【jvm系列-08】精通String字符串底层原理和运行机制(详解)
JVM系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】初识虚拟机与java虚拟机 | https://blog.csdn.net/zhenghuishengq/article/details/129544460 |
| 【二】jvm的类加载子系统以及jclasslib的基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/129610963 |
| 【三】运行时私有区域之虚拟机栈、程序计数器、本地方法栈 | https://blog.csdn.net/zhenghuishengq/article/details/129684076 |
| 【四】运行时数据区共享区域之堆、逃逸分析 | https://blog.csdn.net/zhenghuishengq/article/details/129796509 |
| 【五】运行时数据区共享区域之方法区、常量池 | https://blog.csdn.net/zhenghuishengq/article/details/129958466 |
| 【六】对象实例化、内存布局和访问定位 | https://blog.csdn.net/zhenghuishengq/article/details/130057210 |
| 【七】执行引擎,解释器、JIT即时编译器 | https://blog.csdn.net/zhenghuishengq/article/details/130088553 |
| 【八】精通String字符串底层机制 | https://blog.csdn.net/zhenghuishengq/article/details/130154453 |
深入理解字符串底层机制
- 一,String的底层机制
-
- 1,String的基本特性
- 2,String的内存分配
- 3,String的基本操作
- 4,字符串的拼接操作
-
- 4.1,常量与常量的拼接在常量池
- 4.2,常量池中不会存在相同内容的常量
- 4.3,只有其中一个是变量,就存在堆中(重点)
- 4.4,调用intern方法,变量需要加入到字符串常量池中
- 5,字符串操作拼接底层
-
- 5.1,拼接符号出现变量底层逻辑
- 5.2,拼接操作和直接append操作比较
- 6,new String ()到底创建了几个对象(重点)
-
- 6.1,new String("ab")
- 6.2,new String("a") + new String("b")
一,String的底层机制
1,String的基本特性
String表示的是字符串,用一对 “” 引起来表示,String被声明为final对象,表示不可被继承,并且实现了序列化Serializable和Comparable等接口
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
创建字符串的方式有以下几种
//字面量的方式定义
String name1 = "zhenghuisheng";
//创建对象的方式
String name2 = new String("zhenghuisheng");
在JDK8版本中,使用的是char字符数组的方式实现这个String类型的字符串,在JDK9版本开始,实现这个String字符串的方式是使用这个byte数组实现。在官网https://openjdk.org/jeps/254 ,详细的讲述了为啥要用byte替换这个char的理由,其动机如下:
The current implementation of the
Stringclass stores characters in achararray, using two bytes (sixteen bits) for each character. Data gathered from many different applications indicates that strings are a major component of heap usage and, moreover, that mostStringobjects contain only Latin-1 characters. Such characters require only one byte of storage, hence half of the space in the internalchararrays of suchStringobjects is going unused.
主要意思就是char字符中,每个字符占2个字节16位,而实际上String中存储的东西每个字符只占一个字节空间大小,这样就存在一半的空间给浪费掉,因此直接使用这个byte数组代替这个char类型的数组。
String代表不可变的字符序列,简称不变性。当对字符串重新赋值时、对现有的字符串操作时、当调用String的repalce方法修改字符或者字符串时,都需要重新指定区域赋值,不能使用原有的value进行赋值。字面量的方式给一个字符串赋值,此时的字符串声明在字符串常量池中。
//二者的地址相同,这两个变量都存在字符串常量池中
//jdk7开始字符串常量池在堆中,并且常量池中的常量不能重复
String username = "lisi";
String name = "lisi";
//重新赋值
username = "zhangsan";
