Redis底层数据结构分析(二) —— Hash结构
接上一篇SDS动态字符串,今天再讲讲Hash结构:
Redis底层数据结构分析(一) —— SDS动态字符串_小熊不吃香菜的博客-CSDN博客Redis官网文档Redis源码仓库Redis是一个基于内存的高性能键值存储系统。Redis支持多种数据类型,包括字符串、哈希、列表、集合、有序集合等。每种数据类型在底层都有对应的数据结构实现。SDS动态字符串双向链表压缩链表ziplist哈希表hashtable跳表skiplist整数数组intset快速列表quicklist紧凑列表listpack Tips:官网说明 Tips:对应文件。https://blog.csdn.net/x_xhuashui/article/details/129917519
Hash数据结构
Hash简介
Redis中的Hash数据结构是一种键值对的集合,可以用来存储对象的属性或者其他类型的映射关系。
也就是说每个Hash可以存储多个键值对,如图所示为Hash的存储结构:
![]()
field 和 value 共同组成了 key 所对应的 value。
比如当我们要存储用户对象时就可以使用Hash结构,一个用户有多个属性字段,如:姓名,年龄等。所以映射关系为:
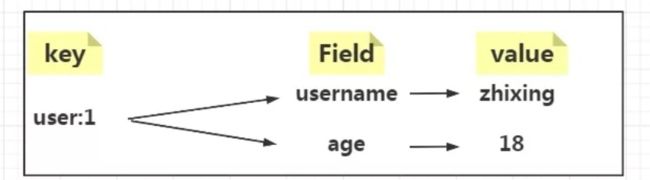
回顾一下Hash的常用命令:
| 命令 |
说明 |
返回值 |
| HSET key field value |
用于为哈希表中的单个 field-value 设置值,如果 key 值不存在,会先创建,如果该 field 域已存在,则将覆盖旧值 |
如果 field 是新创建的,返回 1, 如果 field 已存在, 返回 0 |
| HMSET key field1 value1 [field2 value2 ...] |
用于同时将多个 field-value 对设置到哈希表中,此命令会覆盖哈希表中已存在的 key 值,如果 key 值不存在,会先创建,之后再执行 HMSET 操作 |
成功返回 OK |
| HSETNX key field value |
用于为哈希表中不存在的 field 赋值,如果该 field 已存在,则操作无效,如果 key 不存在,则创建并执行 |
成功,返回1,如果 field 已经存在且没有操作被执行,返回0 |
| HEXISTS key field |
用于查看哈希表的指定域是否存在 |
如果有指定域,则返回1,如果没有该域,或者 key 不存在,则返回0 |
| HGET key field |
用于获取哈希表中指定域的值 |
返回指定字段的值,如果指定的字段或者 key 不存在时,返回 nil |
| HGETALL key |
用于返回哈希表中所有的字段和值 |
以列表形式返回哈希表中的字段以及字段值,如果 key 不存在,则返回空列表 |
| HMGET key field1 [field2 ...] |
用于返回哈希表中一个或多个指定字段对应的值,如果指定的字段不存在于哈希表中,则返回 nil |
一个包含多个指定字段关联值的表,表值的排列顺序和指定字段的请求顺序一样 |
| HKEYS key |
用于获取哈希表中的所有的域(field) |
包含哈希表中所有域的列表,如果 key 不存在,则返回一个空列表 |
| HVALS key |
获取哈希表中所有的值,即所有的 field 对应的 value |
包含哈希表中所有值的列表,如果 key 不存在,则返回一个空列表 |
| HLEN key |
获取哈希表中字段(field)的数量 |
返回哈希表中字段的数量,当 key 不存在时,返回0 |
| HDEL key field1 [field2 ...] |
用于删除哈希表 key 中的一个或多个字段(field),如果指定的 field 不存在,则忽略 |
返回成功删除字段的数量,不包括被忽略的字段 |
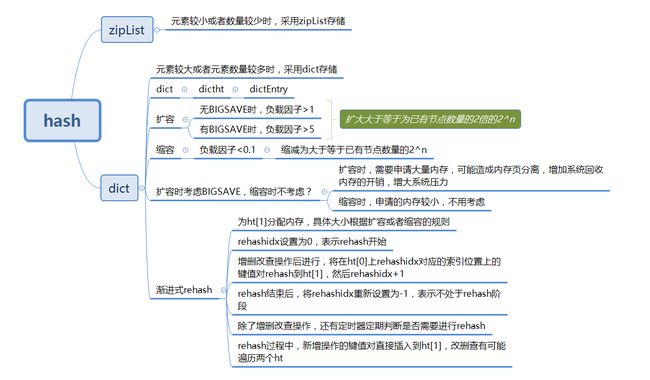
Hash的编码方式
编码方式主要分两部分讲,一个是Redis6中的编码方式,一个是Redis7的编码方式。
在Redis6中,Hash数据结构的底层实现有两种编码方式,分别是ziplist(压缩列表)和hashtable(哈希表)。下面是基于Redis6的分析
Hashtable
先讲一下我们熟悉的Hashtable吧,在学javase时应该是非常熟悉的了。
在Redis 中,hashtable被称为字典(dictionary),它是一个数组+链表的结构。我们知道在JDK1.8之前也是采用数组+链表的结构,所以可以类比学习。
之前讲过,Redis中的key-value是通过dictEntry对象来实现的,而HashTable就是将dictEntry对象进行了再一次的包装得到的,这就是哈希表对象dictht。
在 Redis内部,从 OBJ_ENCODING_HT类型到底层真正的散列表数据结构是一层层嵌套下去的,组织关系见面图:

其中,OBJ_ENCODING_HT 是HashTable的对象编码方式(Redis会在不同的场景选择不同的编码方式,即选择不同的底层实现),内部才是真正的哈希表结构,或称为字典结构,其可以实现O(1)复杂度的读写操作,因此效率很高。
| 编码属性 |
描述 |
object encoding命令返回值 |
| OBJ_ENCODING_ZIPLIST |
使用压缩列表实现哈希对象 |
ziplist |
| OBJ_ENCODING_HT |
使用字典实现哈希对象 |
hashtable |
下面我们就一层一层的剖析HashTable的底层实现吧!
