池化、全连接层

ResNeXt第二步group卷积因此/g,ShuffleNet同样,第二步DW卷积g=m,即约去一个m。

ShuffleNet V2:
主要拥有两个创新点:
(1)由于逐点卷积占了很大的计算量,所以使用pointwise group convolution 逐点分组卷积
(2)由于存在不同组之间特征通信问题,所以采用channel shuffle

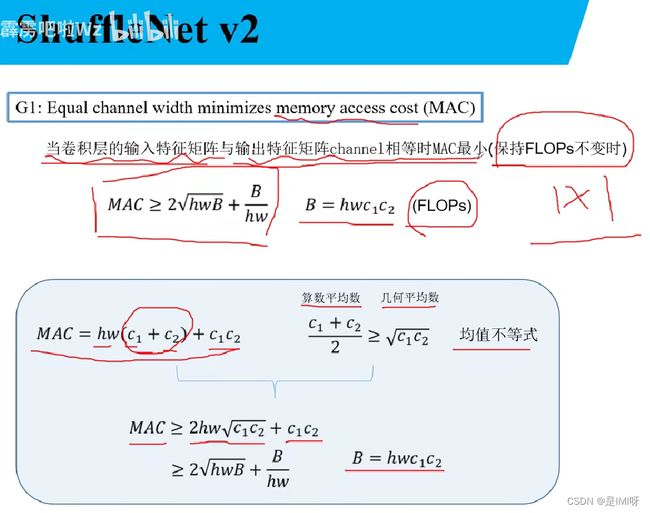
网络四个设计原则:
(1)使用平衡convoluntions,让输入特征矩阵channel和输出特征矩阵channel比值为1
(2)注意group convolution的计算成本,不能一味增加group数
(3)降低网络训练程度
(4)尽可能减少使用element-wise opeartions张量操作
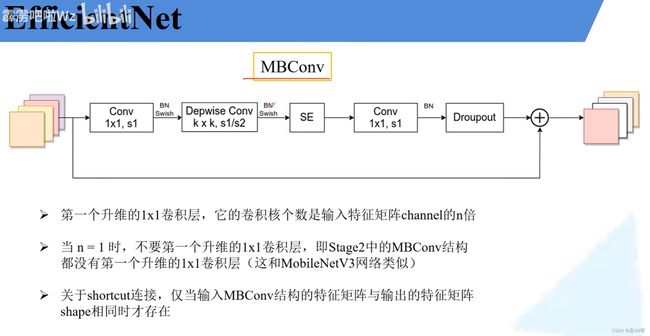
EfficientNet网络
EfficientNet与其他网络的对比:
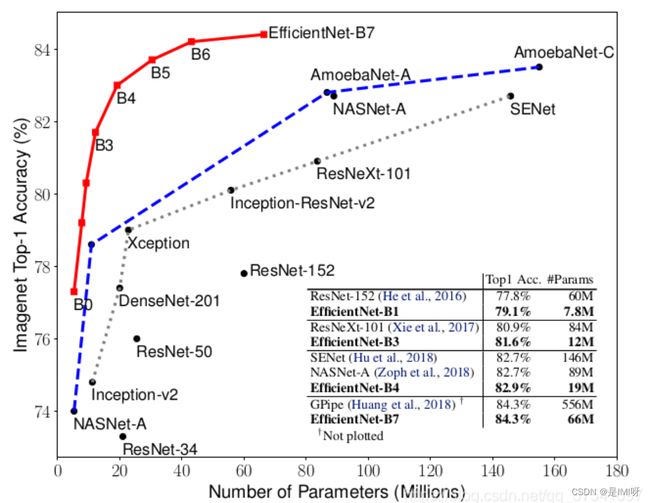

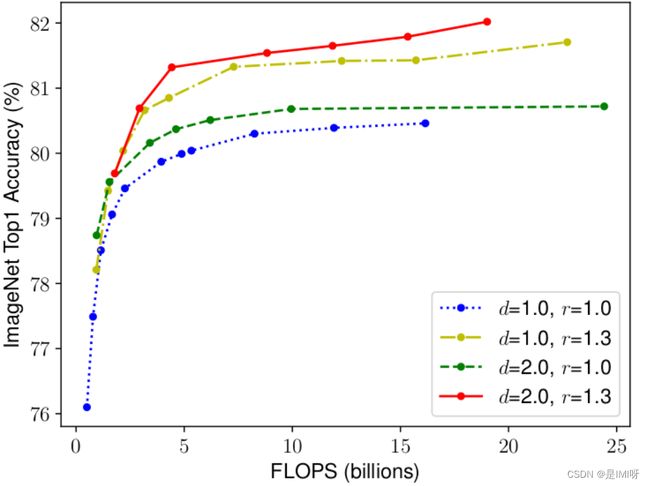
采用不同的d,r组合,然后不断改变网络的width得到如下图所示的4条曲线,通过分析可以发现在相同的FLOPs下,同时增加d和r的效果最好。
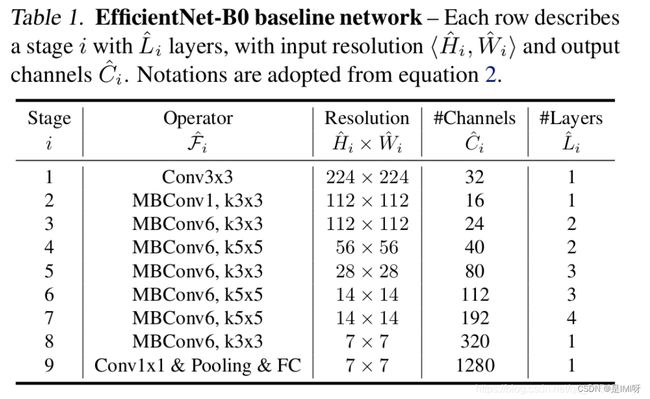
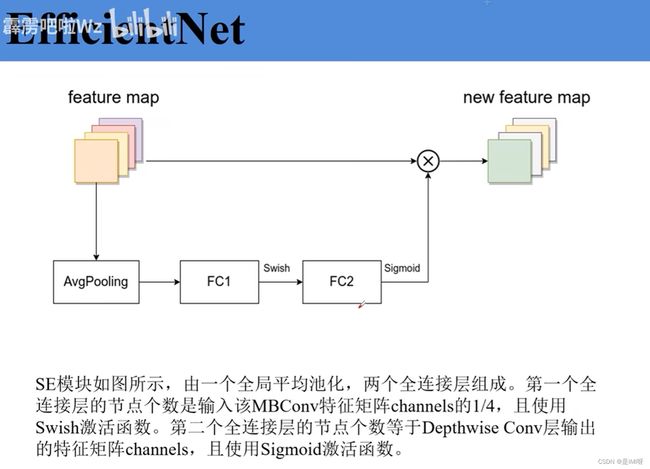
下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage,第一个Stage就是一个卷积核大小为3x3步距为2的普通卷积层(包含BN和激活函数Swish),Stage2~Stage8都是在重复堆叠MBConv结构(最后一列的Layers表示该Stage重复MBConv结构多少次),而Stage9由一个普通的1x1的卷积层(包含BN和激活函数Swish)一个平均池化层和一个全连接层组成。表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
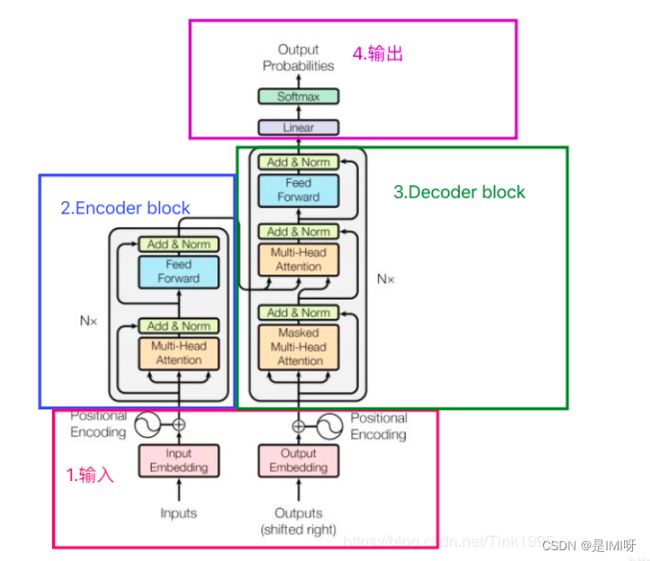
Transformer里的 multi-head self-attention
首先了解了self-attention,在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,相当于是Query=Key=Value,计算过程与attention一样。
基于Encoder-Decoder框架的模型Transformer结构图:
Multi-Head Attention模块和Self-Attention模块一样将 a i a_i ai分别通过 W q W^q Wq, W k W^k Wk, W v W^v Wv得到对应的 q i q^i qi, k i k^i ki, v i v^i vi,然后再根据使用的head数目h进一步把得到的 q i q^i qi, k i k^i ki, v i v^i vi均分成h份。比如下图中假设h=2然后 q 1 q^1 q1拆分成 q 1 , 1 q^{1,1} q1,1和 q 1 , 2 q^{1,2} q1,2,那么 q 1 , 1 q^{1,1} q1,1就属于head1, q 1 , 2 q^{1,2} q1,2属于head2。
也可以将 W i Q W^Q_i WiQ, W i K W^K_i WiK, W i V W^V_i WiV设置成对应值来实现均分,比如下图中的Q通过 W 1 Q W^Q_1 W1Q就能得到均分后的 Q 1 Q_1 Q1。

通过上述方法就能得到每个 h e a d i head_i headi对应的 Q i Q_i Qi, K i K_i Ki, V i V_i Vi参数,接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。

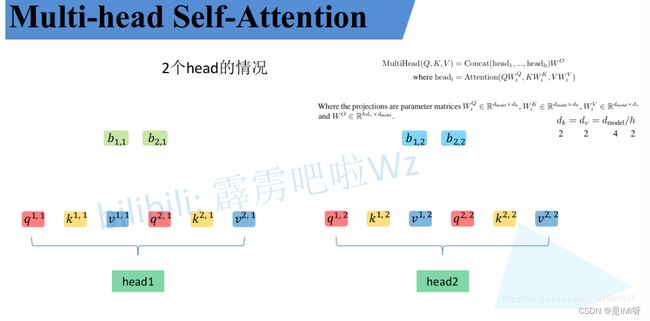