//操作新字符串
name = name + username;
//replace替换
String replaceName = username.Replace('u',"i");
接下来了解一道笔试题,本人至今还有印象,好像是当时找实习的时候,好像还做错了当时…哭死
/**
* @author zhenghuisheng
* @date : 2023/4/13
*/
public class StringTest {
String str = new String("good");
char ch[] = {'t','e','s','t'};
public void change(String str,char ch[]){
str = "test ok";
ch[0] = 'b';
}
public static void main(String[] args) {
StringTest stringTest = new StringTest();
stringTest.change(stringTest.str,stringTest.ch);
System.out.println("str的值为:" + stringTest.str); //good
System.out.print("ch的值为:");
System.out.println(stringTest.ch); //best
}
}
上述代码打印出来的结果如下,这道题主要考察的是String字符串的不可变性,因此String的值还是原来的good
str的值为:good
ch的值为:best
字符串常量池不会存储相同内容的字符串,其内部实现和这个set一样,其实现原理主要是通过这个Map实现的,String的String Pool是一个固定大小的HashTable ,其默认值大小长度为60013,也可以通过这个-XX:StringTableSize 来设置具体的StringTable的长度,但是最小值不能设置小于1009。
-XX:StringTableSize=1009
如果放进这个String pool的String非常多,就会造成这个Hash冲突非常严重,从而就会导致内部的链表非常的长,其HashTable底层就是数组加链表实现,造成的影响就是调用这个String.intern是性能会大幅下降。
2,String的内存分配
Java语言中有8大基本数据类型和一种比较特殊的类似String,这些类型为了使他们在运行过程中速度更快,更加的节省内存,因此在JVM内部,提供了一种常量池的概念。这个常量池和缓存的概念一致,8中基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊,他的使用方法主要有如下两种
//直接通过双引号声明出来的String对象会直接存储在常量池中
String info = "zhenghuisheng";
//也或者是String提供的itern()方法
String.intern();
在JDK6时,字符串常量池是存储在方法区,当时实现方法区的方式是永久代
从JDK7开始,字符串常量池存储在堆里面,因此所有的字符串都保存在堆里面,和其他的普通对象一样,这样在调优时,只需要调整对应的堆大小即可。之所以没有存储在方法区的原因,一方面是因为方法区给的空间太小,不足以存储这么多的变量,另一方面是因为这个方法区的GC频率不高,因此存放在堆里面,空间大,回收频率高。
在JDK8开始时,实现方法区的方式从永久代变成元空间,使用的是本地内存,但是出门这个字符串常量池和这个静态变量都还是存储在堆中,其理由想必个JDK7一样。
由于本人目前只有这个JDK8的环境,因此演示一下这个这个字符串常量池到底是存储在哪里,如查看以下这段代码
/**
* -XX:MetaspaceSize=6m -XX:MaxMetaSpaceSize=6m -Xms6m -Xmx6m -XX:-UseGCOverheadLimit
* @author zhenghuisheng
* @date : 2023/4/13
*/
public class Jvm04 {
public static void main(String[] args) {
//使用set将变量引用,防止出现gc
Set<String> set = new HashSet<>();
int i = 1;
while(true){
//调用native方法intern,将变量加入到字符串常量池中
set.add(String.valueOf(i++).intern());
}
}
}
设置的堆和元空间的初始大小和最大大小如下,然后添加到虚拟机参数中
-XX:MetaspaceSize=6m -XX:MaxMetaspaceSize=6m -Xms6m -Xmx6m -XX:-UseGCOverheadLimit
可以发现报出的异常是,Java heap space ,堆空间发生了OOM,足以说明这个字符串存储在字符串常量池中,而字符串常量池存储在堆中。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.lang.Integer.toString(Integer.java:401)
at java.lang.String.valueOf(String.java:3099)
at com.zhs.study.test.Jvm04.main(Jvm04.java:17)
3,String的基本操作