源码分析(dict.h 和 t_hash.c)
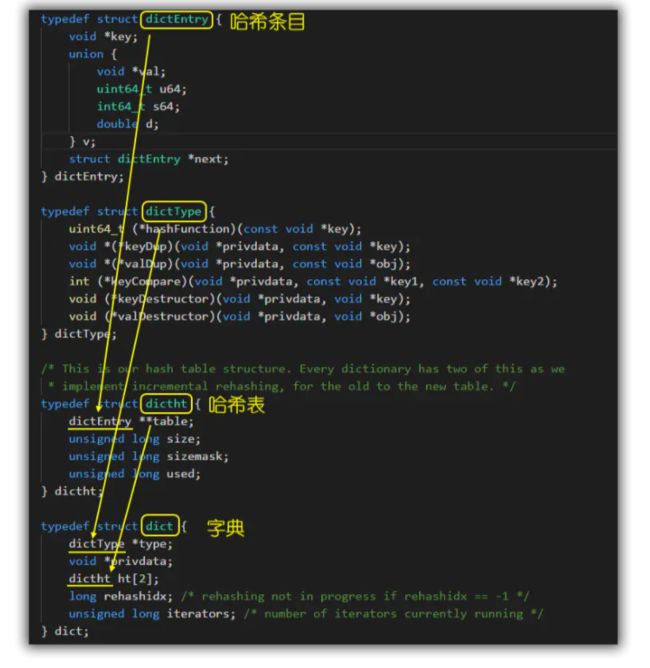

- 最底层的
dictEntry对象就不用说了,最终存储数据的地方,每个键值对都会有一个dictEntry。 dictType内部定义了一些常用函数,对外提供的一组操作接口,包括键值对的添加、删除、查找等操作。- 再看看
dictht,它实质是对dictEntry的再封装,主要存储了哈希表数组(dictEntry**table, 表示dictEntry数组,用于真正存储数据), 数组大小(size), 掩码大小(sizemask,用于计算索引值,总是等于size-1),已有节点数(used)。 - 字典
dict是一种常用的数据结构,各属性含义如下:
-
type:dictType结构的指针,封装了很多数据操作的函数指针,使得 dict 能处理任意数据类型(类似面向对象语言的 interface,可以重载其方法)private:一个私有数据指针,由调用者在创建 dict 的时候传进来。它的作用是让调用者可以在 dict 中存储一些额外的数据,比如说一些上下文信息等等。ht[2],两个hash表,ht[0] 为主,ht[1] 在渐进式 hash 的过程中才会用到。rehashidx,这是一个辅助变量,用于记录rehash过程的进度,以及是否正在进行rehash等信息,当rehashidx=-1时,表示该dict此时没有进行rehash过程iterators,记录此时dict有几个迭代器正在进行遍历过程
最后整个dict的结构示意图引用《Redis 设计与实现》中的图,如下所示:
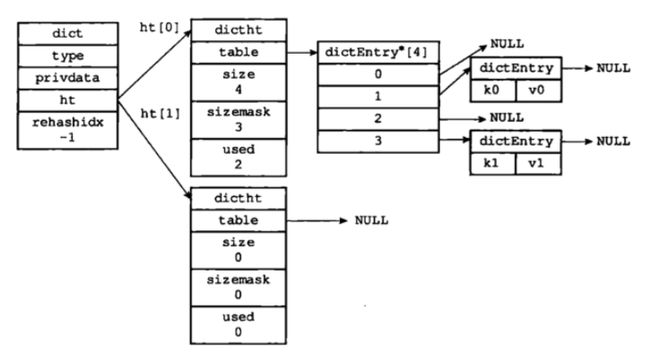
上面是一个没有处于rehash状态下的字典dict,整个dict中有两个哈希表dictht,其中一个哈希表存储数据,另一个哈希表则为空,用于rehash状态下的数据存储。
扩容和缩容机制
hash不可避免的一个问题就是扩容和缩容问题,下面围绕这个问题展开阐释
Hash这种数据结构有着非常多的优势,但也存在着一些问题,包括哈希冲突,如何扩容、缩容等。那这些问题是怎么解决的呢?