接着将每个head得到的结果进行concat拼接,比如下图中 b 1 , 1 b_{1,1} b1,1( h e a d 1 head_1 head1得到的 b 1 b_1 b1)和 b 1 , 2 b_{1,2} b1,2( h e a d 2 head_2 head2得到的 b 1 b_1 b1)拼接在一起, b 2 , 1 b_{2,1} b2,1( h e a d 1 head_1 head1得到的 b 2 b_2 b2)和 b 2 , 2 b_{2,2} b2,2( h e a d 2 head_2 head2得到的 b 2 b_2 b2)拼接在一起。

接着将拼接后的结果通过 W O W^O WO(可学习的参数)进行融合,如下图所示,就可以得到最终的结果 b 1 b_1 b1和 b 2 b_2 b2。
Multi-Head Attention中的两个重要公式:

ShuffleNet & EfficientNet & 迁移学习
Step 1:下载数据
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
训练集包含1800张图(猫的图片900张,狗的图片900张),测试集包含2000张图
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
! unzip dogscats.zip
step 2:数据处理
torchvision 支持对输入数据进行一些复杂的预处理/变换 (normalization, cropping, flipping, jittering 等,datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 224×224×3的大小,同时还将进行归一化处理。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './dogscats'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'valid']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']}
dset_classes = dsets['train'].classes
通过下面代码可以查看 dsets 的一些属性:
print(dsets['train'].classes)
print(dsets['train'].class_to_idx)
print(dsets['train'].imgs[:5])
print('dset_sizes: ', dset_sizes)
![]()
加载数据,设定循环次数:
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6)
'''
valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400
同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看
'''
count = 1
for data in loader_valid:
print(count, end='\n')
if count == 1:
inputs_try,labels_try = data
count +=1
print(labels_try)
print(inputs_try.shape)
显示图片的小程序:
def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
#显示 labels_try 的5张图片,即valid里第一个batch的5张图片:
out = torchvision.utils.make_grid(inputs_try)
imshow(out, title=[dset_classes[x] for x in labels_try])

step 3:创建VGG Model
直接使用预训练好的 VGG 模型,同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果:
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
print(outputs_try)
print(outputs_try.shape)
'''
可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。
但是我也可以观察到,结果非常奇葩,有负数,有正数,
为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print( 'prob sum: ', torch.sum(probs,1))
