「Hive」协同过滤推荐系统-余弦相似度
前言:
写这文时2021年不知不觉只剩3个月了,想必在抖音快手短视频、淘宝京东购物、饿了么美团外卖横行的年代,推荐算法这个词想必大家不陌生吧?(陌生的评论区扣1,我根本不信)
- 我在几年前就卸载了抖音,因为时常一刷刷几个小时,根本控制不住…
- 淘宝上给弟弟买的衣服多了,首页猜我喜欢的全是T恤大裤衩,导致我这个夏天的穿衣风格很不对劲…
- 有段时间减肥用饿了么点轻食,几天之后我的食物列表里全是轻食,当轻食吃腻了就有种再也不想打开饿了么的冲动…
对,以上这些生动案例都是基于强大的推荐系统。(以下划线内容请大家熟读并背诵)
推荐系统本质是一个信息过滤系统,它基于用户数据、用户行为数据和商品内容信息并通过一定的算法来预测用户的偏好,根据用户的偏好特点来过滤掉用户不感兴趣的商品或内容,从而不断吸引用户留在产品上。
推荐系统有多种,比如基于人口统计学的推荐、基于内容推荐、基于协同过滤推荐和混合推荐等。今天讲协同过滤推荐系统。
- 基于用户的协同过滤,比如用户A与用户C相似,则给用户A推荐C买过但A没买的商品。
- 基于商品的协同过滤,比如商品1和商品2相似,则用户A购买商品1后,会再给其推荐商品2。(我的T恤大裤衩就是这么买来的)
学前温馨提示:
学习过程中可能会出现“大脑说我会了,手说你会你来呀“这种情况,理解和写出来还是不太一样的,我也是花了三四天时间学习消化的,不会就多学几遍,耐心往下看,实在看不懂那也是因为我没写好,不是你的问题~欢迎点赞评论。
内容太干了,推荐给大家我最近爱喝的茶百道·手剥葡萄冻,趁这几天还有大太阳赶紧喝。(我知道没一杯奶茶你们是看不完的,我真的人美心善)
一、什么是协同过滤
协同过滤推荐(Collaborative Filtering recommendation):分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
分为以下3类:

此图认真看,今天主要是讲基于用户和基于商品的协同过滤推荐。 计算步骤均为:1.计算评分 2.计算相似度 3.计算喜爱度
二、基于用户的协同过滤

(你买我也买)
上图解读:
1)用户A购买商品1、2,用户C购买商品1、2、4,可见用户A与用户C购买商品的相似度很高,如果要推荐给用户A,则可推荐其未购买过的商品4。
2)用户B购买商品3和4,而用户A购买商品1和2,可以说这俩人相似度为0,再看用户C购买了商品1、2、4,跟用户B共同购买了商品4,则可以按照用户C的购买推荐用户B商品1或者商品2。
3)一共4个商品,用户C买了3个,最后只剩商品3可以推荐了。
以下是计算方法:
1.计算评分
首先准备好相关数据:用户、商品和相应的评分。 该评分可根据用户对商品的几个关键指标计算得到。 [例如评分=商品浏览次数1+加购次数2+购买次数*3]
示例数据源:
为便于理解,展示数据【表1】如下:

2.计算相似度
相似度计算方式有很多,本文使用余弦相似度。

看到这里先别慌,看下面用Excel计算的公式,不难理解
结合表1和以上公式,用户余弦相似度计算结果如下:

【表2】Excel举例,先把用户与用户组合枚举出来,再分别计算
用户A与用户B的相似度=(50+10+04.5+03)/(SQRT(52+12+02+02)*SQRT(02+02+4.52+32))
用户A与用户C的相似度=(51+14+00+04)/(SQRT(52+12+02+02)*SQRT(12+42+02+42))
用户B与用户C的相似度=(01+04+4.50+34)/(SQRT(02+02+4.52+32)*SQRT(12+42+02+42))
(sqrt是开根号的函数)
3.计算喜爱度
结合表1和表2,计算用户没购买过商品的喜爱度如下:
用户A对商品3的喜爱度=用户A与用户B的相似度用户B对商品3的评分+用户A与用户C的相似度用户C对商品3的评分=04.5+0.3072549340=0
用户A对商品4的喜爱度=用户A与用户B的相似度用户B对商品4的评分+用户A与用户C的相似度用户C对商品4的评分=03+0.3072549344=1.22901974
用户B对商品1的喜爱度=用户B与用户A的相似度用户A对商品1的评分+用户B与用户C的相似度用户C对商品1的评分=05+0.386243641=0.38624364
用户B对商品2…= 1.54497456
用户C对商品3…=1.73809638
【表3】用户协同-结果数据