随着哈希表中元素数量逐渐增加时,产生hash冲突的概率逐渐增大,由于dict采用拉链法解决hash冲突的,因此随着元素的增多,链表会越来越长,这就会导致查找效率下降。相反,当元素不断减少时,元素占用dict的空间就越少,出于对内存的极致利用,此时就需要进行缩容操作。
而扩容和缩容,参考Java中的HashMap的扩容机制,Redis也采用同样的方式,即负载因子
loadfactor。还记得负载因子是什么吗?简单复习一下:负载因子是指哈希表中键值对数量与哈希表长度之间的比率,即负责因子=哈希表中已保存节点数量/哈希表的大小。当键值对数量增加时,负载因子也会随之增加。在Redis中即为:
load factor = ht[0].used / ht[0].size扩容机制
当负载因子超过一定阈值时,Redis会自动对哈希表进行扩容操作,以保证哈希表的性能。
在Redis中,哈希表的默认长度为4,当Redis没有进行
BGSAVE相关操作,且负载因子>=1时,Redis会自动对哈希表进行扩容操作。扩容操作会将哈希表长度翻倍,并将原哈希表中的所有键值对重新分配到新哈希表中。在扩容过程中,Redis会使用渐进式rehash的方式(后面介绍),将原哈希表中的所有键值对慢慢地迁移到新哈希表中,最后释放原哈希表的内存空间。在扩容过程中,如果有客户端对哈希表进行了写操作,则会将写操作转移到新哈希表中。如果正在执行
BGSAVE和BGREWRITEAOF指令的情况下,负载因子>=5时强行扩容。缩容机制
当负载因子<0.1的时候,进行缩容。缩容时,Redis会新建一个小于等于原哈希表大小的哈希表,然后将原哈希表中的所有键值对rehash到新哈希表中,最后释放原哈希表的内存空间。缩容后的
dictEntry数组数量为第一个大于等于ht[0].used的(因为table数组大小一定是2的幂次方)。在缩容操作期间,字典会同时使用ht[0]和ht[1]两个哈希表,所以在缩容操作进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行
渐进式Rehash
在扩容过程中,Redis会将原哈希表中的所有键值对慢慢地迁移到新哈希表中,这个过程被称为rehash。那么rehash是怎么实现的呢?
我们知道java的HashMap扩容时也会进行rehash过程,先回顾一下HashMap的rehash过程:源码解析——HashMap https://blog.csdn.net/x_xhuashui/article/details/129390981?spm=1001.2014.3001.5502
https://blog.csdn.net/x_xhuashui/article/details/129390981?spm=1001.2014.3001.5502
但这里有个问题:Java中的HashMap在rehash时,需要一次性全部rehash,这是一个耗时操作。因为在rehash时,需要将所有的键值对重新计算hash值,然后放到新的数组中。如果不一次性全部rehash,而是分批次地rehash,那么就会出现一些键值对被放到了新数组中,而另一些键值对还在旧数组中的情况,这样就会导致get操作时无法找到对应的键值对,put操作时也会出现重复的键值对。
而对于Redis来说,如果哈希表里保存的键值对数量很大时,如:四百万、四千万甚至更多,一次性地将所有键值对rehash,会导致Redis服务在几秒钟甚至几十秒钟内停止响应,这对于单线程的Redis是很难承受的。
所以Redis采用了渐进式rehash的平滑扩容机制,它通过两个哈希表+渐进式rehash的方式来实现扩容机制,从而实现平滑扩容,又不阻塞读写。在Redis中,哈希表扩容或收缩时需要将ht[0]里面的所有键值对rehash到ht[1]里面。但是这个rehash动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
它的基本思想是:将原哈希表ht[0]中的键值对分批迁移到新哈希表ht[1]中,每次迁移一个桶(链表)的数据,同时保持两个哈希表都可用,直到所有数据都迁移完毕,然后释放原哈希表,将新哈希表设为ht[0]。
具体流程如下:
- 为ht[1]哈希表分配足够的内存空间,其大小取决于当前哈希表当前的负载因子和已保存节点数(即:
ht[0].used) - 维护
rehashidx变量:这是一个索引计数器,表示当前要迁移的桶的位置。初始值为0,每次迁移一个桶后+1,直到等于原哈希表大小时,表示rehash完成。 - 在ht[0]中取出一个键值对进行
rehash,并将其插入到ht[1]中,完成后rehashix的值需要+1。 - 重复步骤2,直到ht[0]中所有键值对都被rehash到ht[1]中。
- 完成
rehash后,即当rehashidx等于原哈希表大小时,将rehashidx属性设为-1,释放ht[0]的内存空间,将ht[1]设置为ht[0],并在ht[1]中创建一个空白的哈希表,为下一次rehash做准备。
在每次执行增删改查操作时,都会检查是否需要执行渐进式rehash操作。每次对字典执行添加、删除、查找或更新操作时,除了执行指定的操作外,还会顺带将ht[0]中rehashidx位置上的所有键值对迁移到ht[1]中,并更新rehashidx的值。
上面好像也没解释清除渐进式
rehash怎么解决阻塞读写的问题?