print( 'vals_try: ', vals_try)
print( 'pred_try: ', pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])
 可以看到预测结果,五张猫猫都正确预测。
可以看到预测结果,五张猫猫都正确预测。
step 4:修改最后一层,冻结前面层的参数
VGG 模型如下图所示,网络由三种元素组成:
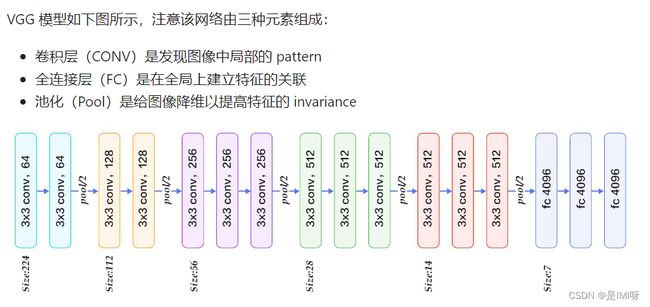
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)

step 5:训练并测试全连接层
创建损失函数和优化器 + 训练模型 + 测试模型
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)

训练集测试准确率79.5%
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])

测试集测试准确率95.65%
step 6:可视化模型预测结果(主观分析)
主观分析就是把预测的结果和相对应的测试图像输出出来看看,一般有四种方式:
(1)随机查看一些预测正确的图片
(2)随机查看一些预测错误的图片
(3)预测正确,同时具有较大的probability的图片
(4)预测错误,同时具有较大的probability的图片
(5)最不确定的图片,比如说预测概率接近0.5的图片
# 单次可视化显示的图片个数
n_view = 8
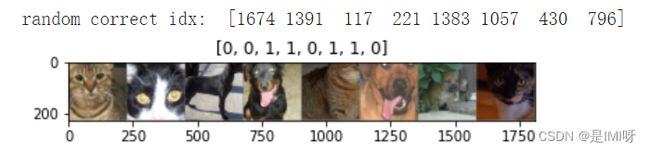
# 随即查看了预测正确的图片
correct = np.where(predictions==all_classes)[0]
from numpy.random import random, permutation
idx = permutation(correct)[:n_view]
print('random correct idx: ', idx)
loader_correct = torch.utils.data.DataLoader([dsets['valid'][x] for x in idx],
batch_size = n_view,shuffle=True)
for data in loader_correct:
inputs_cor,labels_cor = data
# Make a grid from batch
out = torchvision.utils.make_grid(inputs_cor)
imshow(out, title=[l.item() for l in labels_cor])
# 类似的思路,可以显示错误分类的图片,这里不再重复
AI艺术鉴赏挑战赛 - 看画猜作者
季军代码:基于Resnext50,eff-b3训练图像尺寸448,512,600的模型,取得分最高的4组结果进行投票
data_count.py
划分数据集,30张以下的数据没有被划分验证集,class_cnt:label,idx,idx。with open() as 用于读写文件
import os
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
df = pd.read_csv('train.csv').values
print(df[:5])
class_cnt = {}
for idx, label in df:
print(idx, label)
if label not in class_cnt:
class_cnt[label] = []
class_cnt[label].append(idx)
for k, v in class_cnt.items():
print(k, len(v))
big_x = []
big_y = []
small_x = []
small_y = []
for k, v in class_cnt.items():
if len(v) < 30:
small_x.extend(v)
small_y.extend(np.ones(len(v), dtype=np.int16) * k)
else:
big_x.extend(v)
big_y.extend(np.ones(len(v), dtype=np.int16) * k)
print(big_x)
print(big_y)
