Python---正则表达式
专栏:python
个人主页:HaiFan.
专栏简介:Python在学,希望能够得到各位的支持!!!
正则表达式
- 前言
- 概念
- 作用和特点
- 使用场景
- 正则符号
- re模块
-
- re.compile()
- match()
- search()
- span()
- findall()
- group()
- sub()
- split()
前言
概念
正则表达式是对字符串(包括普通字符(如a到z之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符,及其这些特定字符的组合,组成一个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述搜索文本时要匹配一个或多个字符串
正则表达式又称正规表达式,正规表示法,规则表达式,常规表达式,(英语:Regular Expression,在代码中简写为regex,regexp或RE),是计算机科学的一概念,正则表达式使用单个字符串来描述,匹配一系列匹配某个句法规则的字符串,在很多文本编辑器里,正则表达式通常被用来检索,替换那些匹配的某个模式的文本。
来源百度百科
作用和特点
给定一个正则表达式和另一个字符串,我们可以达到如下目的
- 给定字符串是否符合正则表达式的过滤逻辑(匹配)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
使用场景
如何判断一个字符串是手机号?
判断邮箱为163或者123的所有合法邮箱地址
正则符号
\A:表示从字符串的开始处匹配
\Z:表示从字符串的结束处匹配,如果存在执行,只匹配到换行前的结束字符串
\b:匹配一个单词边界,也就是说指单词和空格间的位置。
\B:匹配非单词边界。
\d:匹配任意数字,等价于---[0-9]
\D:匹配任意非数字字符,等价于---[^\d]
\s:匹配任意空白字符,等价于---[\t\n\r\f]
\S:匹配任意非空白字符,等价于---[^\s]
\w:匹配任意字母数字及下划线,等价于---[a-zA-Z0-9]
\W:匹配任意非字母数字及下划线,等价于---[^\w]
\\:匹配原义的反斜杠\
---------------------------------------
[]:用于表示一组字符,如果^事第一个字符,则表示的是一个补集,比如[0-9]表示所有的数字,[^0-9]表示除了数字外的字符
.:用于匹配除换行符之外的所有字符
^:用于匹配字符串的开始.及行首
$:用于匹配字符串的末尾(末尾如果有换行符,就匹配换行符前面的那个字符),及行尾
*:用于将前面的模式匹配0次或多次(贪婪模式,及尽可能多的匹配)
+:用于将前面的模式匹配1次或多次(贪婪模式)
?:用于将前面的模式匹配0次或1次(贪婪模式)
*?,+?,??是上面三种特殊字符的非贪婪模式(尽可能少的匹配)
{m}:用于验证将前面的模式匹配m次
{m,}:用于验证将前面的模式匹配m次或者多次---> >= m次
{m,n}:用于将前面的模式匹配m次到n次(贪婪模式),即最小匹配m次,最大匹配n次
{m,n}?即上面{m,n}的非贪婪模式
\\:\是转义字符,在特殊字符前面加上\,特殊字符就失去了其所代表的含义,比如\+就仅仅代表加号本身
|:比如A|B用于匹配A或B
re模块
在Python中,使用正则表达式要导入 re模块
import re
re.compile()
complie函数用于编译正则表达式,生成一个正则表达式(Pattern)对像,供match()和search()这两个函数使用

如何使用:re.compile(pattern,flags)
这个pattern就是一个字符串形式的正则表达式,flags可选,意思是匹配模式,比如:忽略大小写等
import re
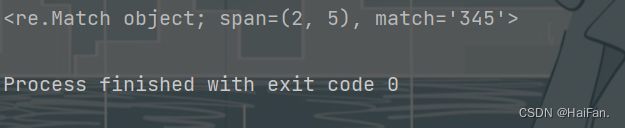
msg = '123456'
ret = re.compile('345')
a = ret.search(msg)
print(a)
这个search是什么,暂时不要关心,后面会说。
通过re.compile('345)可以返回一个正则对象,在这里用的ret来接收,然后通过ret.就可以调用一系列的方法,如match,search等等。当然re模块也提供了与这些方法功能一样的函数,这些函数的第一个参数是模式串。
![]()
match()

re.match是从字符串的起始位置开始匹配,若没有匹配成功,则返回none。匹配成功则返回第一个匹配的对象
# 语法:
re.match(pattern, string, flags=0):
第一个参数pattern:匹配的正则表达式
第二个参数string:要匹配的字符串
第三个参数flags:匹配方式,如:字母大小写的区分等
import re
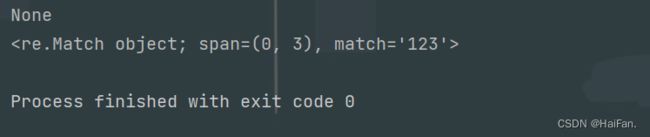
msg = '123456'
a = re.match('345',msg)
b = re.match('123',msg)
print(a)
print(b)
search()