三、基于商品的协同过滤
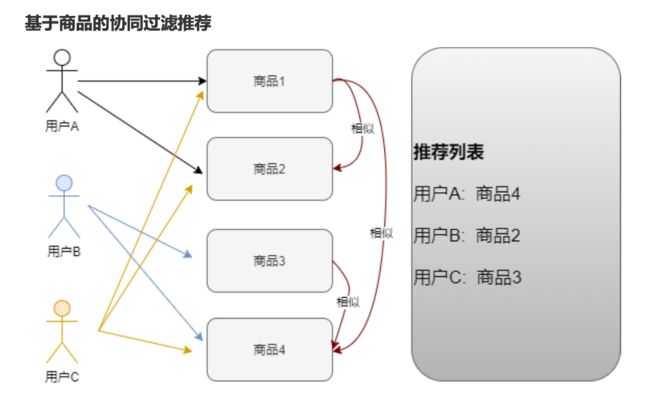
(猜我喜欢)
1.计算评分
示例数据源展示结果【表4】如下:

2.计算相似度

结合表4和以上公式,商品余弦相似度计算结果如下:

【表5】把商品和商品组合枚举出来,再分别代入公式计算
商品1与商品2的相似度=(51+00+1*4)/(SQRT(52+02+12)*SQRT(12+02+42))=0.428086345
商品1与商品3的相似度=(50+04.5+1*0)/(SQRT(52+02+12)*SQRT(02+4.52+02))=0
其它同理…
3.计算喜爱度
结合表4和表5,计算用户没购买过商品的喜爱度如下:
用户A对商品3的喜爱度=商品1与商品3的相似度用户A对商品1的评分+商品2与商品3的相似度用户A对商品1的评分+商品4与商品3的相似度用户A对商品4的评分=05+01+0.60=0
用户A对商品4的喜爱度=商品1与商品4的相似度用户A对商品1的评分+商品2与商品4的相似度用户A对商品1的评分+商品3与商品4的相似度用户A对商品4的评分=0.1568929085+0.7761141+0.60=1.560578541
用户B对商品1的喜爱度=商品1和商品2的相似度用户B对商品2的评分+商品1和商品3的相似度用户B对商品3的评分+商品1与商品4的相似度*用户B对商品4的评分=…
其它同理…
【表6】商品协同-结果数据

四、SQL实现(基于商品的协同过滤)
到这里可能有人问了,标题上写的Hive,为啥这里直接SQL实现了?
答:一般协同过滤的数据量会比较多,一般是在Hive里进行实现的,但我这里示例数据量比较小,而HQL和MySQL写法差不多,所以直接navicat写SQL实现啦,方便。
1.导入数据源
体现用户、商品和评分三个字段,这里咱们还是用示例数据源user_item表。
SELECT * FROM user_item;

user_item:数据源你们就自己造吧,记得跟我的字段名和表名保持一致,方便后面复制代码
2.求出Ai * Bi, Ai * Ai, Bi * Bi
通过用户关联,得到商品之间的关系
SELECT a.user_name,a.item_id,a.grade,b.item_id as item_id2,b.grade as grade2
FROM user_item a
INNER JOIN user_item b on a.user_name = b.user_name;

