用CTGAN生成真实世界的表格数据
随着CLIP和稳定模型的快速发展,图像生成领域中GAN已经不常见了,但是在表格数据中GAN还是可以看到它的身影。
现实世界的复杂性与许多方面相关(例如,缺失数据、不平衡数据、噪声数据),但最常见的一个问题是包含异构(或“混合”)数据,即包含数字和分类特征的数据。
由于每种特征类型都可能具有自己的内在特征,异构数据对合成数据生成过程提出了额外的挑战。
CTGAN(Conditional Tabular Generative Adversarial Network)就是通过“捕获”现实世界数据的这种异质性,与其他架构(如WGAN和WGAN- gp等)相比,已被证明对各种数据集更加健壮和可泛化。
在本文中,我们将介绍CTGAN,并且说明哪些属性使得它对表格数据如此高效,以及为什么和何时应该利用它。
真实世界的表格异构数据
我们所说的“表格数据”,即可以以类似表格的格式进行结构化和组织和存储的数据。特征(有时称为“变量”或“属性”)以列表示,而观察值(或“记录”)对应于行。真实世界的数据通常包括数字和分类特征:
数值特征(也称为“连续的”)是那些编码定量值的特征,而分类特征(也称为“离散的”)表示定性测量。
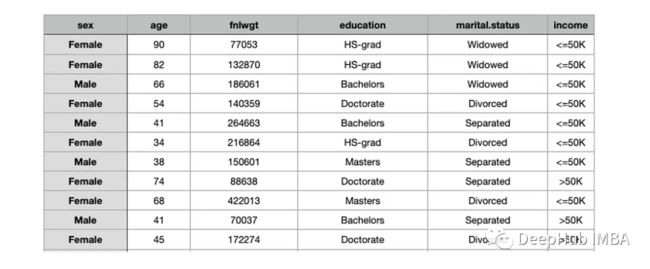
下面是一个收入数据集的示例,age和fnlwgt是数字特征,而其余的是分类特征。
为什么异构表格数据需要CTGAN ?
从最初的GAN开始,研究人员一直在对原始架构、新的损失函数或优化策略提出修改,以解决特定的GAN局限性。
例如,WGAN和WGAN- gp等架构在训练稳定性和收敛时间方面对GAN进行了显著改进。,PacGAN的设计是为了缓解模式崩溃,这是传统GAN架构的另一个常见缺点。
但是在数据异构方面(即处理数字和分类特征及其内在特征),这些体系结构似乎仍然不尽如人意。它们在数字特征方面表现得很好,但它们很难捕捉分类特征的分布,而分类特征的存在对于大多数真实世界的数据集来说都是现实的。
这些架构都没有处理包含混合特征类型的异构数据——包括数字和分类。但是CTGAN是专门设计处理表格数据集的。在其他架构(如WGAN-GP和PacGAN)取得成功的基础上,CTGAN更进一步,将合成数据生成视为一个完整的流程——从数据准备到GAN架构本身。也就是说,CTGAN关注数字和类别特征的特定特征,并将这些特征合并到生成器模型中。
数值特征:非高斯分布和多峰分布
