电商数仓学习-Maxwell的使用
增量表同步工具Maxwell
- 前言
- 一、Maxwell简介
-
- 1.Maxwell概述
- 2.Maxwell输出数据的格式
- 二、Maxwell
-
- 1.MySQL二进制日志
- 2.MySQL主从复制
- 3.Maxwell原理
- 三、Maxwell部署
-
- 1.安装Maxwell
- 2.配置MySQL
-
- 1)启用MySQL Binlog
- 2)创建Maxwell所需数据库和用户
- 3)配置Maxwell
- 四.Maxwell使用
-
- 1.启动Kafka集群
- 2.Maxwell启动停止
- 3.Maxwell历史数据全量同步
-
- 1)Maxwell-bootstrap
- 2)bootstrap数据格式
前言
前面已经说明增量表适用Maxwell工具进行同步,因此对Maxwell进行一个简单的学习
一、Maxwell简介
1.Maxwell概述
Maxwell是用Java编写的MySQL变更抓取软件,会实时监控MySQL数据库里的数据变更操作(包括insert、update、delete),并将变更数据以JSON的格式发送给Kafka(大数据常用)、Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。它的官网地址:http://maxwells-daemon.io/
2.Maxwell输出数据的格式
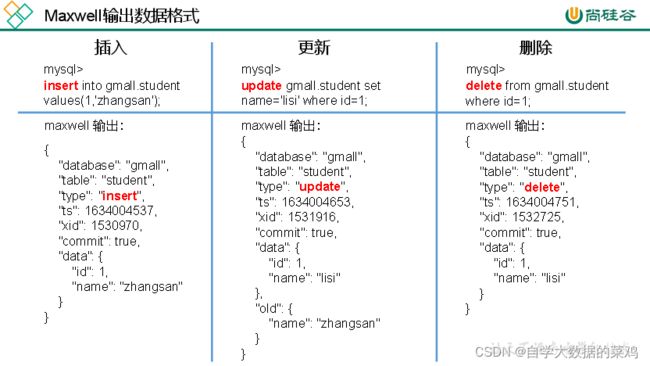
上图中字段说明:
| 字段 | 说明 |
|---|---|
| database | 变更数据所属的数据库 |
| table | 变更数据所属的表 |
| type | 变更数据类型 |
| ts | 数据变更发生的事件(秒) |
| xid | 事务id |
| commit | 事务提交标志,可用于重新组装事务 |
| data | 对于insert类型:表示插入的数据;对于update类型:表示修改后的单条所有的数据;对于delete类型:表示删除的数据 |
| old | 对于update类型:只表示要被修改的字段 |
二、Maxwell
Maxwell的工作原理是实时读取MySQL数据库的二进制日志(Binlog),从中获取变更数据,再将变更数据以JSON格式发送至Kafka等流处理平台。
1.MySQL二进制日志
二进制日志(Binlog)是MySQL服务端非常重要的一种日志,它会保存MySQL数据库的所有数据变更记录。Binlog的主要作用包括主从复制和数据恢复。Maxwell的工作原理和主从复制密切相关。
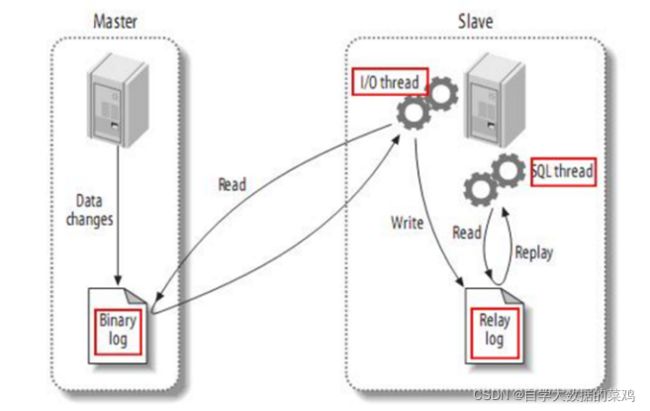
2.MySQL主从复制
MySQL的主从复制,就是用来建立一个和主数据库完全一样的数据库环境,这个数据库称为从数据库(意思就是仿照一个数据库建立了一个一样的数据库,新建立的数据库作为从数据库)。
1)主从复制的应用场景:
一是做数据库的热备:当主数据库服务器故障的时候,可以切换到从数据库继续工作,两个数据库里的数据是一样的。
二是读写分离:如果只在一个数据库中同时进行读和写,这个数据库压力会比较大。如果让主数据库进行写操作,从数据库进行读操作,这样大大减少了数据库的压力。
2)主从复制的工作原理:
第一步,Master主库将数据变更记录,写到自己的二进制日志(binary log)中。
第二步,Slave从库向mysql master(Master主库)发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)中。
第三步,Slave从库读取并回放自己的中继日志中的事件,将改变的数据同步到自己的数据库中。
3.Maxwell原理
Maxwell就是将自己伪装成Salve从库,并遵循MySQL主从复制的协议,从master同步数据。
三、Maxwell部署
1.安装Maxwell
第一步,下载安装包:https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
注:Maxwell-1.30.0及以上版本不再支持JDK1.8
第二步,解压:tar -zxvf maxwell-1.29.2.tar.gz -C /opt/module/
2.配置MySQL
因为是Maxwell监控MySQL中的某个数据库,且Maxwell要实现主从复制,因此需要对MySQL进行配置。
1)启用MySQL Binlog
MySQL服务器的Binlog默认是未开启的,如需进行同步,需要先进行开启。
1)修改MySQL配置文件/etc/my.cnf:sudo vim /etc/my.cnf
2)在配置文件中加入如下内容:
[mysqld]
#数据库id
server-id = 1
#启动binlog,该参数的值会作为binlog的文件名
log-bin=mysql-bin
#binlog类型,maxwell要求为row类型
binlog_format=row
#启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=gmall
server-id参数说明:
给MySQL进行编号,在主从复制的时候分清楚哪个是主,哪个是从,这里是Maxwell监控数据,所以编号随意。
binlog_format参数说明:
第一种是Statement-based:基于语句,Binlog会记录所有写操作的SQL语句,包括insert、update、delete等。优点是:因为记录的是语句,因此节省了空间。缺点是:有可能造成数据不一致,例如insert语句中插入的字段包含now()函数,第一次与第二次执行得到的结果明显不同。
第二种是Row-based:基于行,Binlog会记录每次写操作后被操作行记录的变化。优点:因为拉取到的是最终的结果数据,因此能够保持数据的绝对一致性。缺点:占用了较大空间。
第三种是mixed:混合模式。默认是Statement-based,如果检测到SQL语句可能导致数据不一致,就自动切换到Row-based。
总结,从实际上看,mixed模式是最优的,整合了前两种方式的特点,如果只为了MySQL实现主从复制,这是最佳的选择。但是在数仓项目中,拿到的update操作数据是要有修改后的所有数据的,mixed模式在不使用Row-based的情况下,可能拿不到最终一行的数据(例如一个表总共有100列,update操作只修改了1列,那只拿到了那一列的数据)。