从头至尾的扫描字符串,若有匹配的则返回第一次匹配的对象,若没有发现的话,就但会None
# 语法
re.search(pattern, string, flags=0):
第一个参数pattern:匹配的正则表达式
第二个参数string:要匹配的字符串
第三个参数flags:匹配方式,如:字母大小写的区分等
import re
msg = '123456'
a = re.search('345',msg)
b = re.search('456',msg)
c = re.search('123',msg)
d = re.search('245',msg)
print(a)
print(b)
print(c)
print(d)
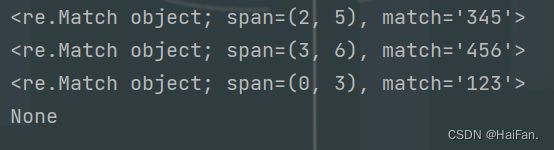
span()
在match或者search匹配成功后,返回第一个成功匹配的位置,通过span可以只显示匹配成功的位置。
import re
msg = '123456'
a = re.search('345',msg)
print(a.span())
![]()
findall()
在字符串中找到锁匹配的所有字串,返回一个列表,没有找到能够匹配的,则返回一个空列表。
# 语法
re.findall(pattern, string, flags=0):
第一个参数pattern:匹配的正则表达式
第二个参数string:要匹配的字符串
第三个参数flags:匹配方式,如:字母大小写的区分等
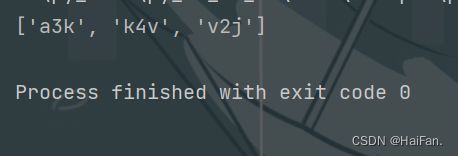
import re
msg = 'AS4DFJ352a3k43jkjv24k4vj234vj234j234jkjv2j4v'
a = re.findall('[a-z][0-9][a-z]',msg)
# [a-z]表示a到z的所有字母
# [0-9]表示9个数字
print(a)
group()
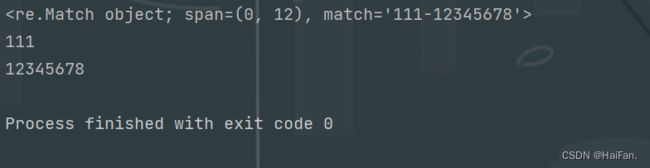
import re
msg = '111-12345678'
ret = re.match(r'(\d{3}|d{4})-(\d{8})$',msg)
# \d表示匹配任意数字,{3}表示将前面的模式串匹配3次
# $:用于匹配字符串的末尾(末尾如果有换行符,就匹配换行符前面的那个字符),及行尾
print(ret)
print(ret.group(1))
print(ret.group(2))
括号表示分组,group(1)表示第一组内容,group(2)表示第二组内容
sub()
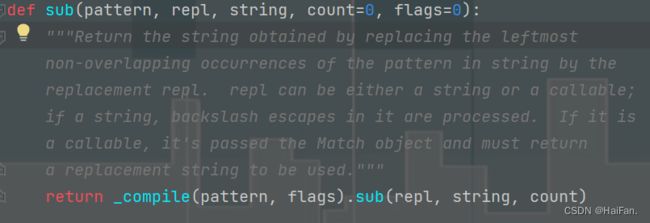
正则表达式可以将所有匹配的字符串用不同的字符串进行替换,sub方法提供一个替换值,可以是字符串或者函数,和一个要被处理的字符串。
第一个参数pattern:匹配的正则表达式
第二个参数repl:要替换的内容
第三个参数string:要匹配的
第四个参数count:这是一个可选参数,意思是最大替换次数
第五个参数flags:匹配方式,如:字母大小写的区分等
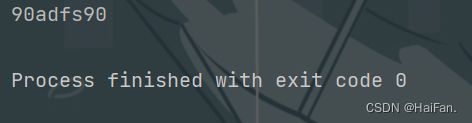
import re
msg = '465423adfs564'
ret = re.sub(r'\d+','90',msg)
print(ret)
import re
def add(temp):
num = temp.group()
num = int(num)
num += 1
return str(num)
ret = re.sub(r'\d+',add,'py:100,java:200')
print(ret)
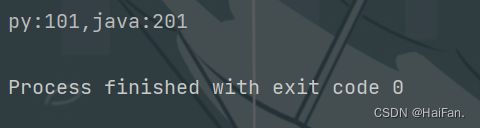
通过\d+可以找到100和200这个字符串,然后进入add函数,执行temp.group(),第一次执行会把100拿出来给num,第二次会把200拿出来。
split()
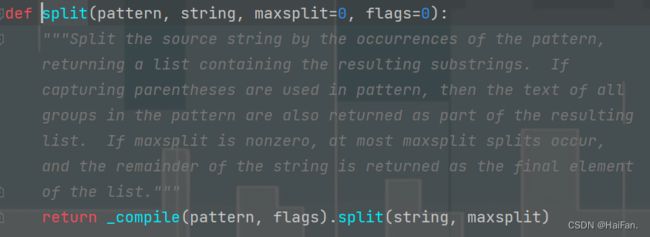
这个方法是用于惊醒字符串的分割,将分割之后的内容保存在列表中。
#语法
re.split(pattern, string, maxsplit=0, flags=0):
第一个参数pattern:匹配的正则表达式
第二个参数string:要匹配的字符串
第三个参数maxsplit:分割次数
第四个参数flags:匹配方式,如:字母大小写的区分等
import re
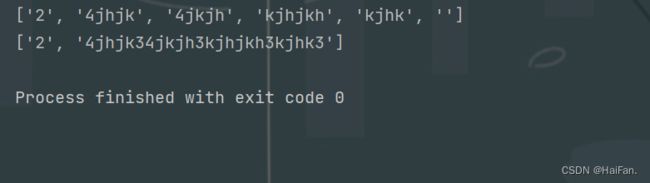
msg = '234jhjk34jkjh3kjhjkh3kjhk3'
ret = re.split(r'[3]',msg)
print(ret)
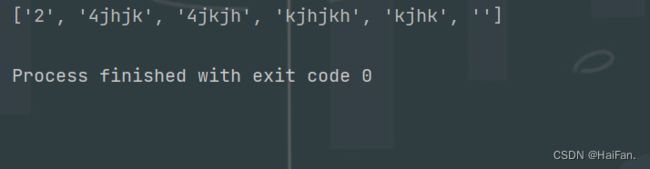
import re
msg = '234jhjk34jkjh3kjhjkh3kjhk3'
ret = re.split(r'[3]',msg,maxsplit=0)
ret1 = re.split(r'[3]',msg,maxsplit=1)
print(ret)
print(ret1)