图神经网络-针对异构图的预测问题,以及每种网络可以用于的任务类型
目录
-
- 异构图介绍
- 异构图神经网络简介
- 异构图神经网络任务介绍
-
-
- Heterogeneous Graph Neural Network (HetGNN)
- Relation-aware Graph Convolutional Networks (R-GCN)
- Heterogeneous Information Network Embedding (HINE)
- Heterogeneous Graph Attention Network (HAN)
- Graph Transformer Networks for Heterogeneous Information Networks (GTN)
-
异构图介绍
异构图是一种包含不同类型节点和边的图,其中节点可以表示不同种类的实体,而边可以表示不同类型的关系。换句话说,异构图是一种具有多样性和复杂性的图数据结构,其节点和边具有不同的语义和属性。
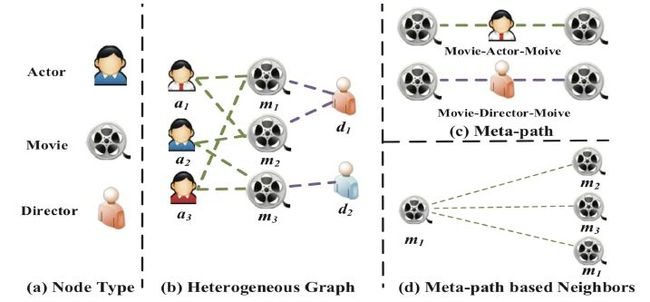
在异构图中,不同类型节点之间的关系是不同的,因此节点之间的连接方式和含义也不同。例如,在一个包含学生、老师和课程的异构图中,学生和老师之间的联系可能是指导关系,而学生和课程之间的联系可能是选课关系。此外,异构图中的边可以具有不同的属性和权重,比如时间、距离、强度等,这也增加了图分析的难度和挑战。
在实际应用中,异构图广泛应用于社交网络分析、知识图谱构建、推荐系统等领域。对异构图的建模和分析是图神经网络领域的重要研究方向之一,目前有许多针对异构图的图神经网络算法被提出并得到了广泛的应用。
异构图神经网络简介
针对异构图的预测问题,目前有一些常用的图神经网络算法,以下列举其中几个:
Heterogeneous Graph Neural Network (HetGNN):HetGNN 是一种用于异构图的图神经网络算法,能够进行异构图节点的分类、排序等任务。该算法使用了异构注意力网络(HAN)进行节点特征的聚合,从而提高了分类准确率。
Relation-aware Graph Convolutional Networks (R-GCN):R-GCN 是一种基于图卷积网络(GCN)的异构图神经网络算法,能够进行异构图节点分类、链接预测等任务。R-GCN 引入了关系矩阵来表示不同类型节点之间的关系,并使用了一种特殊的卷积操作来处理异构图的结构。
Heterogeneous Information Network Embedding (HINE):HINE 是一种用于异构图嵌入学习的算法,它将异构图中不同类型的节点和边转化为低维向量表示,从而方便进行后续的分析和预测任务。HINE 引入了多层神经网络来学习节点的嵌入表示,并使用了一种基于采样的负采样方法来提高嵌入的准确性。
Heterogeneous Graph Attention Network (HAN) : 是一种用于异构图的图神经网络算法,其核心是异构图注意力网络。具体来说,该算法首先利用多层 GCN 对每个节点进行表示学习。然后,针对每个节点的不同类型邻居节点,分别使用注意力机制进行加权聚合,得到不同类型邻居节点的特征表示。最后,将聚合后的不同类型节点特征拼接起来,再送入全连接层进行分类或链接预测等任务。
Graph Transformer Networks (GTN): 利用了 Transformer 的注意力机制来进行异构图节点的表示学习。具体来说,该算法首先使用多层 GCN 对每个节点进行表示学习,然后将不同类型节点的特征向量进行拼接。接着,利用 Transformer 的注意力机制来对节点之间的依赖关系进行建模和学习,得到节点的新的特征表示。最后,将新的节点特征向量送入全连接层进行分类或链接预测等任务。
异构图神经网络任务介绍
Heterogeneous Graph Neural Network (HetGNN)
任务:节点分类、排序等任务。
算法原理:HetGNN 利用异构注意力网络(HAN)对不同类型节点的信息进行聚合。具体来说,HAN 由两个注意力机制组成:第一个机制用于学习不同类型节点之间的权重,第二个机制用于学习每个节点邻居节点的权重。然后,将节点特征和邻居特征进行结合,得到节点新的特征表示。最后,将新的节点特征送入全连接层进行分类或排序。
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 定义 HetGNN 模型的类
class HetGNN(nn.Module):
def __init__(self, num_types, hidden_dim, output_dim, learning_rate, dropout_rate, num_iterations):
super(HetGNN, self).__init__()
self.num_types = num_types
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.learning_rate = learning_rate
self.dropout_rate = dropout_rate
self.num_iterations = num_iterations
self.adj_list = []
self.feat_list = []
self.label_list = []
self.num_nodes_list = []
self.adj_matrices = []
self.weights = nn.ParameterList([nn.Parameter(torch.FloatTensor(hidden_dim, output_dim)) for _ in range(num_types)])
self.biases = nn.ParameterList([nn.Parameter(torch.FloatTensor(output_dim)) for _ in range(num_types)])
self.losses = []
self.build()
def build(self):
self.placeholders()
self.forward_pass()
self.backward_pass()
def placeholders(self):
self.adj_mats = [None] * self.num_types
self.node_feats = [None] * self.num_types
self.node_labels = None
self.num_nodes = [None] * self.num_types
self.dropout = nn.Dropout(p=self.dropout_rate)
def forward_pass(self):
for i in range(self.num_types):
h = nn.Linear(self.feat_list[i].shape[1], self.hidden_dim)(self.node_feats[i])
for j in range(self.num_iterations):
h = self.dropout(h)
h = torch.sparse.mm(self.adj_mats[i], h)
h = nn.Linear(self.hidden_dim, self.hidden_dim)(h)
logits = []