先回答第一个问题:
- 保持两个哈希表都可用:在
rehash过程中,ht[0]和ht[1]都可以接受读写请求,只是写入的位置不同。如果写入的键在ht[0]中存在,那么更新ht[0]中的值;如果写入的键在ht[1]中存在,那么更新ht[1]中的值;如果写入的键在两个哈希表中都不存在,那么写入到ht[1]中。这样可以保证不丢失任何数据,也不影响读写性能。 - 分批迁移数据:在每次执行读写操作时,只迁移一个桶(链表)的数据,而不是一次性迁移所有数据。这样可以避免长时间占用CPU资源,造成阻塞。同时,迁移的速度也会随着读写操作的频率而增加,保持与负载因子的平衡。
BIGSAVE操作对扩容的影响
BIGSAVE操作是Redis的一种持久化方式,它会将内存中的数据以快照的形式保存到硬盘上。在进行扩容操作时,如果执行了BIGSAVE操作,会对扩容的影响有以下两点:
BIGSAVE操作会阻塞Redis进程
当Redis执行BIGSAVE操作时,它会将内存中的数据快照保存到磁盘上。在保存快照的过程中,Redis进程会被阻塞,直到快照保存完成为止。如果在进行扩容操作时执行了BIGSAVE操作,会导致Redis进程被阻塞,在阻塞期间,Redis无法处理客户端请求,会影响Redis的性能和可用性。
BIGSAVE操作会导致扩容操作变得更加耗时
在进行扩容操作时,如果执行了BIGSAVE操作,会导致扩容操作变得更加耗时。因为在进行扩容操作时,需要将原有的数据全部迁移到新的节点上,如果在迁移数据的过程中执行了BIGSAVE操作,会导致Redis进程被阻塞,从而延长迁移数据的时间,增加扩容操作的耗时。
因此,在进行扩容操作时,最好不要同时执行BIGSAVE操作。如果需要进行持久化操作,可以使用其他的持久化方式,比如AOF持久化或者增量RDB持久化,这些持久化方式不会阻塞Redis进程,可以在不影响Redis性能和可用性的情况下进行持久化操作。
HSET命令解读
HSET key field value其中,key是哈希表的键,field是哈希表中的字段,value是要设置的值。如果field不存在,则创建一个新的字段,并将值设置为value;如果field已经存在,则覆盖原有的值。
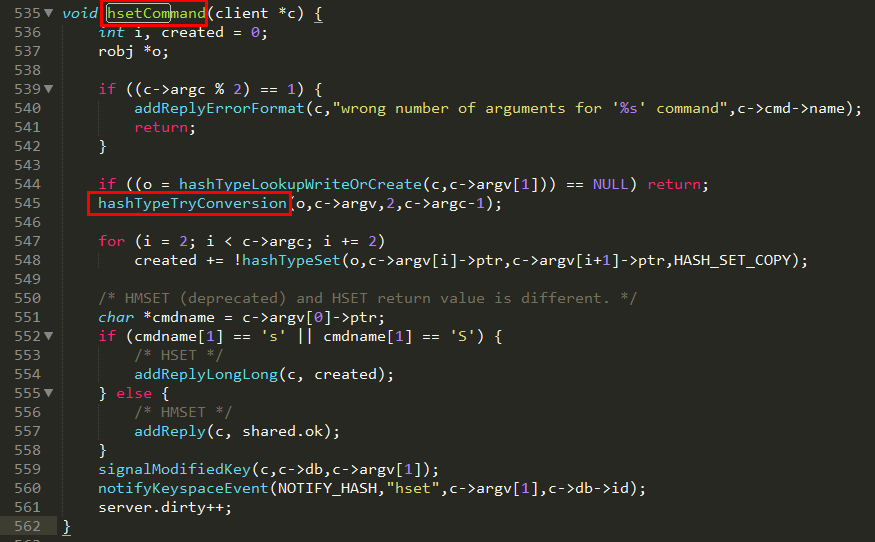
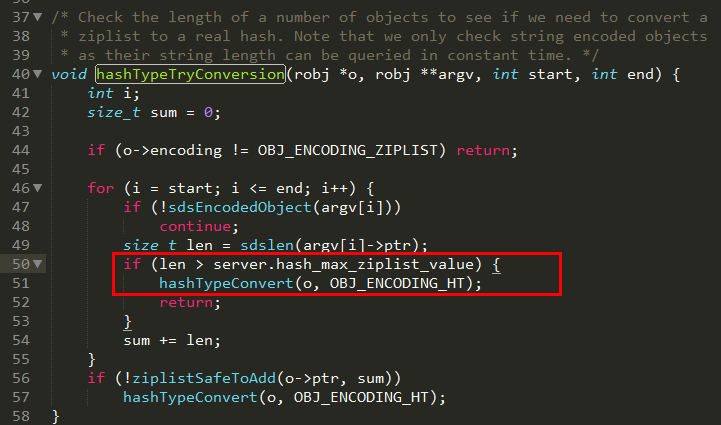
ziplist
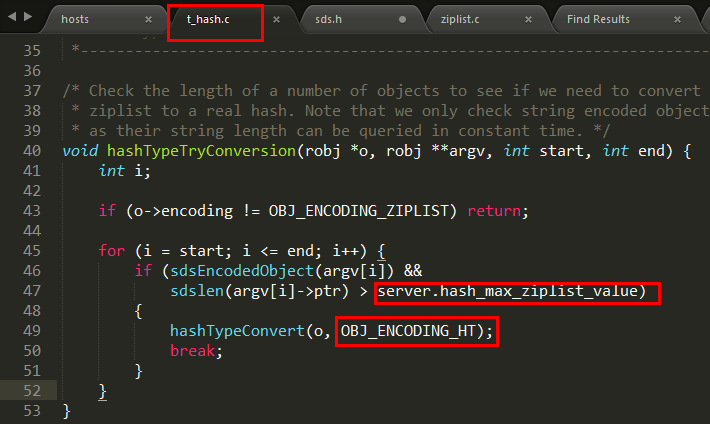
在Redis7以前,ziplist是一种紧凑的、节省内存的、经过特殊编码的双向链表结构,总体思想是多花时间来换取节约空间(内存利用率提高,查询速度会降低,多了编码解码操作),它将多个键值对存储在一个连续内存块组成的顺序型数据结构中(类似数组),每个键值对占用一个Entry,包含前一个元素长度、编码字段长度、实际内容等信息。ziplist适合存储小对象(因为要编解码),当hash对象满足以下两个条件时,会使用ziplist编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数量小于512个
因此只会用于字段个数少,且字段值也较小的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。
结构分析
讲源码之前先聊聊Java中的双向链表,它的每个数据结点中都有两个指针pre和next,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。但你有没有考虑一个问题,一般在64位系统中存储一个指针节点需要占多少内存,答案是8个字节,那么一个双向链表的指针节点至少占用16个字节(不包括数据域),如果实际数据较小的话,那不是指针的内存都比数据大了,得不偿失。
