论文阅读-Fairness-aware Personalized Ranking Recommendation viaAdversarial Learning
摘要
推荐算法通常基于历史用户-项目交互(例如,点击、喜欢或评级)构建模型,以提供个性化的项目排序列表。由于用户偏好的不同,这些交互通常不均匀地分布在不同的项目组上。然而,作者表明,推荐算法可以继承甚至放大这种不平衡的分布,导致对项目组的不公平推荐。具体地说,作者将基于排名的统计均等(statistical parity)和机会均等(equal opportunity)的概念形式化为项目组个性化排名推荐中公平的两个衡量标准。然后,经验表明,最广泛采用的算法之一——贝叶斯个性化排序——产生了不公平的推荐,这促使作者努力提出新的公平感知个性化排序模型。该去偏模型能够在保持推荐性能的同时,提高这两种公平性指标。在三个公共数据集上的实验表明,与最先进的替代方案相比,所提出的模型有很强的公平性改进。

1 介绍
推荐器提出的社会和伦理问题越来越受到关注,包括过滤气泡、透明度和问责制等问题。特别是,项目推荐不公平——其中一个或多组项目被系统地降低了推荐机会——是个性化排名推荐者中最常见但最有害的问题之一。在用于学习推荐器的场景中,训练数据由于在真实世界的中固有的偏好分布不均匀,对不同项目组的反馈分布并不均匀。例如,非营利性工作的广告可能会以比高薪工作更低的速度被点击,因此,针对这个倾斜数据进行训练的推荐模型将继承甚至放大这种不平衡的分布。这可能会导致非营利性工作的广告被不公平地降低推荐机会。
以往关于推荐公平性的研究主要集中在研究如何对不同项目组产生相似的预测得分分布(换句话说,通过消除预测偏好得分时群体信息的影响)这些工作的主要缺点是,它们主要关注于预测的偏好得分的角度。然而,在实践中,预测的分数是迈向作为最终推荐结果的项目排名列表的中间步骤,拥有相似的预测分数并不一定会导致公平的排名结果,这表明直接衡量公平比排名而不是分数的重要性。
以最常用的概念——统计均等(或人口均等)为例——例如,统计均等的公平性鼓励不同的群体有相似的预测分数。图1a显示了统计均等约束下的 一个示例,其中行表示用户,蓝色正方形和红色圆圈表示两组不同的项目。每组有三个项目。矩阵中的数字是从用户到项目的预测分数。这些项目按每个用户的分数按降序排序。前2个项目推荐给用户,一些圆圈和正方形项目中的黄色背景代表积极的基本事实。在本例中,蓝色平方组和红色圆组具有完全相同的分数分布(在此范围内的均匀分布[1.6,3.0])。但是,推荐结果对红色圆组是不公平的,因为只有两个项目。因此,我们提出了两种新的直接计算的公平指标——基于排名的统计均等(RSP)和基于排名的机会均等(REO)。
示例:基于排名的统计均等
与传统的基于分数的统计均等不同,RSP鼓励被推荐的不同组(排名在前中)的概率相似。图1b提供了RSP之后的一个示例,其中两组被排在前2位的概率都是1/3。然而,虽然RSP鼓励了一个公平的排名结果,但它忽略了内在的群体质量或用户偏好。然而,虽然RSP鼓励了一个公平的排名结果,但它忽略了数据内在的群体质量或用户偏好的不平衡,这可能会对主流群体造成不公平。例如,在图1a和图1b中,一些条目中的黄色背景表示被标记的项目具有相应用户喜欢的基本事实(即它形成了一个匹配的用户-项目对)。然后,作者看到蓝色正方形组比红色圆圈组更受用户的青睐,因为两组中正用户项目对的数量是8:4。因此,在图1b中保持相同的推荐概率对于蓝色平方组是不公平的。
示例:基于排名的机会平等
考虑到用户-项目匹配的基本真相,我们提出了度量REO,它鼓励被正确推荐给匹配的用户在项目组之间的概率是相同的。图1c给出了一个积极的例子,其中两个项目组对匹配用户排名前2的概率是1/2。图1a和图1b显示了负的例子,其中图1a中的排名结果有利于蓝色方块组,而图1b偏向于红色圆圈组。