train_x, test_x, train_y, test_y = train_test_split(big_x, big_y, random_state=999, test_size=0.2)
train_x.extend(small_x)
train_y.extend(small_y)
with open('train.txt', 'w')as f:
for fn, label in zip(train_x, train_y):
f.write('./data/Art/data/train/{}.jpg,{}\n'.format(fn, label))
with open('val.txt', 'w')as f:
for fn, label in zip(test_x, test_y):
f.write('./data/Art/data/train/{}.jpg,{}\n'.format(fn, label))
dataload.py
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision.transforms主要是用于常见的一些图形变换。主要由以下四部分构成:
(1)torchvision.datasets: 一些加载数据的函数及常用的数据集接口
(2)torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等
(3)torchvision.transforms: 常用的图片变换,例如裁剪、旋转等
(4)torchvision.utils: 其他的一些有用的方法
torchvision.transforms.Compose()的主要作用是串联多个图片变换的操作,进行数据增强
from torch.utils.data import dataset
from PIL import Image
from torchvision import transforms, models
import random
import numpy as np
import torch
size = 512
trans = {
'train':
transforms.Compose([
#以0.5的概率水平翻转给定的PIL图像
transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
# transforms.ColorJitter(brightness=0.126, saturation=0.5),
# transforms.RandomAffine(degrees=30, translate=(0.2, 0.2), fillcolor=0, scale=(0.8, 1.2), shear=None),
transforms.Resize((int(size / 0.875), int(size / 0.875))),
#在一个随机的位置进行裁剪
transforms.RandomCrop((size, size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
#随机选择图像中的矩形区域并删除其像素
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3))
]),
'val':
transforms.Compose([
transforms.Resize((int(size / 0.875), int(size / 0.875))),
transforms.CenterCrop((size, size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}
class Dataset(dataset.Dataset):
def __init__(self, mode):
assert mode in ['train', 'val']
txt = './data/Art/data/%s.txt' % mode
fpath = []
labels = []
with open(txt, 'r')as f:
for i in f.readlines():
fp, label = i.strip().split(',')
fpath.append(fp)
labels.append(int(label))
self.fpath = fpath
self.labels = labels
self.mode = mode