这样就把每个用户的商品组合起来了
求出Ai * Bi, Ai * Ai, Bi * Bi
# 为了便于后面计算创建视图,在Hive里写时可创建表
CREATE VIEW user_item_item2 AS
SELECT a.user_name,a.item_id,b.item_id as item_id2,a.grade * b.grade as pre
FROM user_item a
INNER JOIN user_item b on a.user_name = b.user_name;
user_item_item2
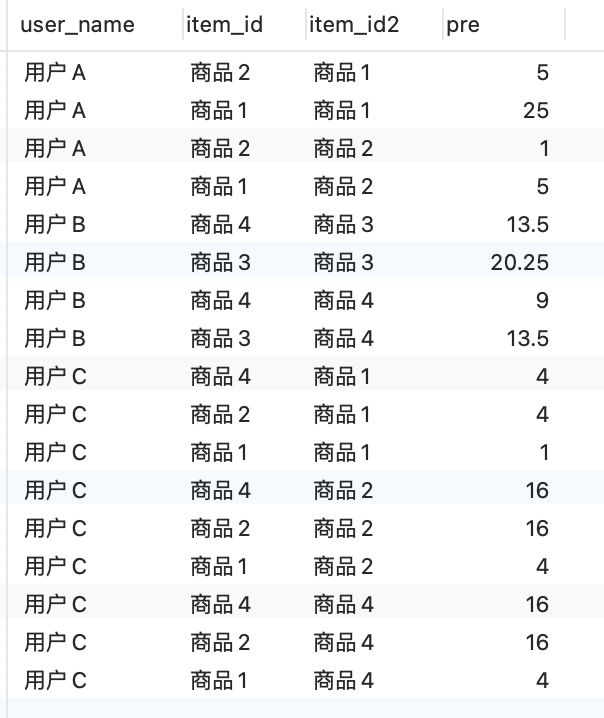
3.对其求和:sum(Ai * Bi), sum(Ai * Ai), sum(Bi * Bi)
CREATE VIEW item_item2_pre AS
SELECT a.item_id,a.item_id2,sum(a.pre) as pre
FROM user_item_item2 a
GROUP BY a.item_id,a.item_id2;
item_item2_pre
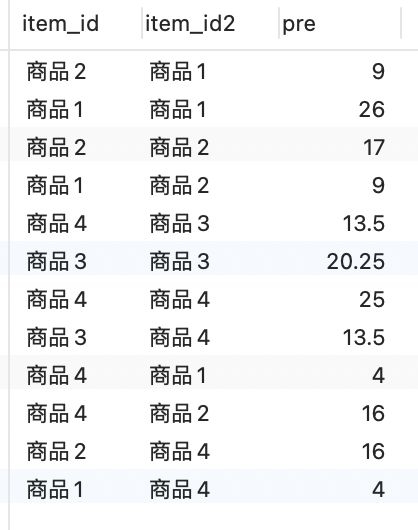
4.计算相似度 = sum(Ai * Bi) / (sqrt(sum(Ai * Ai)) * sqrt(sum(Bi * Bi)))
把Ai * Ai以及Bi * Bi单独做一列,方便横向计算
CREATE VIEW item_item2_correl AS
SELECT
a.item_id,
a.item_id2,
a.pre as ab_pre, # sum(Ai * Bi)
b.pre as aa_pre, # sum(Ai * Ai)
c.pre as bb_pre, # sum(Bi * Bi)
a.pre/sqrt(b.pre * c.pre) as correl # 这就是相似度本度
FROM item_item2_pre a
INNER JOIN item_item2_pre b on a.item_id = b.item_id and a.item_id = b.item_id2
INNER JOIN item_item2_pre c on a.item_id2 = c.item_id and a.item_id2 = c.item_id2
item_item2_correl

5.计算喜爱度
将相似度表item_item2_correl代入到数据源表user_item中先看看数据
SELECT a.user_name,b.item_id2,a.grade,b.correl
FROM user_item a
INNER JOIN item_item2_correl b on a.item_id = b.item_id

计算用户对商品的喜爱度= sum(评分 * 相似度) = sum(grade * correl)
CREATE VIEW item_col AS
SELECT a.user_name,b.item_id2,sum(a.grade * b.correl) as col
FROM user_item a
INNER JOIN item_item2_correl b on a.item_id = b.item_id
GROUP BY a.user_name,b.item_id2;
item_col

6.最后一步:剔除用户之前买过的商品数据(只推荐没买过的),并按照喜爱度降序,给每个用户只推一个商品
SELECT * FROM(
SELECT
a.*,
# 按照喜爱度降序
row_number()over(partition by a.user_name order by col desc ) as rk
FROM item_col a
# 只推荐没买过的(买过的剔除)
WHERE concat(a.user_name,a.item_id2) not in (SELECT concat(user_name,item_id) FROM user_item )
) a
# 每个用户只推荐一个商品
WHERE a.rk = 1
基于商品协同:结果数据

看到这里是不是人傻了…
大脑:我会了 手:你会你来呀
记不住的话多看看原理,拿着案例数据先做一遍,再敲一遍代码,不信你不会
无他,唯手熟尔
补充知识点:相似度的计算方法

余弦相似度和Jaccard相似度的区别:
- 余弦相似度是根据评分高低来计算,比如购买次数,买的多则评分高;
- Jaccard相似度不体现评分的高低,只看是否发生购买行为,1代表购买,0代表未购买,因此不能体现程度。
课后作业:用SQL实现基于用户的协同过滤