由于RSP和REO独特的特点是不同的,适用于不同的场景。基于RSP的公平性通常很重要,对于被推荐的主题有敏感属性的情况,需要加强,比如当求职者被推荐给公司招聘时,考虑不同性别或种族的公平性。因为在这种情况下,社会伦理要求系统中不同人口统计群体相同的暴露概率。而基于REO的公平性适用于没有敏感属性的更一般的场景,比如电影或歌曲推荐。这些系统中REO的不公平可能会对用户和项目提供者产生破坏性影响。一方面,少数群体对应的用户需求没有得到充分承认,导致用户满意度较低。另一方面,少数群体的项目提供者可能得不到足够的风险敞口,从而损害他们的经济收益。
贡献
考虑到这两个指标,作者通过经验证明了一个基本的推荐模型——贝叶斯个性化排序(BPR——很容易受到不公平的影响,这激励了他们努力解决这个问题。然后,展示了如何通过无偏个性化排名模型(DPR)提高基于两个引入的指标的公平性。它有两个关键特征:一个多层感知器对抗,旨在提高项目组之间的分数分布相似性;以及一个基于KL发散的正则化术语,旨在规范化每个用户的分数分布。将这两个组件合并在一起,基于RSP(或REO取决于我们如何实现对抗学习)的公平性可以显著提高,同时保持推荐质量。在三个公共数据集上进行的广泛实验表明,所提出的模型比最先进的替代方案的有效性。一般来说,DPR能够将与BPR的两个指标相对应的不公平平均降低了67.3%(比最佳基线改善了48.7%),而仅将1@15与BPR平均降低了4.1%(比最佳基线提高16.4%)
相关工作
1.有考虑用户项匹配的基本真相;2.只考虑个别场景;3.考虑个体用户之间的公平性,而不考虑不同项目组的系统级公平性。
2 个性化排名的公平性
在本节中,首先描述了个性化排序问题,并通过处理贝叶斯个性化排序(BPR)来处理我们的讨论。接下来,我们介绍两个提出的个性化排序的公平指标。最后,我们通过经验证明,BPR容易受到数据偏差的影响,并倾向于产生不公平的建议。
2.1 贝叶斯个性化排名
给定用户U={1,2,…,}和项目I={1,2,…,},个性化排名问题是根据用户的历史行为I+={,,…},其中,,…是之前交互的项目(因此可以被视为隐含的正反馈)向每个用户推荐一个包含个项目的列表。贝叶斯个性化排序(BPR)是解决这一问题最具影响力的方法之一,它是许多前沿的个性化排序算法。BPR采用矩阵分解为基础,最小化成对排名损失,形式化为:

其中,![]() 和
和![]() 为用户对阳性项目和抽样负项目的矩阵分解模型计算出的预测偏好得分;(·)是sigmoid函数,∥·∥F是F范数,Θ表示模型参数,即Θ={P、Q},其中P和Q为用户和项目的潜在因子矩阵;而Θ是L2正则化的权衡权重。根据训练后的BPR,我们可以预测对所有未交互项目的偏好得分,并按user 的降序排序。top得分最大的项目列表{1,2,,…,}将被推荐给用户,其中是排名位置的项目id。
为用户对阳性项目和抽样负项目的矩阵分解模型计算出的预测偏好得分;(·)是sigmoid函数,∥·∥F是F范数,Θ表示模型参数,即Θ={P、Q},其中P和Q为用户和项目的潜在因子矩阵;而Θ是L2正则化的权衡权重。根据训练后的BPR,我们可以预测对所有未交互项目的偏好得分,并按user 的降序排序。top得分最大的项目列表{1,2,,…,}将被推荐给用户,其中是排名位置的项目id。
2.2 个性化排名的公平度指标