在ziplist中并不是这样设计的,你想java中这样设计是因为存储的方式是离散的,所以通过指针存储前驱节点或后继节点。而上面说过ziplist是由连续的内存块组成,那我们是不是就不用维护指向节点的双指针了,我只要知道上一节点的长度和当前entry的长度,我们就可以通过长度推算下一个元素在什么地方。即“时间换空间”
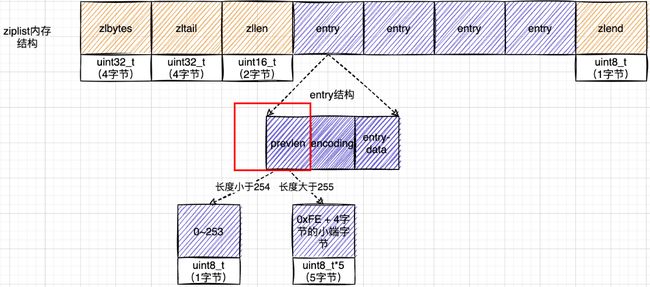
其结构如下:
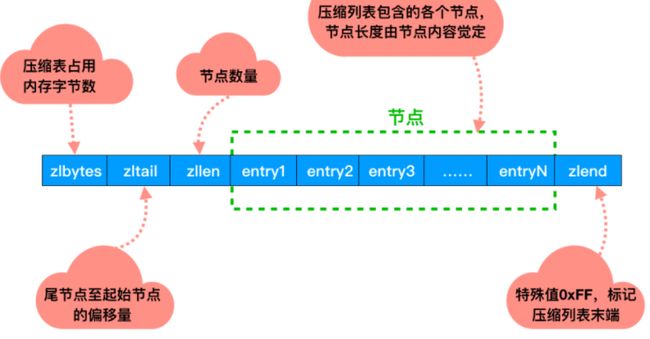


再介绍一下这个entry节点
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily.
*/
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度*/
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数*/
unsigned int len; /* 当前链表节点所占用长度 */
unsigned int headersize; /* 当前链表节点的头部大小:prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式*/
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;为什么entry这么设计?记录前一个节点的长度?
链表在内存中,一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题。如果知道了当前的起始地址,因为entry是连续的,entry后一定是另一个entry,想知道下一个entry的地址,只要将当前的起始地址加上当前entry总长度。如果还想遍历下一个entry,只要继续同样的操作。
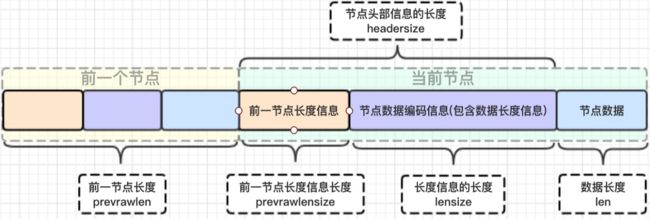
下面这个的出现让我卡顿了半天
再次贴一张entry结构的示意图:
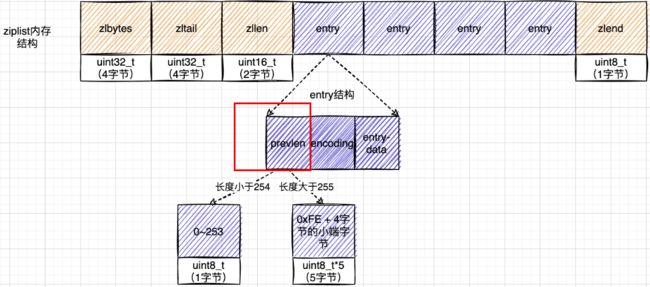
前节点:(前节点占用的内存字节数)表示前1个entry的长度,privious_entry_length有两种取值情况:1字节或5字节。取值1字节时,表示上一个entry的长度小于254字节。虽然1字节的值能表示的数值范围是0到255,但是压缩列表中zlend的取值默认是255,因此,就默认用255表示整个压缩列表的结束,其他表示长度的地方就不能再用255这个值了。所以,当上一个entry长度小于254字节时,prev_len取值为1字节,否则,就取值为5字节。记录长度的好处:占用内存小,1或者5个字节
| prevlen |
记录了前一个节点的长度; |
|
| encoding |
记录了当前节点实际数据的类型以及长度 |
|
| content |
即上面的 |
prevlen,encoding长度都可以根据编码方式推算,真正变化的是content,而content长度记录在encoding里 ,因此entry的长度就知道了。entry总长度 = prevlen字节数+encoding字节数+content字节数.
咦,entry的字段怎么变了,之前不是有7个字段吗,怎么只剩下3个了?