而数仓项目要求update拿到一行完整的数据,因此Maxwell要求Binlog采用Row-base的模式。
3)重启MySQL服务:
sudo systemctl restart mysqld
2)创建Maxwell所需数据库和用户
Maxwell需要在MySQL中存储其运行过程中的所需的一些数据,包括binlog同步的断点位置(Maxwell支持断点续传)等等,故需要在MySQL为Maxwell创建数据库及用户(如果使用root用户风险太大)。
第一步,创建数据库:msyql> CREATE DATABASE maxwell;
第二步,调整MySQL数据库密码级别:
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
第三步,创建Maxwell用户并赋予其必要权限:
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
第一行意思是,创建一个用户叫maxwell,允许连接权限的地址是任意(%),它的密码是maxwell
第二行意思是,把maxwell这个数据库里所有表的所有的权限赋予给maxwell用户的任意连接
第三行意思是,把任意库任意表的一些基础的权限(例如读权限等)赋予给maxwell用户
3)配置Maxwell
第一步,修改Maxwell配置文件名称:cp config.properties.example config.properties
第二步,修改Maxwell配置文件:vim config.properties
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
#目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=maxwell
#MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
四.Maxwell使用
1.启动Kafka集群
若Maxwell发送数据的目的地为Kafka集群,则需要先确保Kafka集群为启动状态。
2.Maxwell启动停止
1)启动Maxwell:
/opt/module/maxwell/bin/maxwell --config /opt/module/maxwell/config.properties --daemon
–daemon参数说明:启动守护线程,让该进程后台运行
–config参数说明:指明config.properties所在的位置,如果在maxwell根目录下运行maxwell则不需要指明
2)停止Maxwell:
ps -ef | grep maxwell | grep -v grep | grep maxwell | awk '{print $2}' | xargs kill -9
3)Maxwell启停脚本:
#!/bin/bash
MAXWELL_HOME=/opt/module/maxwell
status_maxwell(){
result=`ps -ef | grep maxwell | grep -v grep | wc -l`
return $result
}
start_maxwell(){
status_maxwell
if [[ $? -lt 1 ]]; then
echo "启动Maxwell"
$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemon
else
echo "Maxwell正在运行"
fi
}
stop_maxwell(){
status_maxwell
if [[ $? -gt 0 ]]; then
echo "停止Maxwell"
ps -ef | grep maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
else
echo "Maxwell未在运行"
fi
}
case $1 in
start )
start_maxwell
;;
stop )
stop_maxwell
;;
restart )
stop_maxwell
start_maxwell
;;
esac
3.Maxwell历史数据全量同步
Maxwell可以实现增量同步,但有时只有增量数据是不够的,我们可能需要使用到MySQL数据库中从历史至今的一个完整的数据集。这就需要我们在进行增量同步之前,先进行一次历史数据的全量同步。这样就能保证得到一个完整的数据集。
1)Maxwell-bootstrap
Maxwell提供了bootstrap功能来进行历史数据的全量同步,命令如下:
/opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/module/maxwell/config.properties
参数说明:
–database:指明要同步的数据库名
–table:指明要同步的表名
–config:指明config文件路径
2)bootstrap数据格式
数据格式如下:
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-start",
"ts": 1450557744,
"data": {}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-insert",
"ts": 1450557744,
"data": {
"txt": "hello"
}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-insert",
"ts": 1450557744,
"data": {
"txt": "bootstrap!"
}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-complete",
"ts": 1450557744,
"data": {}
}
注意事项:
第一条type为bootstrap-start的数据和最后一条type为bootstrap-complete的数据,分别是bootstrap开始同步和结束同步的标志,这两条数据不包含具体的业务数据,中间type为bootstrap-insert的数据才包含业务数据。
一次bootstrap输出的所有记录的ts都相同,为该次同步bootstrap开始的事件。