CTGAN 引入特定归一化,与像素值通常遵循类似高斯分布的图像数据相反,表格数据中的连续特征通常是非高斯分布的。它们倾向于遵循多峰分布,其中概率分布具有不止一种模式,即它们呈现出不同的局部极大值(或“峰值”):
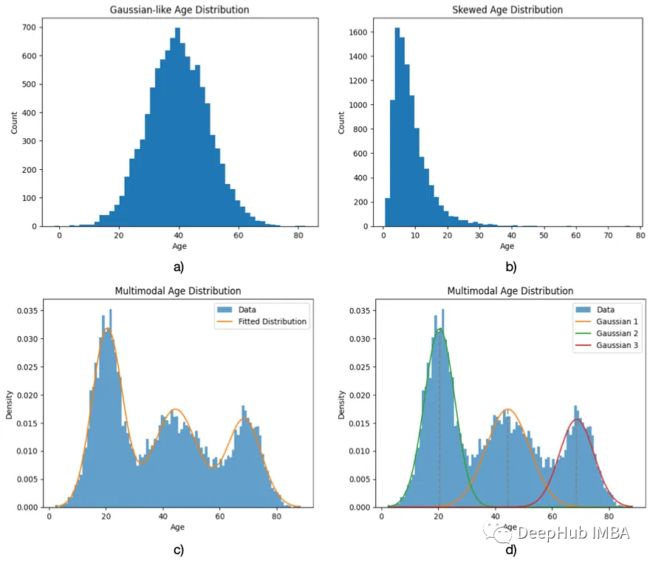
为了捕获这些行为,CTGAN 使用特定于模式的归一化。使用 VGM(变分高斯混合)模型,连续特征中的每个值都由表示其采样模式的独热向量和表示根据该模式归一化的值的标量表示:

分类特征:稀疏独热编码向量和高分类不平衡
CTGAN引入了条件生成器,旨在解决由分类特征引入的两个主要挑战:
一个是独热编码向量在真实数据中的稀疏性。当生成器输出所有可能的类别值的概率分布时,原始的“真实”类别值直接编码在一个独热向量中。通过比较真实数据和合成数据之间的分布稀疏性,判别器很容易区分这些数据。
另一个是与某些分类特征相关的不平衡。如果一个特征的某些类别没有被充分表示,那么生成器就不能充分地学习它们。如果我们关注预测建模或分类任务,数据过采样可能是缓解这一问题的解决方案。但是由于合成数据生成的目标是模拟原始数据的属性,所以这个解决方案不成立。
CTGAN引入了一个条件生成器来处理不平衡类别,但是这通常会导致GAN的模式崩溃。在条件也没有完美的解决这个问题,它也需要准备输入以便生成器可以解释条件,并且生成的行需要保留输入条件。
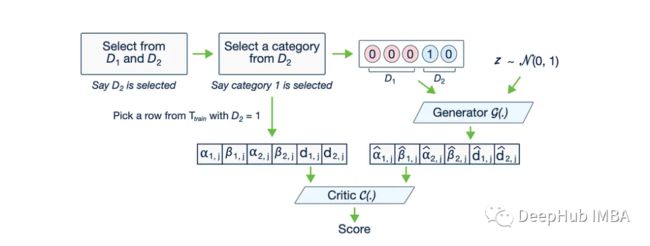
CTGAN生成表格数据代码示例
CTGAN的发布已经有2-3年的时间了,我们可以直接使用 下面的 代码安装官方的实现并使用它:
pip install ctgan
但是,我们这里要介绍一个更简单并且方便的使用方式,还记得stable diffusion web UI吗,我可直接可以用过点点点就能生成图片,现在ydata-synthetic也推出了一个Streamlit应用程序,我们可以直接通过webUI来执行数据读取,分析,新生成的合成数据的完整流程。
首先要安装ydata-synthetic。别忘了加上“streamlit”:
pip install "ydata-syntehtic[streamlit]==1.0.1"
然后,打开一个Python文件添加下面2行代码:
from ydata_synthetic import streamlit_app
streamlit_app.run()
运行后,控制台将输出可以访问应用程序的URL !