你是不是忘了最开始说过ziplist是一种特殊编码的双向链表,这个特殊编码就体现在这里。还有上面给的zlentry源码上有一段注释,不知道有没有注意:
We use this function to receive information about a ziplist entry.
Note that this is not how the data is actually encoded, is just what we get filled by a function in order to operate more easily.
所以,zlentry实际上并不是最终被编码的数据,它只是为了方便操作entry节点信息,使得更容易操作罢了。
那么谁才是编码处理后的节点呢?
答案是entry节点!!!
一句话:在存储前 zilentry 用来表示当前数据的信息,在将数据信息读取解压后也是用的 zlentry 来存储表示,但实际存储的是entry结构。zlentry 就是 entry 节点信息的一个承载对象。
entry结构的定义:
typede struct entry{
//前一个entry的长度
int prelen;
//元素类型编码
int encoding;
//元素内容
optional byte[] content;
}entry注意:这个在源文件中没有直接的定义,而是由一个或多个字节组成,每个entry节点的字节格式如下:
|||| 这里其实我也不是很理解,不知道是怎么定义的entry!应该是直接通过变量排列存储的。如果有大佬知道的话,希望指点一下,感激不尽!
编解码
既然上面讲了需要编码解码,那就讲讲相关操作。
先把zlentry的结构放这里:
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度*/
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数*/
unsigned int len; /* 当前链表节点所占用长度 */
unsigned int headersize; /* 当前链表节点的头部大小:prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式*/
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;/* Fills a struct with all information about an entry.
* This function is the "unsafe" alternative to the one blow.
* Generally, all function that return a pointer to an element in the ziplist
* will assert that this element is valid, so it can be freely used.
* Generally functions such ziplistGet assume the input pointer is already
* validated (since it's the return value of another function).
* 指针p指向某个节点的起始位置
* 函数 zipEntry 的作用是将给定的压缩列表节点解码为 zlentry 结构体,
* 该结构体包含了解码后的节点信息,包括前置节点的长度、当前节点存储的数据长度、
* 编码方式等。因此,参数 p 指向的是编码后的节点 entry。
*/
static inline void zipEntry(unsigned char *p, zlentry *e) {
// 从p指向的位置解码出前一个条目的长度,
//并将其存储在e->prevrawlen和e->prevrawlensize中
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
// 从p + e->prevrawlensize指向的位置读取出当前条目的编码方式,
// 并将其存储在e->encoding中
ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding);
// 根据e->encoding从p + e->prevrawlensize指向的位置解码出当前条目的长度,
// 并将其存储在e->len和e->lensize中
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
// 检查e->lensize是否为0,如果为0则表示编码方式无效,程序会终止
assert(e->lensize != 0); /* check that encoding was valid. */
// 计算出当前条目的头部大小(包括前一个条目的长度和当前条目的长度)
// 并将其存储在e->headersize中
e->headersize = e->prevrawlensize + e->lensize;
// 将p指针赋值给e->p,表示当前条目在压缩列表中的位置
e->p = p;
}
/* Return the number of bytes used to encode the length of the previous
* entry. The length is returned by setting the var 'prevlensize'.
* 用来从给定的指针 p 中解码出前一个节点的长度是用 1 个字节还是 5 个字节来编码的
* 如果 p 指向的第一个字节的值小于 ZIP_BIG_PREVLEN(254),
* 那么说明前一个节点的长度是用 1 个字节来编码的,将 prevlensize 赋值为 1。
* 否则,说明前一个节点的长度是用 5 个字节来编码的,将 prevlensize 赋值为 5
*/
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIG_PREVLEN) { \
(prevlensize) = 1; \
} else { \
(prevlensize) = 5; \
} \
} while(0)
/* Return the length of the previous element, and the number of bytes that
* are used in order to encode the previous element length.
* 'ptr' must point to the prevlen prefix of an entry (that encodes the
* length of the previous entry in order to navigate the elements backward).
* The length of the previous entry is stored in 'prevlen', the number of
* bytes needed to encode the previous entry length are stored in
* 'prevlensize'.
* 用来从给定的指针 ptr 中解码出前一个节点的长度和编码所需的字节数,
* 并分别赋值给 e->prevrawlensize 和 e->prevrawlen
* 注:这里ptr是指zlentry
*/
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do {
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else { /* prevlensize == 5 */
// 这里就是之前说的前一节点长度存的是1字节或者5字节(0xFE + 4字节的小端字节)
(prevlen) = ((ptr)[4] << 24) | \
((ptr)[3] << 16) | \
((ptr)[2] << 8) | \
((ptr)[1]); \
} \
} while(0)
/* Extract the encoding from the byte pointed by 'ptr' and set it into
* 'encoding' field of the zlentry structure.