然而,在这样一个个性化的排名模型中,并没有公平的概念。在这里,假设有A个敏感项目组G{g1,g2,...gA},并且I中的每个项目属于G的中一个组。这里的一个组可以对应于性别、种族或其他项目属性。作者定义了一个函数()来确定项是否属于组,如果是,该函数返回1,否则返回0。公平意识推荐器的更高的目标是提高不同群体之间的公平性,以免任何群体被忽略。以往对推荐公平性的定义有两个主要缺点:(i)公平度量是根据预测分数计算的,与排名结果不对应;(ii)定义主要基于统计均等的概念,没有考虑用户项匹配的基本真相。因此,我们提出了两个新的公平性指标来衡量来自不同组的项目的排名。
基于排名的统计均等(RSP)
统计均等要求不同输入组的模型输出的概率分布是相同的。同样,对于个性化排序任务,统计均等性可以定义为强迫不同项目组的排序概率分布相同。因为传统上只将top-项目推荐给用户,我们关注在top-中排名的概率,这也与基本的推荐质量评估指标相一致,如精度@k和召回率@k。因此,作者提出了基于排名的统计均等度量度量-RSP,它鼓励(@|=1)=(@|=2)=…=(@|=),其中R@K代表在top-k中,(@|=)是组中项目排名在top-的概率。在形式上,我们计算的概率如下:
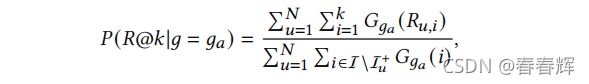
其中![]() 计算了ga中有多少未与用户u交互的项目出现在了top-k中,并且
计算了ga中有多少未与用户u交互的项目出现在了top-k中,并且![]() 计算有多少未交互的项目属于组。最后,计算概率上的相对标准差(对不同的保持相同的尺度),以确定@:
计算有多少未交互的项目属于组。最后,计算概率上的相对标准差(对不同的保持相同的尺度),以确定@:

其中,(·)计算标准差,(·)计算平均值。
基于排名的机会平等(REO)
本文的第二个指标是基于机会相等的的概念,它鼓励不同群体的真实阳性率(TPR)是相同的。以两个组的二元分类任务为例,机会均等要求:
![]()
其中为真实标签,![]() 为预测标签;(
为预测标签;(![]() =1|=0,=1)为第0组的TPR,(
=1|=0,=1)为第0组的TPR,(![]() =1|=1,=1)为第1组的TPR。 同样,在个性化排名系统中,机会均等要求不同群体基于排名的TPR相同。我们可以将TPR定义为用户真实喜欢的项目列在top-中的概率,记为(@|=,=1),其中=1表示用户喜欢的项目。概率可通过以下计算:
=1|=1,=1)为第1组的TPR。 同样,在个性化排名系统中,机会均等要求不同群体基于排名的TPR相同。我们可以将TPR定义为用户真实喜欢的项目列在top-中的概率,记为(@|=,=1),其中=1表示用户喜欢的项目。概率可通过以下计算:
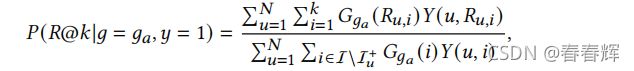
其中,(,,i)标识用户项对(,,i)的真实标签,如果用户喜欢项,则返回1,否则返回0。在实践中,(,)标识用户项对(,)是否在测试集中.![]() 计算测试集中有多少来自group 项目排名在top-,
计算测试集中有多少来自group 项目排名在top-,![]() 计算在用户的测试集中,来自组的项目总数。与RSP类似,计算相对标准差来确定@:
计算在用户的测试集中,来自组的项目总数。与RSP类似,计算相对标准差来确定@:

对于分类任务,TPR是分类的召回,对于个性化排序,概率(@|=,=1)是组的召回@k。换句话说,减轻基于REO的偏差需要不同的群体的@相似。
请注意,对于@和@,较低的值表明建议更公平。在实践中,RSP在推荐具有敏感属性的人类或物品(如政治新闻)时尤其重要。因为在这些情况下,基于RSP的公平会导致社会问题,比如招募过程中的性别歧视或竞选活动中的政治意识形态不公平。相反,基于REO的公平性应该在一般项目推荐系统中得到增强,这样就不会忽略用户需求,所有项目都有机会暴露给喜欢它们的匹配用户。
2.3 BPR很容易不公平