接下来再来验证一下这句话,字符串常量池中相同的值不能重复,接下来查看这段代码,并且以debug的方式运行,然后打开右下角的memory,点击loadClass加载类信息
public class Jvm04 {
public static void main(String[] args) {
System.out.println("开始创建变量");
System.out.println("100001"); //字符串总个数2658,不包含当前这个
System.out.println("100002");
System.out.println("100003");
System.out.println("100004"); //2661
//以下相同的字符串不会加入到字符串常量池中
System.out.println("100004"); //2662
System.out.println("100004"); //2662
}
}
在第二行处打一个断点,然后加载memory的class信息,可以发现这个此时的java.lang.String的字符串常量池的个数为2658,此时还不包括100001这个值
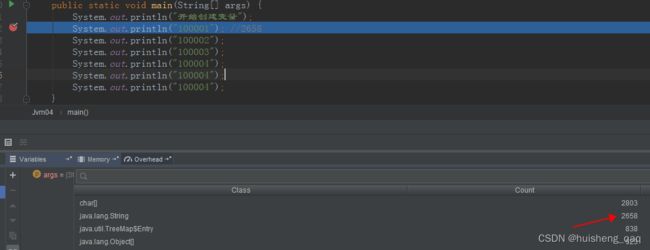
然后一直到10004这里,字符串加三个,字符串常量池的总数为2661,此时总数还不包括这个100004
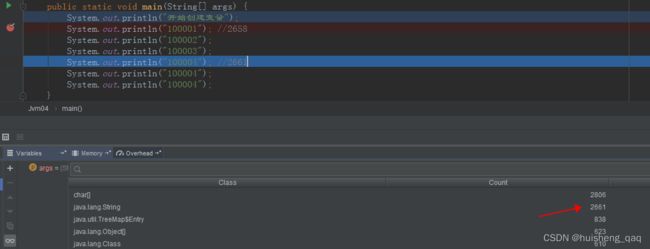
然后第一次加上这个10004之后,字符串的总数为2662,后面再添加这个100004,发现字符串常量池中的总数不变。
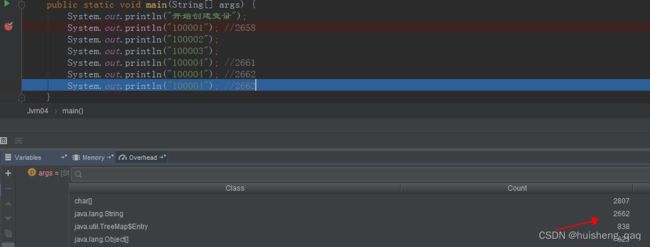
在JAVA语言规范里:要求完全相同的字符串字面量,应该包含同样的Unicode字符序列,并且必须是指向同一个String类的实例
4,字符串的拼接操作
4.1,常量与常量的拼接在常量池
接下来一段代码演示,定义两个变量s1和s2,一个拼接一个合在一起
public static void main(String[] args) {
//可以通过反编译文件查看这个s1="abc"
String s1 = "a" + "b" + "c";
//存储在字符串常量池中,将此地址赋值给s1
String s2 = "abc";
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
其结果为
true
true
无论是通过反编译文件还是通过这个jclasslib,都可以发现这个s1的值就是abc,直接在编译阶段就优化好了,那么就会将abc这个变量加载到字符串常量池中,然后s2发现这个字符串常量池中已有这个abc,因此s2只需要将指针指向这个abc对应的地址即可。这样s1和s2的值和指向的地址都一样,所以都为true。
4.2,常量池中不会存在相同内容的常量
这个依旧可以用以下这个例子举例,后面发现已经存在就不会继续往常量池中添加
public class Jvm04 {
public static void main(String[] args) {
System.out.println("开始创建变量");
System.out.println("100001"); //字符串总个数2658,不包含当前这个
System.out.println("100002");
System.out.println("100003");
System.out.println("100004"); //2661
//以下相同的字符串不会加入到字符串常量池中
System.out.println("100004"); //2662
System.out.println("100004"); //2662
}
}
或者用4.1这个例子,发现已经存在的话只需将地址引用即可。
4.3,只有其中一个是变量,就存在堆中(重点)
拼接符号的前后出现了变量,相当于在堆空间new String()。接下来再举一个例子,是一个高频常见的面试题,其代码如下。(详情看代码上面的注释,看完必会)
public class Jvm04 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "World";
String s3 = "helloWorld";
String s4 = "hello" + "World";
String s5 = s1 + "World";
String s6 = "hello" + s2;
String s7 = s1 + s2;
//true 和4.1的原理一样,属于编译器优化,都是指向同一个地址
System.out.println(s3 == s4);
//false 拼接符号的前后出现了变量,相当于在堆空间new String
//那么s5就是直接存在堆空间中,s3存储在字符串常量池中,地址不相等
System.out.println(s3 == s5);
//false s6拼接了变量,指向的是堆空间 s3指向的是字符串常量池,地址不相等
System.out.println(s3 == s6);
//false s7拼接了变量,指向的是堆空间 s3指向的是字符串常量池,地址不相等
System.out.println(s3 == s7);
//false s5,s6,s7都拼接了新的变量,都会在堆空间开辟新的地址
System.out.println(s5 == s6);
//false
System.out.println(s5 == s7);
//false
System.out.println(s6 == s7);