self.trans = trans[mode]
def __getitem__(self, index):
fp = self.fpath[index]
label = self.labels[index]
img = Image.open(fp).convert('RGB')
if self.trans is not None:
img = self.trans(img)
return img, label
def __len__(self):
return len(self.labels)
train.py
导入数据进行训练,记录最好结果
from torch.utils.data import DataLoader
from ArtModel import BaseModel
import time
import numpy as np
import random
from torch.optim import lr_scheduler
from torch.backends import cudnn
import argparse
import os
import torch
import torch.nn as nn
from dataload import Dataset
#参数
parser = argparse.ArgumentParser()
parser.add_argument('--model_name', default='resnext50', type=str)
parser.add_argument('--savepath', default='./Art/', type=str)
parser.add_argument('--loss', default='ce', type=str)
parser.add_argument('--num_classes', default=49, type=int)
parser.add_argument('--pool_type', default='avg', type=str)
parser.add_argument('--metric', default='linear', type=str)
parser.add_argument('--down', default=0, type=int)
parser.add_argument('--lr', default=0.01, type=float)
parser.add_argument('--weight_decay', default=5e-4, type=float)
parser.add_argument('--momentum', default=0.9, type=float)
parser.add_argument('--scheduler', default='cos', type=str)
parser.add_argument('--resume', default=None, type=str)
parser.add_argument('--lr_step', default=25, type=int)
parser.add_argument('--lr_gamma', default=0.1, type=float)
parser.add_argument('--total_epoch', default=60, type=int)
parser.add_argument('--batch_size', default=32, type=int)
parser.add_argument('--num_workers', default=8, type=int)
parser.add_argument('--multi-gpus', default=0, type=int)
parser.add_argument('--gpu', default=0, type=int)
parser.add_argument('--seed', default=2020, type=int)
parser.add_argument('--pretrained', default=1, type=int)
parser.add_argument('--gray', default=0, type=int)
args = parser.parse_args()
def train():
model.train()
epoch_loss = 0
correct = 0.
total = 0.