for i in range(self.num_types):
logits.append(torch.mm(torch.mul(h, self.node_feats[i]), self.weights[i]) + self.biases[i])
self.logits = torch.cat(logits, dim=0)
def backward_pass(self):
self.loss = F.cross_entropy(self.logits, self.node_labels)
for i in range(self.num_types):
self.loss += 0.5 * torch.mean(torch.pow(self.weights[i], 2))
self.optimizer = optim.Adam(self.parameters(), lr=self.learning_rate)
def train(self, adj_list, feat_list, label_list, num_nodes_list, num_epochs, batch_size):
self.adj_list = adj_list
self.feat_list = feat_list
self.label_list = label_list
self.num_nodes_list = num_nodes_list
self.adj_matrices = [self.normalize_adj(adj) for adj in self.adj_list]
self.node_labels = torch.LongTensor(self.label_list)
self.node_feats = [torch.FloatTensor(feat) for feat in self.feat_list]
for epoch in range(num_epochs):
trainset = GraphDataset(self.adj_matrices, self.node_feats, self.node_labels, self.num_nodes)
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels, num_nodes = data
self.adj_mats = inputs
self.node_labels = labels
self.num_nodes = num_nodes
self.optimizer.zero_grad()
self.forward_pass()
self.backward_pass()
self.loss.backward()
self.optimizer.step()
running_loss += self.loss.item()
epoch_loss = running_loss / len(trainloader)
self.losses.append(epoch_loss)
print(f"Epoch {epoch+1} loss: {epoch_loss:.4f}")
def normalize_adj(self, adj):
rowsum = torch.FloatTensor(adj.sum(1))
degree_mat_inv_sqrt = torch.diag(torch.pow(rowsum, -0.5).flatten())
normalized_adj = torch.mm(torch.mm(degree_mat_inv_sqrt, adj), degree_mat_inv_sqrt)
return normalized_adj
# 定义一个用于加载图数据的 Dataset 类
class GraphDataset(Dataset):
def __init__(self, adj_matrices, node_feats, node_labels, num_nodes):
self.adj_matrices = adj_matrices
self.node_feats = node_feats
self.node_labels = node_labels
self.num_nodes = num_nodes
def __len__(self):
return len(self.node_labels)
def __getitem__(self, idx):
inputs = [adj[idx].to_sparse() for adj in self.adj_matrices]
labels = self.node_labels[idx]
num_nodes = self.num_nodes
return inputs, labels, num_nodes
Relation-aware Graph Convolutional Networks (R-GCN)
任务:节点分类、链接预测等任务。
算法原理:R-GCN 引入了关系矩阵来表示不同类型节点之间的关系,并使用了一种特殊的卷积操作来处理异构图的结构。具体来说,该卷积操作将节点的特征和关系矩阵进行卷积,得到每个节点的新特征表示。然后,将新特征表示送入全连接层进行分类或链接预测等任务。
Heterogeneous Information Network Embedding (HINE)
任务:节点嵌入学习、相似度计算等任务。
算法原理:HINE 引入了多层神经网络来学习节点的嵌入表示,并使用了一种基于采样的负采样方法来提高嵌入的准确性。具体来说,该算法将异构图中不同类型的节点和边转化为低维向量表示,通过多层神经网络进行学习。在每一层神经网络中,节点的邻居节点会被随机采样一定数量的节点,用于学习当前节点的嵌入表示。最后,将每个节点的嵌入向量作为其特征向量,进行节点相似度计算等任务。
Heterogeneous Graph Attention Network (HAN)
任务:节点分类、链接预测、图分类等任务。
算法原理:HAN 是一种用于异构图的图神经网络算法,其核心是异构图注意力网络。具体来说,该算法首先利用多层 GCN 对每个节点进行表示学习。然后,针对每个节点的不同类型邻居节点,分别使用注意力机制进行加权聚合,得到不同类型邻居节点的特征表示。最后,将聚合后的不同类型节点特征拼接起来,再送入全连接层进行分类或链接预测等任务。
与其他算法相比,HAN 更加关注异构图中不同类型节点之间的关系,并通过注意力机制对节点的不同邻居进行不同程度的加权。这种机制可以更好地捕捉节点之间的依赖关系和差异性,从而提高分类和预测的准确性。
Graph Transformer Networks for Heterogeneous Information Networks (GTN)
任务:节点分类、链接预测、图分类等任务。
算法原理:GTN 利用了 Transformer 的注意力机制来进行异构图节点的表示学习。具体来说,该算法首先使用多层 GCN 对每个节点进行表示学习,然后将不同类型节点的特征向量进行拼接。接着,利用 Transformer 的注意力机制来对节点之间的依赖关系进行建模和学习,得到节点的新的特征表示。最后,将新的节点特征向量送入全连接层进行分类或链接预测等任务。
与其他算法相比,GTN 的注意力机制具有更好的建模能力,可以充分利用异构图中不同类型节点之间的关系。此外,该算法可以通过多层 Transformer 模块进行深度表示学习,从而更好地提取异构图中的特征信息。