Python从入门到精通5天(Python字符串的使用)
Python字符串的使用
- 字符串
- 转义字符的使用
- 字符串的切片
- 字符串的格式化输出
- 处理字符串
- 练习
字符串
所谓字符串,就是由零个或多个字符组成的有限序列。在Python程序中,不区分单双字符,我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。
s1 = 'hello, world!'
s2 = "hello, world!"
# 以三个双引号或单引号开头的字符串可以折行
s3 = """
hello,
world!
"""
print(s1, s2, s3, end='')
输出如下:

这时能说明我们三个引号的字符串的输出跟我们写个格式是一样的,进行换行的输出,当然我们也可以利用转移字符进行输出:
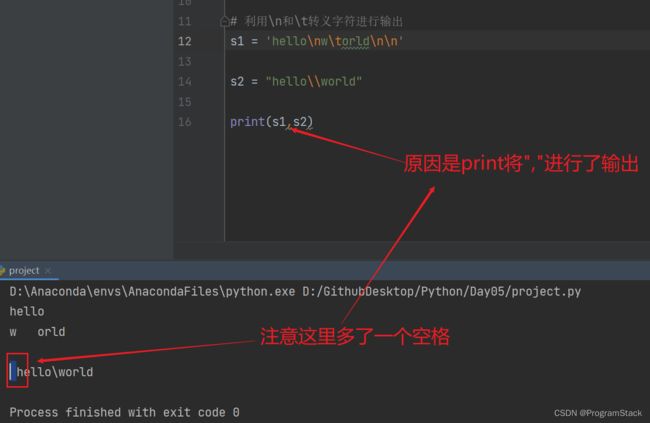
# 利用\n和\t转义字符进行输出
s1 = "hello\nw\torld"
print(s1)
输出结果:
转义字符的使用
字符串中使用\(反斜杠)来表示转义,\n表示换行;而\t表示制表符。所以如果想在字符串中表示'要写成\',同理想表示\要写成\\。
当然我们也可以在字符串前加上字母r,这里表示按照原来的意思进行输出,例如r"h\nello"它的输出为h\nello。
print(r'h\nello')
# 输出为h\nello
Python为字符串类型提供了非常丰富的运算符,我们可以使用+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串。
# 使用 + 号来进行
s1 = '152'
s2 = '215'
print(s1+s2) # 152215
s1 += s2
print(s1) # 152215
# 以上 + 和 += 输出的结果都是一样的,那么我们用哪个好一点呢
# 当然是 +=
# 因为使用s1+s2创建一个新的对象
# 而使用 += 时并没有创建新的对象
# 用 * 来输出
print(3*s2)
# 判断字符或字符串是否在字符串中
print('15' in s1)
print('g' not in s2)
字符串的切片
字符串的切片跟C语言中的去元素下标是一样的道理,都是用[]进行相应的操作,她的具体格式可以表示为string[start:end:step],下标都是从0开始,start表示起始下标,end表示结束下标,step表示步长。
str2 = 'jhjlhlk'
# 表示从第二个元素开始,到四个元素结束,步长为2
print(str2[1:3:2]) # h
字符串的格式化输出
- %占位符进行格式化输出
a, b = 4, 20
# 输出 4 * 20 = 80
print('%d * %d = %d' % (a, b, a * b))
- srt.format()的格式化输出
a, b = 4, 20
# 输出 4 * 20 = 80
print('{0} * {1} = {2}'.format(a, b, a * b))
- f-String格式化输出:
a, b = 4, 20
# 输出 4 * 20 = 80
print(f'{a} * {b} = {a * b}')
处理字符串
Python还提供了一系列处理字符串的方法:
len():计算字符串的长度
capitalize():将字符串的首字母进行大写操作
title():将字符串的每个字母的首字母进行大写操作
upper():将字符串的每个字母大小
lower():将字符串的每个字母小写
index():根据写入的字符串第一个首字母查找源字符串的索引,没有找到则返回异常
find():查找子串的位置
startswith():判断字符串是否以指定的字符串开头
endswith():判断字符串是否以指定的字符串结尾
center():指定宽度并居中,还可以在两边填充字符
rjust():指定宽度靠右,可以填充指定字符
ljust():指定宽度靠左,可以填充指定字符
isdigit():判断字符串是否由数字构成
isalpah():判断字符串是否以字母构成
isalnum():判断字符串是否以数字和字母构成
strip():将字符串两边的空格进行删除
练习
设计一个函数返回给定文件名的后缀名
def get_suffix(filename, has_dot=False):
"""
获取文件名的后缀名
:param filename: 文件名
:param has_dot: 返回的后缀名是否需要带点
:return: 文件的后缀名
"""
pos = filename.rfind('.')
if 0 < pos < len(filename) - 1:
index = pos if has_dot else pos + 1
return filename[index:]
else:
return "没有找到"