t1 = time.time()
for idx, (data, labels) in enumerate(trainloader):
data, labels = data.to(device), labels.long().to(device)
out, se, feat_flat = model(data)
loss = criterion(out, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item() * data.size(0)
total += data.size(0)
_, pred = torch.max(out, 1)
correct += pred.eq(labels).sum().item()
acc = correct / total
loss = epoch_loss / total
print(f'loss:{loss:.4f} acc@1:{acc:.4f} time:{time.time() - t1:.2f}s', end=' --> ')
with open(os.path.join(savepath, 'log.txt'), 'a+')as f:
f.write('loss:{:.4f}, acc:{:.4f} ->'.format(loss, acc))
return {'loss': loss, 'acc': acc}
def test(epoch):
model.eval()
epoch_loss = 0
correct = 0.
total = 0.
with torch.no_grad():
for idx, (data, labels) in enumerate(valloader):
data, labels = data.to(device), labels.long().to(device)
out = model(data)
loss = criterion(out, labels)
epoch_loss += loss.item() * data.size(0)
total += data.size(0)
_, pred = torch.max(out, 1)
correct += pred.eq(labels).sum().item()
acc = correct / total
loss = epoch_loss / total
print(f'test loss:{loss:.4f} acc@1:{acc:.4f}', end=' ')
global best_acc, best_epoch
state = {
'net': model.state_dict(),
'acc': acc,
'epoch': epoch
}
if acc > best_acc:
best_acc = acc
best_epoch = epoch
torch.save(state, os.path.join(savepath, 'best.pth'))
print('*')
else:
print()
torch.save(state, os.path.join(savepath, 'last.pth'))
with open(os.path.join(savepath, 'log.txt'), 'a+')as f:
f.write('epoch:{}, loss:{:.4f}, acc:{:.4f}\n'.format(epoch, loss, acc))
return {'loss': loss, 'acc': acc}
def plot(d, mode='train', best_acc_=None):
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
plt.suptitle('%s_curve' % mode)
plt.subplots_adjust(wspace=0.2, hspace=0.2)
epochs = len(d['acc'])
plt.subplot(1, 2, 1)
plt.plot(np.arange(epochs), d['loss'], label='loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper left')
plt.subplot(1, 2, 2)
plt.plot(np.arange(epochs), d['acc'], label='acc')
if best_acc_ is not None:
plt.scatter(best_acc_[0], best_acc_[1], c='r')
plt.xlabel('epoch')
plt.ylabel('acc')
plt.legend(loc='upper left')
plt.savefig(os.path.join(savepath, '%s.jpg' % mode), bbox_inches='tight')
plt.close()
if __name__ == '__main__':
best_epoch = 0
best_acc = 0.
use_gpu = False
if args.seed is not None:
print('use random seed:', args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
np.random.seed(args.seed)
random.seed(args.seed)
cudnn.deterministic = False
if torch.cuda.is_available():
use_gpu = True
cudnn.benchmark = True
# loss交叉熵损失
criterion = nn.CrossEntropyLoss()
# dataloader
trainset = Dataset(mode='train')
valset = Dataset(mode='val')
trainloader = DataLoader(dataset=trainset, batch_size=args.batch_size, shuffle=True, \
num_workers=args.num_workers, pin_memory=True, drop_last=True)
valloader = DataLoader(dataset=valset, batch_size=128, shuffle=False, num_workers=args.num_workers, \
pin_memory=True)
# model
model = BaseModel(model_name=args.model_name, num_classes=args.num_classes, pretrained=args.pretrained, pool_type=args.pool_type, down=args.down, metric=args.metric)
if args.resume:
state = torch.load(args.resume)
print('best_epoch:{}, best_acc:{}'.format(state['epoch'], state['acc']))
model.load_state_dict(state['net'])
if torch.cuda.device_count() > 1 and args.multi_gpus:
print('use multi-gpus...')