* 从ptr + e->prevrawlensize指向的位置读取出条目的编码方式,
* 并将其存储在e->encoding中。
* ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding)
*/
#define ZIP_ENTRY_ENCODING(ptr, encoding) do {
(encoding) = ((ptr)[0]);
// 如果编码方式小于 ZIP_STR_MASK,则说明该节点存储的是字符串类型数据,
// 编码方式即为字符串的长度,否则编码方式表示节点存储的是整数类型数据的编码方式,
// 需要根据编码方式再解析出整数的实际长度。
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK;
} while(0)注:上述代码中ptr[0]指的是所指向内存的第一个字节,即压缩列表节点的头部信息的第一个字节.在压缩列表节点中,第一个字节保存了节点的编码方式和长度信息。
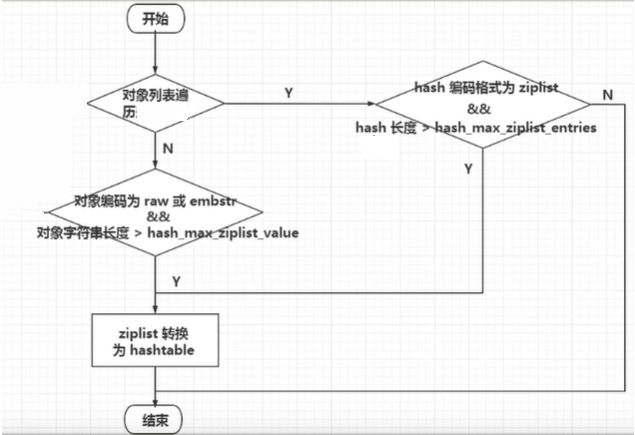
压缩列表和哈希表的转换
压缩列表和哈希表的转换是根据一些条件来进行的,比如元素的个数、元素的大小等。当压缩列表满足一定的条件时,就会转换为哈希表。具体的转换过程如下:当压缩列表中的元素个数或者元素大小超过了一定的阈值时,就会触发转换为哈希表的操作。这样可以避免压缩列表占用过多的内存空间,也可以提高查找和修改的效率。
一旦从压缩列表转为了哈希表,Hash类型就会一直用哈希表进行保存而不会再转回压缩列表了。
在节省内存空间方面哈希表就没有压缩列表高效了。
连锁更新
尽管ziplist有着非常多的优势,但你有考虑过一个问题吗?
ziplist分配的内存是连续的,但每个节点的长度又是可变长的。即当一个节点被更新时,如果更新后的数据长度和原始数据长度相同,那么只需要直接更新节点中的数据即可。但是,如果更新后的数据长度不同,就需要进行节点的重新分配和移动。这会导致当前节点后面的节点所保存的数据的内存地址发生了变化,因此需要将当前节点后面的所有节点都移动到新的内存地址。这个过程会连锁反应到后续的节点,直到最后一个节点,如果最后一个节点也需要移动,那么就需要重新分配整个 ziplist 的内存空间,将所有节点都移动到新的内存地址。
这就是 ziplist 的连锁更新问题,所以Redis7后弃用了ziplist结构,采用了另一种数据结构紧凑列表listpack(后面介绍)。
案例说明
压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患
第一步:现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图:

因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值,一切OK,O(∩_∩)O哈哈~
第二步:这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为entry1的前置节点,如下图:

因为entry1节点的prevlen属性只有1个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作并将entry1节点的prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。
第三步:连续更新问题出现
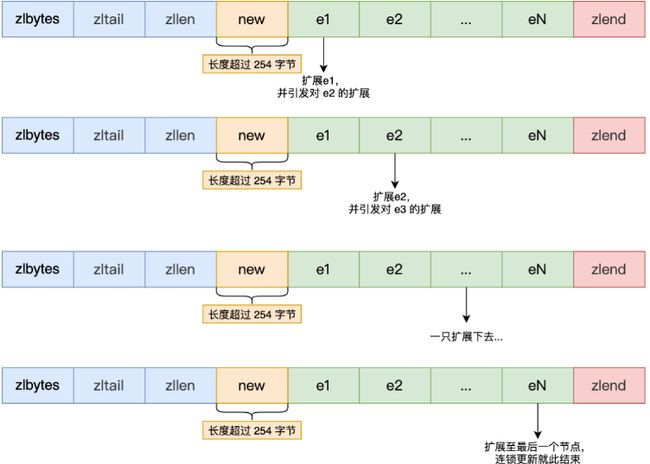
entry1节点原本的长度在250~253之间,因为刚才的扩展空间,此时entry1节点的长度就大于等于254,因此原本entry2节点保存entry1节点的 prevlen属性也必须从1字节扩展至5字节大小。entry1节点影响entry2节点,entry2节点影响entry3节点......一直持续到结尾。这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」
listpack
结构分析
上面有说过ziplist结构会产生连锁更新问题,所以Redis7中 设计了紧凑列表listpack,用来取代掉 ziplist 的数据结构,它通过每个节点记录自己的长度且放在节点的尾部,来彻底解决掉了 ziplist 存在的连锁更新的问题。
紧凑列表(listpack)是一种紧凑的列表存储方式,它用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack 列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。
下面是listpack的底层结构:
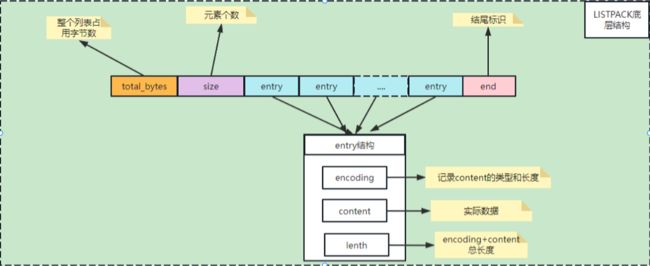
| Total Bytes |
为整个listpack的空间大小,占用4个字节,每个listpack最多占用4294967295Bytes。 |
| size |
为listpack中的元素个数,即Entry的个数占用2个字节 |
| entry |
为每个具体的元素 |
| end |
为listpack结束标志,占用1个字节,内容为0xFF。 |
从定义可以看出,紧凑列表由一个字节数组和一些辅助信息组成,其中字节数组存储着所有的元素,辅助信息则记录了列表数据的长度、空闲空间大小和元素个数等信息。
紧凑列表中的每个元素都由一个或多个entry组成,一个entry包含一个编码类型、一个指向数据的指针和数据的长度。其中编码类型表示数据的类型和编码方式,指向数据的指针指向数据在字节数组中的起始位置,数据的长度则表示该entry中数据的长度。一个entry可以表示不同类型的数据,例如字符串、整数、浮点数等。
分析一下entry结构, 由于 Redis7.0 已经将 listpack 完整替代 ziplist,所以下面是 基于7.0版本介绍。在Redis 7中,entry的定义如下:
/* Each entry in the listpack is either a string or an integer. */
typedef struct {
/* When string is used, it is provided with the length (slen).
