(1)个人使用小爬虫---------关于一次被论坛封号而搜索的思考
前段时间上了某论坛的技术讨论区,习惯性的打开搜索看有没有我需要的内容,一登陆账号,发现自己被禁言了,连基本的搜索功能也被限制了。无奈只能手动的一个一个会找帖子。我去,竟然有200多页,每页有40第数据,这样纯手工的方式实在是太蛋疼了。
前段时间自己不是写了一个小爬虫吗?于是我的个人论坛搜索器开始构建了。
一,整体构建
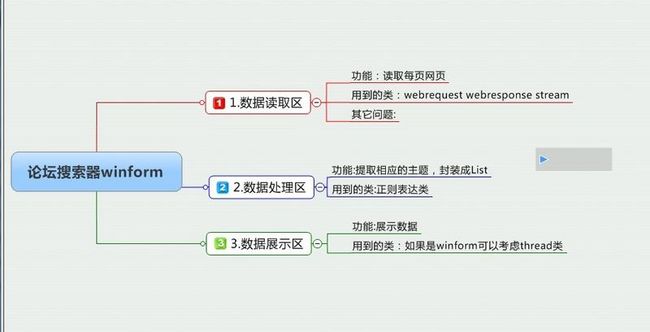
二,实际编码
1,数据读取编码:
读取网页有很多种方法,第一读取网页我选择的是最简单的方式
static string GetPage(int page)
{
string reuslt = string.Empty;
System.Net.WebClient wb = new System.Net.WebClient();
reuslt = wb.DownloadString("http://xx.xxx.xx/thread0806.php?fid=7&search=&page=" + page);
return reuslt;
}
直接利用webclient 读取内容:

咦,这是怎么回事?
直接访问是不可以的,哪里出错了呢?
难不成是地址出错了?我重新检查了一次没有拼错,那换成其它地址呢?

测试可以使用,那就是说这种请求方式只对百度有效。
那说明:直接使用webClinent类来请求xx.xxx.xx这种网站是不可行的,因为它会来接收你的请求头的信息来判断是人工发出的请求还是非人工发出的请求。
如何构造请求头是关键!
那换用另一种方式来请求来,如果要构建新的请求方式,那首先要明白,一次“人工的请求方式”应该是怎么样的,打开chrome,监视了一次请求,得到结果如下:
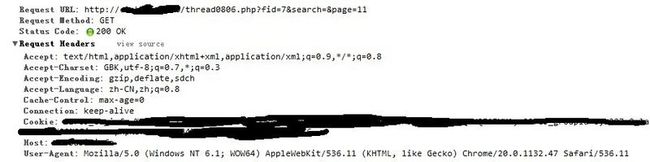
一次合理的请求方式包含哪些信息呢?
url:请求地址
Method:请求方式
Headers:
Accept:本次请求得到的回应的数据格式,版本
Accept-Charset:我这次请求可以接受的编码格式 GBK,UTF-8;q=0.7
Accept-Encoding:编码格式(gzip格式)
Accept-Language:中文
Cache-Control:缓存设置
User-Agent:请求标识头部分
OK,这些既然得到了,那可以开始构建一次正常的请求了。
static string Getpage(int page) { System.IO.Stream response; System.IO.StreamReader sr; string result = string.Empty; string domain = "http://xx.xxx.xx/thread0806.php?fid=7&search=&page=" + page; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(domain); request.Method = "GET"; request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"; request.Headers.Set("Accept-Charset", "GBK,utf-8;q=0.7,*;q=0.3"); request.Headers.Set("Accept-Language", "zh-cn,zh;q=0.5"); request.Headers.Set("Accept-Encoding", "gzip,deflate,sdch"); request.Host = "xx.xxx.xx"; request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.47 Safari/536.11"; request.KeepAlive = true; HttpWebResponse httprp = (HttpWebResponse)request.GetResponse(); httprp.Headers.Set("Content-Encoding", "gzip"); response = httprp.GetResponseStream(); sr = new System.IO.StreamReader(response,Encoding.UTF8); result = sr.ReadToEnd(); response.Close(); sr.Close(); return result; }
OK,那测试一下看得到数据没有.
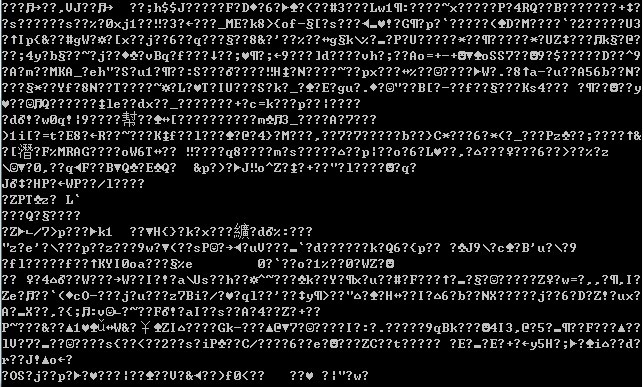
怎么都是乱码呢?
设置读取的时候都是正常的UTF-8编码,如果读取的编码没有问题,那问题应该出在传送的编码上面。我竟然忽略了返回的格式了
httprp.Headers.Set("Content-Encoding", "gzip");
很明显,文档经过了Gzip格式进行压缩,然后在传送过来了,那需要解码一次:代码如下
static string Getpage(int page)
{
System.IO.Stream response;
System.IO.StreamReader sr;
string result = string.Empty;
string domain = "http://xx.xxx.xx/thread0806.php?fid=7&search=&page=" + page;
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(domain);
request.Method = "GET";
request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.Headers.Set("Accept-Charset", "GBK,utf-8;q=0.7,*;q=0.3");
request.Headers.Set("Accept-Language", "zh-cn,zh;q=0.5");
request.Headers.Set("Accept-Encoding", "gzip,deflate,sdch");
request.Host = "xx.xxx.xx";
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.47 Safari/536.11";
request.KeepAlive = true;
HttpWebResponse httprp = (HttpWebResponse)request.GetResponse();
httprp.Headers.Set("Content-Encoding", "gzip");
response = httprp.GetResponseStream();
//重新修改后的代码
sr = new System.IO.StreamReader(new GZipStream(response, CompressionMode.Decompress), Encoding.GetEncoding("gb2312"));
result = sr.ReadToEnd();
response.Close();
sr.Close();
return result;
}
那得到结果没有呢?
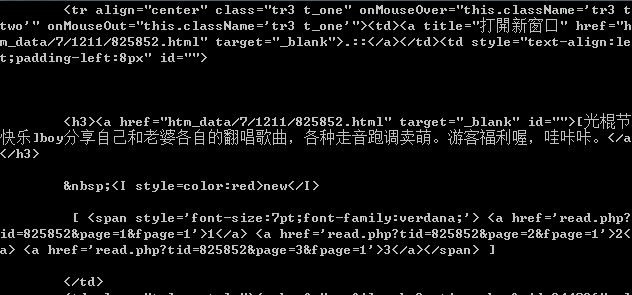
OK,正常得到结果!那下面的工作就简单了~
PS:晚上继续更新第二部分,(数据展示内容---正则表达式的应用)