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.distributed.init_process_group(backend="nccl", init_method='tcp://localhost:23456', rank=0, world_size=1)
model = model.to(device)
model = nn.parallel.DistributedDataParallel(model)
else:
device = ('cuda:%d'%args.gpu if torch.cuda.is_available() else 'cpu')
model = model.to(device)
print('device:', device)
# optim优化
optimizer = torch.optim.SGD(
[{'params': filter(lambda p: p.requires_grad, model.parameters()), 'lr': args.lr}],
weight_decay=args.weight_decay, momentum=args.momentum)
print('init_lr={}, weight_decay={}, momentum={}'.format(args.lr, args.weight_decay, args.momentum))
if args.scheduler == 'step':
#动态调整学习率
scheduler = lr_scheduler.StepLR(optimizer, step_size=args.lr_step, gamma=args.lr_gamma, last_epoch=-1)
elif args.scheduler == 'multi':
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[150, 225], gamma=args.lr_gamma, last_epoch=-1)
elif args.scheduler == 'cos':
warm_up_step = 10
lambda_ = lambda epoch: (epoch + 1) / warm_up_step if epoch < warm_up_step else 0.5 * (
np.cos((epoch - warm_up_step) / (args.total_epoch - warm_up_step) * np.pi) + 1)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda_)
# savepath
savepath = os.path.join(args.savepath, args.model_name+args.pool_type+args.metric+'_'+str(args.down))
print('savepath:', savepath)
if not os.path.exists(savepath):
os.makedirs(savepath)
with open(os.path.join(savepath, 'setting.txt'), 'w')as f:
for k, v in vars(args).items():
f.write('{}:{}\n'.format(k, v))
f = open(os.path.join(savepath, 'log.txt'), 'w')
f.close()
total = args.total_epoch
start = time.time()
train_info = {'loss': [], 'acc': []}
test_info = {'loss': [], 'acc': []}
for epoch in range(total):
print('epoch[{:>3}/{:>3}]'.format(epoch, total), end=' ')
d_train = train()
scheduler.step()
d_test = test(epoch)
for k in train_info.keys():
train_info[k].append(d_train[k])
test_info[k].append(d_test[k])
plot(train_info, mode='train')
plot(test_info, mode='test', best_acc_=[best_epoch, best_acc])
end = time.time()
print('total time:{}m{:.2f}s'.format((end - start) // 60, (end - start) % 60))
print('best_epoch:', best_epoch)
print('best_acc:', best_acc)
#记录最好结果
with open(os.path.join(savepath, 'log.txt'), 'a+')as f:
f.write('# best_acc:{:.4f}, best_epoch:{}'.format(best_acc, best_epoch))
test.py
进行预测并记录预测结果
import torch
from ArtModel import BaseModel
import os
import pandas as pd
from PIL import Image
from torchvision import transforms
import numpy as np
import argparse
def get_setting(path):
args = {}
with open(os.path.join(path, 'setting.txt'), 'r')as f:
for i in f.readlines():
k, v = i.strip().split(':')
args[k] = v
return args
def load_pretrained_model(path, model, mode='best'):
print('load pretrained model...')
state = torch.load(os.path.join(path, '%s.pth' % mode))
print('best_epoch:{}, best_acc:{}'.format(state['epoch'], state['acc']))
model.load_state_dict(state['net'])
if __name__ == '__main__':
mode = 'best'
parser = argparse.ArgumentParser()
parser.add_argument('--savepath', default='./Base224L2/eff-b3', type=str)
parser.add_argument('--last', action='store_true')
args = parser.parse_args()
path = args.savepath
if args.last:
mode = 'last'
args = get_setting(path)
# print(args)
# model
model = BaseModel(model_name=args['model_name'], num_classes=int(args['num_classes']), \
pretrained=int(args['pretrained']), pool_type=args['pool_type'], down=int(args['down']), metric=args['metric'])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# device = torch.device('cpu')
model = model.to(device)
#加载预训练模型
load_pretrained_model(path, model, mode=mode)
size = 255
trans = transforms.Compose([
transforms.Resize((int(size / 0.875), int(size / 0.875))),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop((size, size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
submit = {'uuid': [], 'label': []}
TTA_times = 7
model.eval()
