ASCII码表字母大小写相差32的原因分析
思考起因
直入主题,谈一下思考的起因,从实际应用探寻原因。
下面是一道经典的“十六进制转八进制”题目(摘选自蓝桥杯题库):

经典例题,题目不难,引用一份c语言实现的代码(代码出处https://www.cnblogs.com/panweiwei/p/6478705.html,博客园,作者AllSight):
#include
#include
char h[100002],b[400002],e[400002];
int main(){
int n;
scanf("%d",&n);
while(n--){
scanf("%s",h);
int i,len=0;
/*先把16进制化成二进制——从后往前展开 */
for(i=strlen(h)-1;i>=0;i--){
int v;
if(h[i]>='0' && h[i]<='9')
v=h[i]-'0';
else v=h[i]-'A'+10;
for(int j=0;j<4;j++){
b[len++]=v%2+'0';
v/=2;
}
}
b[len]='\0';
int x=0,cnt=1;
int l=0;
for(i=0;i=0 && e[i]=='0')
/*去掉前导0*/
i--;
if(i<0)
printf("0");
for (;i>=0;i--){
printf("%c",e[i]);
}
printf("\n");
}
return 0;
}
这里只讨论与主题有关的前半段,即十六进制→二进制的部分,9~20行。这部分代码读一个键盘敲入的十六进制数,以字符形式储存在字符数组h中,再将该字符/字符串转换为二进制表示。为了便于观察,我们把9~20行单独提取出来,如下:
#include
#include
int main()
{
char h[100002],b[400002];
scanf("%s",h);
int i,len=0;
/*先把16进制化成二进制——从后往前展开 */
for(i=strlen(h)-1;i>=0;i--){
int v;
if(h[i]>='0' && h[i]<='9')
v=h[i]-'0';
else v=h[i]-'A'+10;
for(int j=0;j<4;j++){
b[len++]=v%2+'0';
v/=2;
}
}
return 0;
}
我们来看一下if判断部分:
博主最初的思路是:
1.判断是否为数字0~9,如果是,执行v=h[i]-'0';如果否,继续判断
2.判断是否为大写,如果是,执行v=h[i]-'A';如果否,继续判断
3.判断是否为小写,如果是,执行v=h[i]-'a';
但发现这份代码并没有判断区分大写/小写,大小写字母统统执行v=h[i]-'A';
这里引起了博主的兴趣,设输入字符为'F'与'f',断点设在第14行处,进行数值监测:
输入'F'
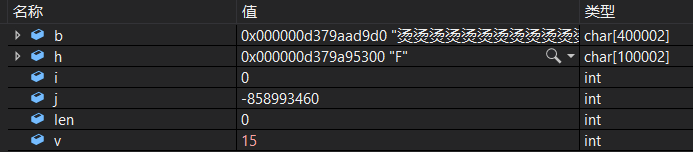
只关注v的取值,15
输入'f'
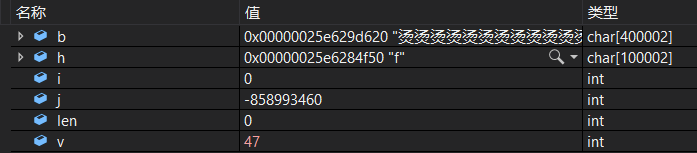
只关注v的取值,47
v取值完毕,继续执行15~18行代码:
for (int j = 0; j<4; j++) {
b[len++] = v % 2 + '0';
v /= 2;
}这段代码会把十进制v转化成四位二进制储存在数组b中。重要的一点,这里转化得到的四位二进制,是v二进制形式的低四位。
15对应二进制:0000 1111
47对应二进制:0010 1111
在本次输入'F'与'f'举例中,这就是并没有判断区分大写/小写的原因,15和47二进制形式的低四位相同。而四位二进制,恰好可以表示一个十六进制。
一份ASCII码表字母大小写对照,大写与小写二进制形式的低四位相同,验证普遍性(表格出处http://ascii.911cha.com/,911查询)
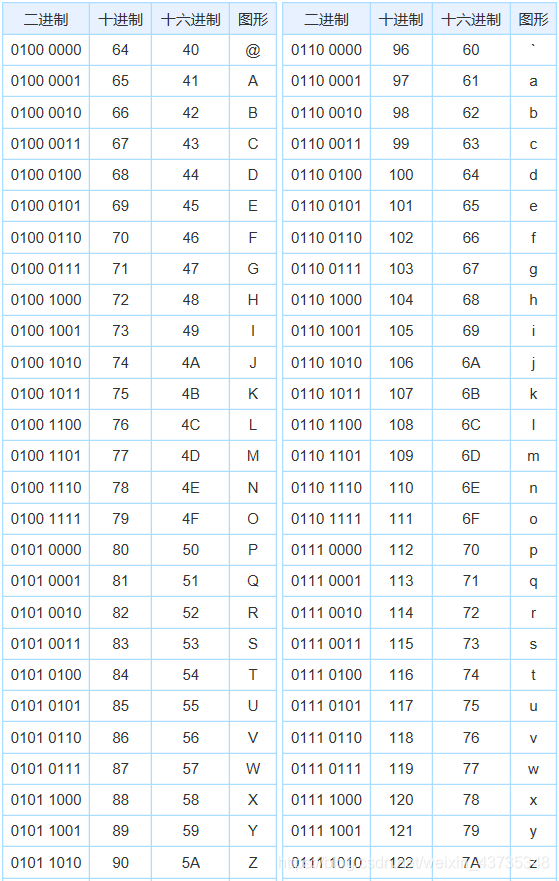
至此,可以体会ASCII码表字母大写小写相差32的便利之处了。
思考分析
为什么ASCII码表字母大小写相差32,会产生“巧合”呢?
32对应二进制:0010 0000
它的低四位是0000,这意味着,与大写/小写字母二进制形式做加减法时,大写/小写字母二进制形式的低四位不会改变。
例如,'A'+32,二进制加法:
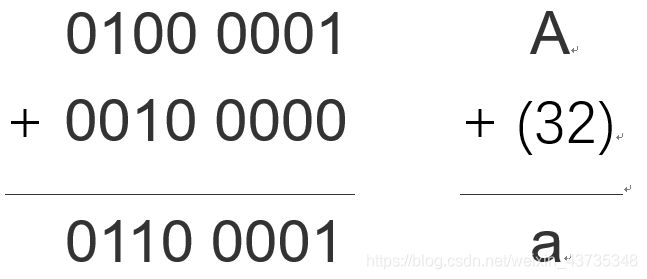
同理,可推广至A~Z,a~z。
其实使用+16/-16:即+0001 0000/-0001 0000,也可以实现大写/小写字母二进制形式的低四位不被改变。不过,16个字符不够26个英文字母使用,因此采用+32/-32,即+0010 0000/-0010 0000,作为ASCII码表中字母大小写间的差值。