}
}
4.4,调用intern方法,变量需要加入到字符串常量池中
再举个例子,其代码如下,将堆中的字符串加入这个intern方法
public class Jvm04 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "helloWorld";
String s3 = s1 + "World";
String s4 = s3.intern();
System.out.println(s2 == s4);
}
}
可以发现其结果为true。在调用这个方法之后,会先去判断字符串常量池中是否存在当前变量的值,如果存在,则返回常量池中的地址即可,如果不存在,则将当前值新加入到常量池中,并将对象的地址返回。
5,字符串操作拼接底层
5.1,拼接符号出现变量底层逻辑
在上文中谈到:拼接符号的前后出现了变量,相当于在堆空间new String。接下来通过具体的举例来证明
public class Jvm04 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "World";
String s3 = "helloWorld";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
}
这里出现了s1 + s2的操作,因此通过jclasslib查看此类的字节码文件,其内容如下
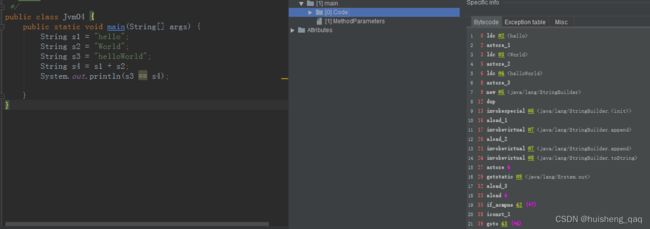
其对应的code字节码如下,首先就是s1,s2,s3先加载到局部变量表中
0 ldc #2 <hello>
2 astore_1
3 ldc #3 <World>
5 astore_2
6 ldc #4 <helloWorld>
8 astore_3
9 new #5 <java/lang/StringBuilder>
12 dup
13 invokespecial #6 <java/lang/StringBuilder.<init>>
16 aload_1
17 invokevirtual #7 <java/lang/StringBuilder.append>
20 aload_2
21 invokevirtual #7 <java/lang/StringBuilder.append>
24 invokevirtual #8 <java/lang/StringBuilder.toString>
27 astore 4
29 getstatic #9 <java/lang/System.out>
32 aload_3
33 aload 4
35 if_acmpne 42 (+7)
38 iconst_1
39 goto 43 (+4)
42 iconst_0
43 invokevirtual #10 <java/io/PrintStream.println>
46 return
接下来主要分析s4,会先new一个StringBuilder,然后将局部变量表中对应的s1、s2的值加载出来,通过这个append方法加入到这个StringBuilder中,最后toString转成字符串,用一段伪代码来表示如下
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(s1);
stringBuilder.append(s2);
//转成字符串,toString的内部相当于new String()
stringBuilder.toString();
最后再将这个变量加入到局部变量表中,经历了这么多步骤,而且最终是存储在堆中,因此这个对象和直接存储在字符串常量池中的对象肯定是不相等的。所以最终结果为true。
当然也不是所有的这种变量直接相加就会变成这个堆中的对象,也可以将变量变为常量,如通过 final 这个字符修饰,那么最终的结果还是加载字符串常量池中。如下段代码,可以发现这个结果直接为true。
public class Jvm04 {
public static void main(String[] args) {
//静态变量在准备阶段进行默认初始化
//加final的字段在准备阶段直接显示初始化
final String s1 = "hello";
final String s2 = "World";
String s3 = "helloWorld";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
}
5.2,拼接操作和直接append操作比较
接下来直接通过一段代码来比较,直接拼接字符串和这个StringBuilder之间的差距,肉眼可见不是一个级别的,差距是在是过大,StringBuilder的append花费的时间是远远小于这个拼接字符串的时间。
/**
* @author zhenghuisheng
* @date : 2023/4/13
*/
public class Jvm04 {
public static void main(String[] args) {
long start = System.currentTimeMillis();
//4974ms
strAdd(100000);
//8ms
//strAppend(100000);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
public static void strAdd(Integer time){
String data = "";