with torch.no_grad():
for i in range(0, 800):
img_path = 'test/%d.jpg' % i
raw_img = Image.open(img_path).convert('RGB')
results = np.zeros(49)
for j in range(TTA_times):
img = trans(raw_img)
img = img.unsqueeze(0).to(device)
out = model(img)
out = torch.softmax(out, dim=1)
_, pred = torch.max(out.cpu(), dim=1)
results[pred] += 1
pred = np.argmax(results)
print(i, ',', pred)
submit['uuid'].append(i)
submit['label'].append(pred)
#保存结果
df = pd.DataFrame(submit)
df.to_csv(os.path.join(path, 'result.csv'), encoding='utf-8', index=False, header=False)
ArtModel.py
搭建分类模型:resnext50/eff-b3
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
import math
import numpy as np
from efficientnet_pytorch import EfficientNet
import random
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return y
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, sz=(1,1)):
super().__init__()
self.ap = nn.AdaptiveAvgPool2d(sz)
self.mp = nn.AdaptiveMaxPool2d(sz)
def forward(self, x):
return torch.cat([self.mp(x), self.ap(x)], 1)
class GeneralizedMeanPooling(nn.Module):
def __init__(self, norm=3, output_size=1, eps=1e-6):
super().__init__()
assert norm > 0
self.p = float(norm)
self.output_size = output_size
self.eps = eps
def forward(self, x):
x = x.clamp(min=self.eps).pow(self.p)
return torch.nn.functional.adaptive_avg_pool2d(x, self.output_size).pow(1. / self.p)
def __repr__(self):
return self.__class__.__name__ + '(' \
+ str(self.p) + ', ' \
+ 'output_size=' + str(self.output_size) + ')'
#模型框架
class BaseModel(nn.Module):
def __init__(self, model_name, num_classes=2, pretrained=True, pool_type='max', down=True, metric='linear'):
super().__init__()
self.model_name = model_name
#eff-b3/resnext50
if model_name == 'eff-b3':
backbone = EfficientNet.from_pretrained('efficientnet-b3')
plane = 1536
elif model_name == 'resnext50':
backbone = nn.Sequential(*list(models.resnext50_32x4d(pretrained=pretrained).children())[:-2])
plane = 2048
else:
backbone = None
plane = None
self.backbone = backbone
#pool
if pool_type == 'avg':
self.pool = nn.AdaptiveAvgPool2d((1, 1))
elif pool_type == 'cat':
self.pool = AdaptiveConcatPool2d()
down = 1
elif pool_type == 'max':
self.pool = nn.AdaptiveMaxPool2d((1, 1))
elif pool_type == 'gem':
self.pool = GeneralizedMeanPooling()
else:
self.pool = None
if down:
if pool_type == 'cat':
self.down = nn.Sequential(
nn.Linear(plane * 2, plane),
nn.BatchNorm1d(plane),
nn.Dropout(0.2),
nn.ReLU(True)
)
else:
self.down = nn.Sequential(
nn.Linear(plane, plane),
nn.BatchNorm1d(plane),
nn.Dropout(0.2),
nn.ReLU(True)
)
else:
self.down = nn.Identity()
self.se = SELayer(plane)
self.hidden = nn.Linear(plane, plane)
self.relu = nn.ReLU(True)
if metric == 'linear':
self.metric = nn.Linear(plane, num_classes)
elif metric == 'am':
self.metric = AddMarginProduct(plane, num_classes)
else:
self.metric = None
def forward(self, x):
if self.model_name == 'eff-b3':
feat = self.backbone.extract_features(x)
else:
feat = self.backbone(x)
feat = self.pool(feat)
se = self.se(feat).view(feat.size(0), -1)
feat_flat = feat.view(feat.size(0), -1)
feat_flat = self.relu(self.hidden(feat_flat) * se)
out = self.metric(feat_flat)
return out
if __name__ == '__main__':
model = BaseModel(model_name='eff-b3').eval()
x = torch.randn((1, 3, 224, 224))
out = model(x)
print(out.size())
print(model)
vote.py
主干网络resnest200,输入448尺寸,在不同loss下取得5组最好效果,最后进行投票,得到最后分数。
import pandas as pd
import numpy as np
files = ['1.csv', '2.csv', '3.csv', '4.csv']
weights = [1, 1, 1, 1]
results = np.zeros((800, 49))
for file, w in zip(files, weights):
print(w)
df = pd.read_csv(file, header=None).values
for x, y in df:
# print(x, y)
results[x, y] += w
# break
print(results[0])
submit = {
'name': np.arange(800).tolist(),
'pred': np.argmax(results, axis=1).tolist()
}
for k, v in submit.items():
print(k, v)
df = pd.DataFrame(submit)
df.to_csv('vote.csv', header=False, index=False)