1、训练一个模型
训练合成器很简单:你可以访问“Train a Synthesizer”选项卡并上传一个文件(我使用的是上面的收入数据集):
文件加载后需要指定哪些特征是数字的和分类的:
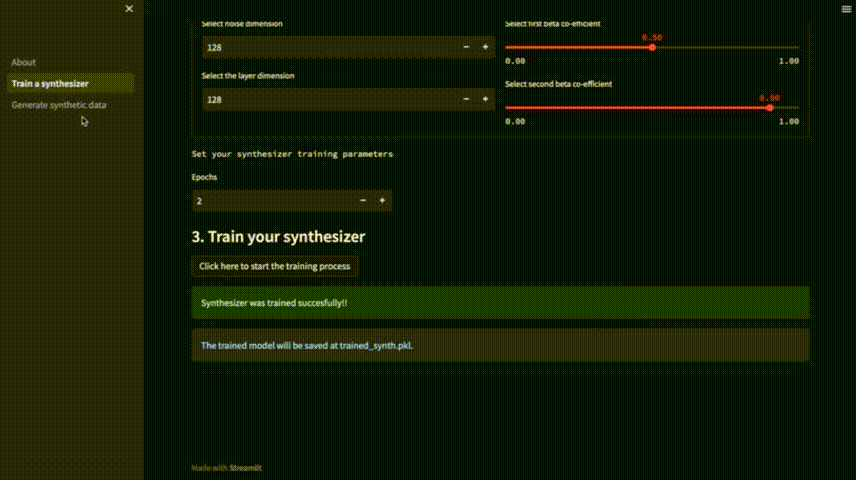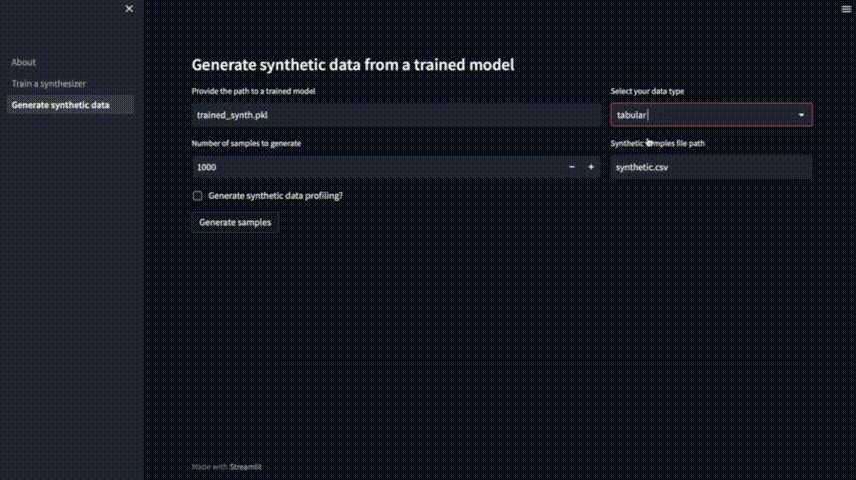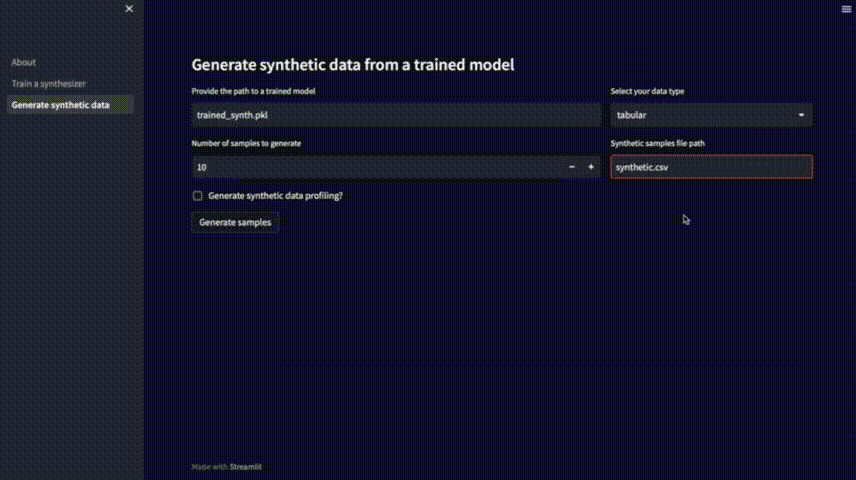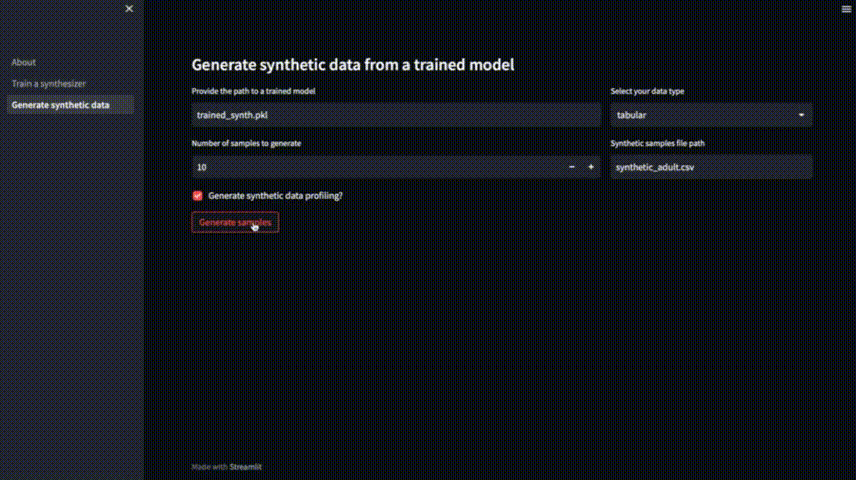
然后,可以选择合成器参数,即我们打算使用的模型及其参数,如批量大小、学习率和其他设置(例如噪声维度、层维度和正则化常数beta等等)。选择训练轮数,然后点击一个按钮开始训练:
我在示例中使用了CTGAN,这个UI还支持其他模型,如GAN、WGAN、WGANGP、CRAMER和DRAGAN。
2、生成数据样本
要生成新的样本,我们可以访问“Generate synthetic data”选项卡,选择要生成的样本数量,并指定保存它们的文件名。模型在默认情况下以trained_synth保存和加载。也可以通过提供它的路径来加载先前训练过的模型。
“Generate synthetic data profiling”可以生成一个数据分析报告来检查合成数据的整体特征,设置完成后可以点击 “Generate Samples”开始生成。
生成的报告是使用ydata-profiling包生成的,而合成的样本保存在syntic_adult .csv文件中。
通过研究新生成的样本报告,可以很容易地确定CTGAN已经成功地学习了原始数据的特征,即使在复杂的异构场景中,包括:
- 数字和类别特征的基本特征统计数据保持一致(例如,平均值/标准偏差,类别/模式的数量)
- 在合成数据上保持原始类别的频率,模拟了类别特征的表示
- 特征之间的基本关系(相关性)也被保留
根据给定给模型的特定参数,也可以改进合成数据生成结果,使新数据尽可能接近原始数据。有了这个方便的UI我们基本上不用写代码就可以生成新的数据了。
局限性和缺点
尽管CTGAN已被证明是一种强大的表格数据架构,但它仍然有一些局限性和缺点(正如预期的那样,一些是所有深度学习模型共同的):
- 为具有不同特征的数据集优化超参数具有挑战的,需要大量的反复试验;
- 处理高基数特征仍然存在问题,因为模型很难学习和生成如此大量的独特类别
- 处理偏态分布或具有大量常量值(例如,大量 0)的分布也很难被该架构捕获
- 对于小数据集,合成可能不太准确,因为 CTGAN 与任何其他深度学习模型一样,需要大量数据
- 训练和收敛可能需要大量的计算资源和时间,尤其是对于非常大的数据集
但是CTGAN 可以最有效地为具有异构特征和足够训练规模的结构化表格数据集生成合成数据,这一点是很好的。
总结
在本文中,我们讨论了CTGAN的工作原理,探索了ydata-synthetic的Streamlit应用程序,它允许我们在无代码的环境中合成数据。
根据更新计划,下一个将添加到UI的是对时间序列模型(TimeGAN)的支持,这是一个非常好的消息。
相关文件下在地址:
https://avoid.overfit.cn/post/512c0554f1d84a56a14cf53181d6e471
作者:Miriam Santos