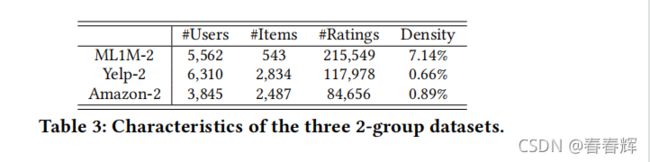
在本节中,经验表明,BPR容易受到不平衡数据的影响,并倾向于基于指标RSP和REO产生不公平的建议。由于没有与具有敏感属性的推荐公平性相关的标准公共数据集,我们采用了三个公共真实数据集,这些数据集在之前的工作中被广泛使用。然而,如果我们分析具有敏感特征的数据集的公平性,我们得出的结论仍然成立,因为基本问题的定义和导致不公平的机制与本文的实验完全相同。
Movielens-1M 是一个电影评级数据集,作者将所有评级视为表明用户对评级电影感兴趣的积极反馈。作者考虑了对“科幻”、“冒险”、“犯罪”、“浪漫”、“儿童”和“恐怖”等电影类型的推荐偏差,并删除了其他电影,最终保留了6036个用户、1481个项目和526,490次交互。
Amazon 包含了亚马逊电子商务平台上的产品评论。作者将用户购买行为视为积极反馈,并考虑“杂货”、“办公室”、“宠物”和“工具”等产品类别之间的推荐偏差,最终保留了4011个用户、2765个项目和118667个交互。
此外,表1列出了数据集中每一组的详细信息,包括项目的数量、反馈的数量以及它们之间的比率#/#。作者使用这个比率来识别内在的数据失衡。比率越高,用户就越喜欢这个组,所有组的比率的相对标准偏差可以表示数据集中的总体偏差。因此,亚马逊和ML1M数据集包含相对较高的偏差;Yelp的偏差较低,但美国(新)餐厅的#/#仍然是中餐馆的1.5倍左右。
我们在这些数据集上运行BPR,并分析排序概率分布。详细的模型超参数设置和数据分割见第4.2节。表2给出了BPR在三个数据集上的(@|)和(@|,=1),本文作者考虑了=5、10和15。作者还列出了@和@的指标。从表格来看,有三个主要的观察结果:

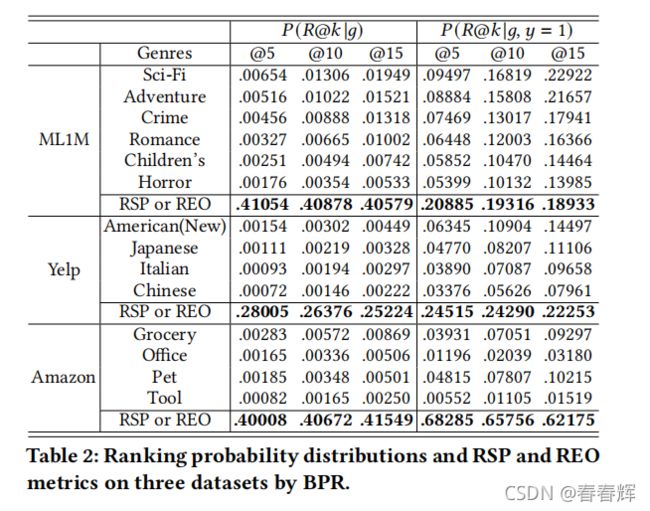
1.对于所有数据集,各组之间的排名概率非常不同,例如,在ML1M,(@5|=Sci-Fi)比(@5|=Horror)高4倍,(@5|=Sci-Fi,=1)比(@5|=Horror,=1)高两倍。所有和数据集的@和@值显示了BPR的推荐不公平。
2.所有数据集的(@|)和(@|,=1)分布基本遵循表1所示的#/#分布,有时排序概率分布的偏差甚至大于#/#分布,例如ML1M中(@15|)的相对标准偏差为0.4058,#/#的相对标准偏差为0.3344,表明BPR保留甚至放大了固有的数据不平衡。
3.随着的降低,@和@的值增加。换句话说,对于排名最高的项目,结果并不公平。这种现象对推荐器是不利的,因为随着排名的高,项目收到的关注迅速增加,排名最高的项目会得到用户更多的关注。
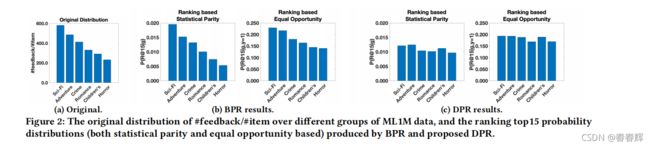
此外,作者还绘制了图2a中ML1M的原始#/#分布和图2b中BPR的排序概率分布,这直观上证实了作者的结论,即BPR继承了数据偏差,产生了不公平的推荐。这一结论激发了一个公平的个性化排名框架感知模型的设计。图2c显示了所提出的去偏个性化排序模型生成的排序概率分布,阐述了与BPR相比分布更均匀、更公平的推荐。
3 方法
之前关于公平意识推荐的工作主要集中于迫使不同的群体有相似的分数分布,这不一定会产生公平的个性化排名,如图1a所示。一个关键原因是用户有不同的评分标准,这意味着一个用户到一个项目的高分不一定会导致高排名,而低分数也不会导致低排名。相反,如果每个用户都有相同的分数分布,那么所有用户在top-内的分数值范围将是相同的,如图3a所示。然后,不同组得分分布(top-)的得分也将覆盖相同的值范围。最后,如图3b所示,如果我们对不同组执行相同的分数分布,top-分数在整个分布中的比例将是相同的,也就是说,我们对不同组有相同的概率(@|)(RSP的定义).