* 表示当前节点存储的字符串类型的数据,指向一个连续的内存块。
*/
unsigned char *sval;
// 表示当前节点存储的字符串类型的数据的长度
uint32_t slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
// 表示当前节点存储的整数类型的数据。
long long lval;
} listpackEntry;可以看出,不同于ziplist,listpackEntry中的len记录的是当前entry的长度,而非上一个entry的长度。listpackEntry中可存储的为字符串或整型。
- 当存储的为字符串,那么lsentry的sval不为空,slen记录大小。
- 当存储的为整形,那么lval记录整型,sval字段为空
有没有发现
entry结构和上面给的图属性不一致,我也被绕晕了,翻了源代码文件,都没有找到上面图中具体的entry结构的定义,估计和之前的ziplistentry结构一样。所以我的理解是,在 Redis 6.0 中,
listpack的节点是以连续内存块的方式存储的,每个节点的格式是固定的。节点的格式如下:+-------+--------+-------+--------+-----//---------+
| prev | size | enc | data | next node |
| len | (1,5,9)| (1) | ... | offset |
+-------+--------+-------+--------+-----//---------+
而在Redis7中,进行了优化,引入了新的 listpackEntry 结构体(之前是连续的内存块存储),这里我就不讲了(因为我也不会,希望路过大佬教教)
ziplist 和listpack 对比
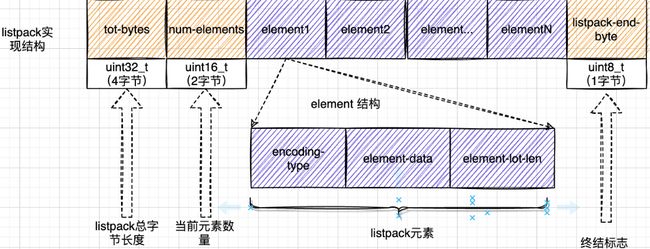
和ziplist 列表项类似,listpack 列表项也包含了元数据信息和数据本身。不过,为了避免ziplist引起的连锁更新问题,listpack 中的每个列表项不再像ziplist列表项那样保存其前一个列表项的长度。
紧凑列表相比于压缩链表,有以下几个优点:
- 更节省内存空间:紧凑列表将所有的值紧凑地存储在一块连续的内存空间中,没有额外的指针开销。同时,紧凑列表会根据值的大小动态选择合适的字节数来存储,避免浪费内存。此外,紧凑列表还会对相邻的小整数进行编码优化,进一步节省空间。
- 支持更快地在两端插入或删除值:紧凑列表可以在O(1)时间内在列表的头部或尾部插入或删除值,与压缩链表一样。但是,紧凑列表在插入或删除值时,不需要移动后面所有值的内存空间,而是通过一种差分编码技术来更新后面所有值的长度信息,提高效率。
- 支持更快地获取指定位置或范围内的值:紧凑列表可以在O(1)时间内获取列表的头部或尾部的值,或者在O(log n)时间内获取指定位置上的值,或者在O(n)时间内获取指定范围内的所有值。与压缩链表相比,紧凑列表在获取指定位置上的值时,不需要从头或尾开始遍历,而是通过二分查找来定位到目标位置,提高效率。
对于紧凑列表来说,虽然它具有一定的优势,但也有其明显的缺点。
- 由于它采用的是一段连续的字节数组来存储多个元素,因此在对元素进行修改时需要对整个字节数组进行重新分配。这样的操作可能会导致大量的内存复制操作,从而影响性能。
- 在进行元素查找时,需要遍历整个字节数组才能找到目标元素,这也会带来一定的性能损失。
因此,在实际使用中,我们需要根据数据类型的特点来选择合适的数据结构来存储数据。
- 如果我们需要存储一些单一类型的数据,那么使用整数数组或者压缩列表可能更为适合。
- 如果我们需要存储一些复杂类型的数据,比如哈希表或者跳表等,那么我们可以考虑使用这些数据结构来存储数据。
当然,在具体选择数据结构时,还需要考虑访问模式、数据规模、并发性等因素,综合考虑选择最优的方案。如果数据的类型比较简单,而且经常需要进行修改操作,那么使用快速列表可能会更为适合。而如果数据类型比较复杂,而且对存储空间的利用效率要求比较高,那么使用紧凑列表可能会更为合适。
参考资料
Redis 哈希(Hash)
Redis底层数据结构之hash
图解redis五种数据结构底层实现(动图哦)
[Redis]-数据结构-Hash介绍