for (int i = 0; i < time ; i++) {
//每次循环都会创建一个StringBuilder和String
data = data + "a";
}
}
public static void strAppend(Integer time){
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < time; i++) {
stringBuilder.append("a");
}
}
}
主要原因是每字符串拼接一次,就需要创建一个StringBuilder对象,在toString的时候,还需要创建一个String对象,其耗时程度远远高于这个这个StringBuilder的耗时。并且创建过多的这个StringBuilder和String,需要触发GC将之前不用的对象清除。
因此建议在平常时开发中,能避免这种直接操作字符串的,就尽量避免,而是改用这种StringBuilder来代替。并且如果可以确定前前后后添加的字符串长度不会高于某个值,则可以使用以下的这种方式去创建StringBuilder
//避免不断扩容所带来的消耗
StringBuilder stringBuilder = new StringBuilder(highLevel);
6,new String ()到底创建了几个对象(重点)
6.1,new String(“ab”)
在通过这个new String()到底创建了几个对象,也是在笔试或者面试中,高频的问题。如下这段代码,到底会创建几个对象
/**
* @author zhenghuisheng
* @date : 2023/4/14
*/
public class Jvm05 {
public static void main(String[] args) {
String str = new String("ab");
}
}
为了具体的知道到底是创建了几个对象,因此可以对其字节码文件进行分析,如下
0 new #2 <java/lang/String>
3 dup
4 ldc #3 <ab>
6 invokespecial #4 <java/lang/String.<init>>
9 astore_1
10 return
结果显而易见,创建了两个对象! 在程序计数器为0时,在堆中通过new创建了一个String对象,然后在程序计数器为4时,在字符串常量池中创建了这个 “ab” 对象,最后进行一个初始化和一个赋值操作,最后返回。
但是上面也说了,字符串常量池中的对象不能重复,也就是说,如果这个ab在创建之前就已经存储在这个字符串常量池中,那么就不会再创建 “ab” 这个对象,而是直接进行地址的引用。因此总结来说,应该是一个或者两个,主要是看字符串常量池中是否存在这个要创建的对象
6.2,new String(“a”) + new String(“b”)
上面这个也许比较好分析,在有了上面这段代码的了解之后,接下来再分析一段代码,查看一下这段代码中这个new String 创建了几个对象
/**
* @author zhenghuisheng
* @date : 2023/4/14
*/
public class Jvm05 {
public static void main(String[] args) {
String str = new String("a") + new String("b");
}
}
接下来再分析这段代码的字节码文件,如下
0 new #2 <java/lang/StringBuilder>
3 dup
4 invokespecial #3 <java/lang/StringBuilder.<init>>
7 new #4 <java/lang/String>
10 dup
11 ldc #5 <a>
13 invokespecial #6 <java/lang/String.<init>>
16 invokevirtual #7 <java/lang/StringBuilder.append>
19 new #4 <java/lang/String>
22 dup
23 ldc #8 <b>
25 invokespecial #6 <java/lang/String.<init>>
28 invokevirtual #7 <java/lang/StringBuilder.append>
31 invokevirtual #9 <java/lang/StringBuilder.toString>
34 astore_1
35 return
很明显,在程序计数器为0的时候,创建了一个StringBuilder对象,程序计数器为7的时候,创建了一个String对象,接着就是在程序计数器为11的时候创建字符串常量池中a对象,然后将这个对象拼接在StringBuilder中,程序计数器为19的时候,在堆中又创建了一个String对象,程序计数器为23的时候,在字符串常量池中创建了一个b对象,然后将对象拼接在StringBuilder中,后面toString又要在堆中创建一个String对象。
这里详细的说一下这个toString的底层,其源码如下,其内部就是一个new String()的对象,只是调用了这个String的不同构造器。
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
因此通过上述分析,假设a,b在字符串常量池中都不存在,则创建了六个对象,如果在堆中全部存在或者部分存在,则创建了4个或者5个对象,因此可能创建了四个到六个对象。