类似地,如果不同组中的正用户-项目对具有相同的分数分布(如( |,=1)),我们将对不同组具有相同的概率(@|,=1)(REO的定义),如图3c所示。基于这种直觉,所提出的DPR首先通过对抗性学习提高不同组间的得分分布相似性,然后通过Kullback-leibler发散(KL)损失将用户得分分布归一化为标准正态分布。我们将在以下小节中介绍DPR的两个组成部分和模型训练过程。
|,=1)),我们将对不同组具有相同的概率(@|,=1)(REO的定义),如图3c所示。基于这种直觉,所提出的DPR首先通过对抗性学习提高不同组间的得分分布相似性,然后通过Kullback-leibler发散(KL)损失将用户得分分布归一化为标准正态分布。我们将在以下小节中介绍DPR的两个组成部分和模型训练过程。
3.1 提高分数分布的相似性
对抗性学习已被广泛应用于监督学习,以增强模型的公平性,具有理论保证和最先进的经验性能.受这些工作的启发,作者建议利用对抗性学习来提高不同群体之间的分数分布相似性。首先以度量RSP为例阐述了该方法,然后将其推广到REO。最后,展示了所提出的对抗式学习方法相对于以前方法的优势。
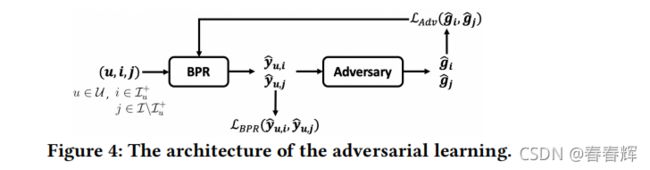
RSP的对抗 对抗性学习的直觉是在BPR模型和判别器之间进行极大极小的博弈。鉴别器是根据BPR预测的用户项目得分对项目组进行分类。BPR不仅需要最小化推荐误差,还需要防止鉴别器对组进行正确分类。如果鉴别器不能准确地识别给定的BPR输出的组,那么不同组的预测分数分布将是相同的。图4展示了对抗学习框架的架构,其中每个训练用户项对(,)首先输入到传统的BPR模型;然后将BPR的输出输入到多层感知器(MLP)中对给定项目i的组![]() 进行分类。
进行分类。![]() ∈
∈![]() 是sigmoid函数激活的MLP的最后一层的输出,表示属于每个组的概率,例如
是sigmoid函数激活的MLP的最后一层的输出,表示属于每个组的概率,例如![]() 表示i属于组的预测概率。MLP是对手,它通过最大化可能性L(g,
表示i属于组的预测概率。MLP是对手,它通过最大化可能性L(g,![]() )来训练,而BPR通过最小化公式1中所示的排名损失以及最小化对手目标L(g,bg)来训练。g∈{0,1}是项目的真实组,如果属于组,
)来训练,而BPR通过最小化公式1中所示的排名损失以及最小化对手目标L(g,bg)来训练。g∈{0,1}是项目的真实组,如果属于组,![]() =1,否则为0。采用对数似然法作为对抗的目标函数:
=1,否则为0。采用对数似然法作为对抗的目标函数:

其中,我们将L(g,![]() )简称为L(),Ψ是MLP对抗的参数。结合BPR模型,目标函数可表述为:
)简称为L(),Ψ是MLP对抗的参数。结合BPR模型,目标函数可表述为:
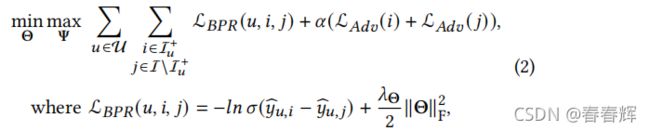
而是控制对抗性分量强度的权衡参数。
REO的对抗 至于REO,我们要求不同组的正用户项目对而不是所有的用户项目对的分数分布是相同的。因此,我们不需要将正的和抽样的负用户项对![]() 和
和![]() 的分数输入,而只需要将
的分数输入,而只需要将![]() 输入对抗网络中:
输入对抗网络中:

对抗性学习的优势 现有有两种方法可以实现类似的效果:基于正则化的方法;和潜在因子操作方法。与以往的工作相比,所提出的对抗性学习的优势可以总结为:(i)它可以提供比其他方法更有效的经验性能,这将在第后文中进一步证明;(ii)它可以灵活地交换不同的偏差指标(除了RSP和REO);(iii)它可以处理多组情况;(iv)它不与任何特定的推荐模型耦合,可以很容易地适应于BPR以外的方法(如更先进的神经网络)。
3.2 个人用户得分规范化
在实现分布相似性后,实现个性化排序公平性的下一步是对每个用户的评分分布进行标准化。我们可以假设每个用户的分数分布都遵循正态分布,因为基于原始的BPR论文,用户或项目潜在因素向量中的每个因量都遵循正态分布,然后![]() (对于给定的用户,P是一个常数,Q是一个正态随机变量的向量)也遵循正态分布。因此,可以通过最小化每个用户的得分分布和标准正态分布之间的KL差异作为KL损失,将每个用户的得分分布归一化为标准正态分布:
(对于给定的用户,P是一个常数,Q是一个正态随机变量的向量)也遵循正态分布。因此,可以通过最小化每个用户的得分分布和标准正态分布之间的KL差异作为KL损失,将每个用户的得分分布归一化为标准正态分布:

其中,Θ()是用户的预测分数的经验分布,KL(·||·)计算两个分布之间的KL差异。
3.3 模型训练
将KL损失与公式2相结合,可以得到完整的DPR模型来优化RSP,称为DPR-RSP:
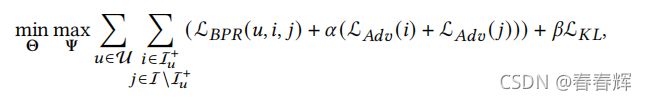
其中,是控制KL loss强度的权衡参数。同样地,我们也可以通过将kl损失与方程3相结合来优化REO,得到一个DPR-REO模型。请注意,虽然提出的DPR是以BPR作为模型基础构建的,但它实际上足够灵活,可以适应其他推荐算法,如更先进的神经网络。
然后,我们以小批量的方式训练模型。一般来说,在模型训练中,每个阶段都有两个阶段:首先更新MLP对抗中的权值以最大化分类目标,然后更新BPR以最小化成对排序损失、分类目标和KL损失。具体而言,按照[22]中提出的对抗性训练过程,在每个时期,首先通过整个数据集(以随机方式)更新MLP对抗,然后通过一个小批量更新BPR,这在经验上导致快速收敛。在实践中,通常首先对BPR模型进行几个周期的预训练,然后添加到对抗性训练部分。附录A介绍了详细的伪代码培训过程。
4 实验
在本节中,对所提出的模型w.r.t.,两个偏差指标和推荐质量进行了实证评估。回答了三个关键的研究问题:RQ1所提出的KL损失、对抗和完整的模型DPR对推荐的影响是什么?RQ2:从提高公平性和推荐质量保持的角度来看,所提出的DPR与其他最先进的去偏模型相比表现如何?超参数是如何影响DPR框架的?

KL损失的影响 KL损失是为了规范用户分数分布。因此,我们采用Jensen-Shannon (JS散度)来测量用户得分分布之间的偏差,其中较低的JS散度表明用户得分分布的归一化效果更好。作者比较了所有三个数据集上的BPR和BPR与KL损失,结果如表4所示,并计算了改进率(称为Δ)。我们可以观察到,随着kl损失的增加,用户得分分布之间的差异大大减少,这证明了kl损失的有效性。为了更好地显示kl损失的影响,图5可视化了ML1M每个用户在BPR有无KL的情况下的分数分布,其中每条曲线代表单个用户分数的累积分布函数(CDF)。右图中紧密集中的CDFs验证了所拟议的kl损失的有效性。
对抗的影响 DPR的对抗是提高不同组间的得分分布相似性。为了评估对抗式学习的有效性,比较了BPR和BPR对抗式学习在这两个指标上的表现(RSP为BPR w/adv,REO为BPR w/adv。)。结果如表5所示,其中前三行在非训练集中的所有用户项目对上计算(适合RSP设置),下面三行仅在测试集中的用户项目对上计算(适合REO设置)该表展示了所提出的对抗性学习在两种情况下提高分布相似性方面的非凡有效性。为了进一步验证这一结论,我们在图6中可视化了ML1M不同组的(|)分布((|,=1具有相同的模式),其中每组得分分布的概率分布函数(PDF)绘制为一条曲线。我们可以发现,BPRw/adv的PDFs彼此接近,而普通BPR的PDFs差异很大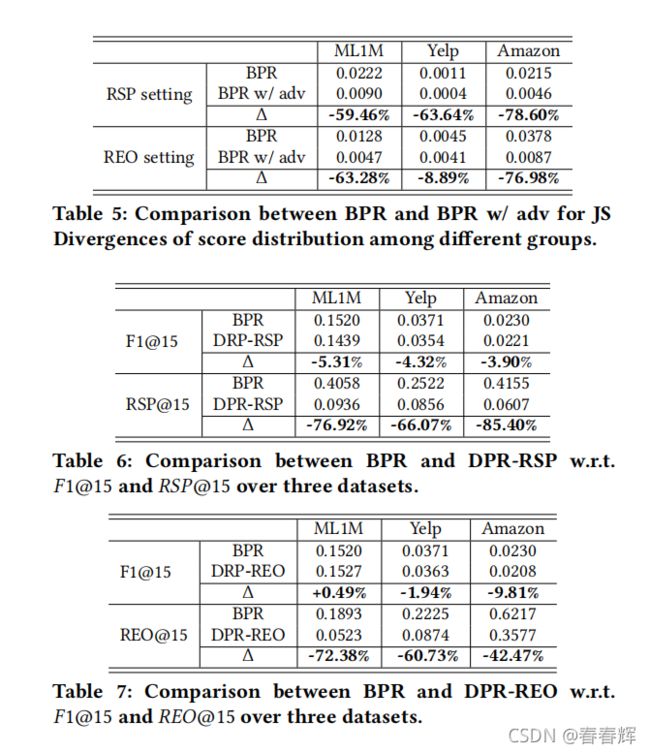
DPR的影响 应从推荐质量和推荐公平性的角度来评估完整的DPR的效果。首先研究了DPR-RSP的性能。表6列出了BPR和DPR-RSP对三个数据集的1@15和@15的结果,其中计算了它们的变化率。从表中我们有三个观察结果:(i)DPR-RSP大大提高了对BPR的公平性(平均降低@1576%);(ii)DPR-RSP有效地保持了推荐质量(平均仅使1@15下降4%);(iii)对于具有不同程度数据不平衡的不同数据集,DPR-RSP可以将不公平降低到类似的水平(DPR-RSP对三个数据集的@15都小于0.1)。
5 总结
本文基于众所周知的统计均等和机会相等的概念,首先提出了两个专门为个性化排序推荐任务设计的公平指标。然后,我们的经验表明,有影响力的贝叶斯个性化排序模型容易受到固有的数据不平衡的影响,并倾向于产生不公平的建议w.r.t.所提出的公平性指标。接下来,我们提出了一种新的公平感知个性化排序模型,结合对抗性学习,以增强所提出的公平指标。最后,大量的实验表明,所提出的模型比其他最先进的替代方案的有效性。