Python数据结构与算法-堆排序(NB组)
一、树的基础知识
1、树的定义
(1)树是一种数据结构,例如:目录结构
如下图:
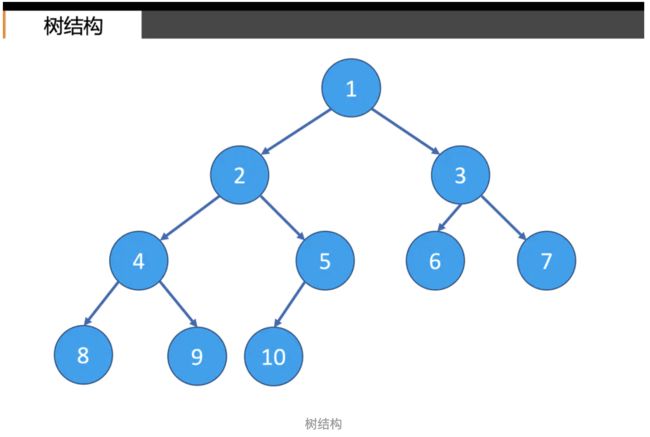
(2)树是一种可以递归定义的数据结构,定义如下:
树是由n个节点组成的集合:
a.如果n=0,那这是一棵空树;
b.如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树。
2、树的基本概念
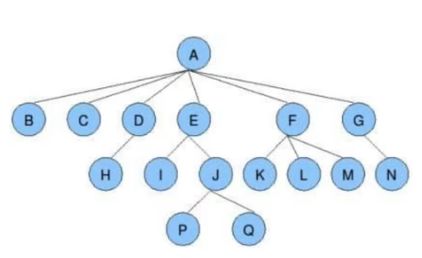
(1)根节点,树的最内侧,根部; 叶子节点:不能分叉的节点
如上图中,根节点为A,叶子节点有B、C。H、P、Q、K、L、M、N。
(2)树的深度(高度):树有多少层
如上图中,树的深度为4层,按最多的层数算。
(3)节点的度:该节点的分叉;树的度:树中最大的节点的度。即树里面最多分叉多少。
如上图中,节点E的度为2,节点F的度为3,节点A的度为6。树的度,是6。
(4)孩子节点/父节点:节点间的关系。
如上图中:I和J是E的孩子节点,E是I和J的父节点。
(5)子树:整个树的一部分。
如上图中,E节点下面的I和J,J节点下面的P和Q,单独拿出来就是子树。
二、二叉树基础知识
1、二叉树定义
定义:度不超过2的树,每个节点最多有两个孩子节点,两个孩子节点被区分为左孩子节点和有孩子节点。
下图为二叉树示例。
2、完全二叉树
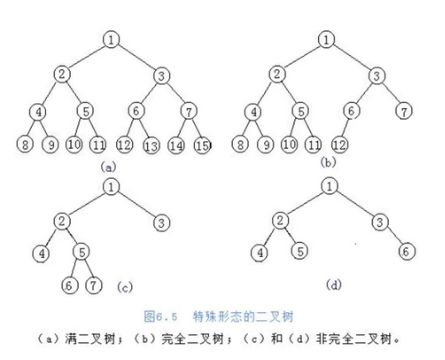
(1)满二叉树定义
一个二叉树,如果每一层的节点树都达到最大值,则这个二叉树就是满二叉树。
(2)完全二叉树定义
叶节点只能出现在最下层和次下层,并且最下层的节点都要集中在该层最左侧的若干位置的二叉树。(最下一层可以不满,但最下层的节点必须优先排在左边。)
(3)图示
3、二叉树的顺序存储方式
(1)存储方式的两个类型
a.链式存储方式——数据结构中再讲
b.顺序存储方式——堆用的顺序存储方式
(2)顺序存储方式原理
顺序存储方式,即是列表存储,将二叉树转换为列表。图示如下:
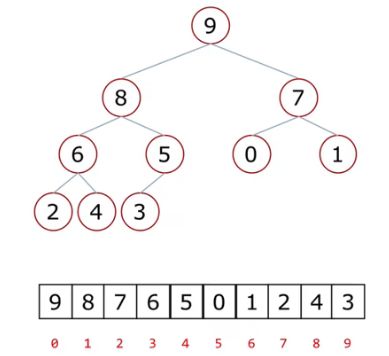
1)如上图,父节点和左孩子节点的编号下标(索引)有什么关系?
总结表格
值 |
下标 |
9—8 |
0—1 |
8—6 |
1—3 |
7—0 |
2—5 |
6—2 |
3—7 |
5—3 |
4—9 |
通过对比下标的数据规律,可得:当父节点下标为i时,左孩子节点的下标为2i+1。
2)如上图,父节点和右孩子节点的编号下标有什么关系?
总结表格:
值 |
下标 |
9—7 |
0—2 |
8—5 |
1—4 |
7—1 |
2—6 |
6—4 |
3—8 |
通过对比下标规律,可得:当父节点下标为i时,右孩子节点的下标为2i+2,即左孩子节点的右侧+1是右孩子节点。
3)如何通过孩子节点下标,推出父节点下标?
根据公式倒推,当孩子节点(无论是右孩子节点还是左孩子)为i时,父节点为(i-1)//2。
三、堆和堆的向下调整
1、堆的定义
堆是一种特殊的完全二叉树。堆分为大根堆和小根堆。
1)大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大。
2)小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小。
图示如下:

举例:
大根堆中,9比8和7大;小根堆中,1比2和6都小。
堆排序使用大根堆排序得到的是正序。
2、堆的向下调整性-大根堆为例
假设根节点的左右子树都是堆,但是根节点不满足堆的性质,可以通过一次向下调整来将其变成一个堆。
向下调整过程
1)初始的树结构如下图,根节点2无法成堆,但其左右子树均能成大根堆。

2)变更2的位置,先取出数值2,对比其孩子节点大小,9比7大,9移动到根节点的位置。

3)思考2 如果移动到空位上,是否能形成堆,8和5都比2大,显然不成立。因此需要移动空位下一层节点中更大的值到该空位中,8大于5,将8移动到空位中。
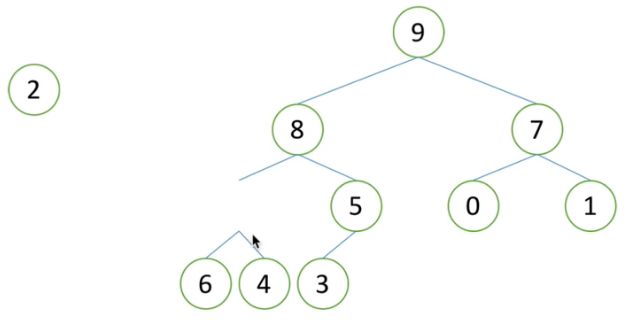
4)同理,思考2移动到现有空位上是否形成堆,显然,6和4都大于2,因此堆无法成立。同上步骤,选择6和4中较大的值移动到空位。

5)现有空位为叶子节点,已经是堆的最小节点,移动2到空位上,这时,原先的完全二叉树变为大根堆。
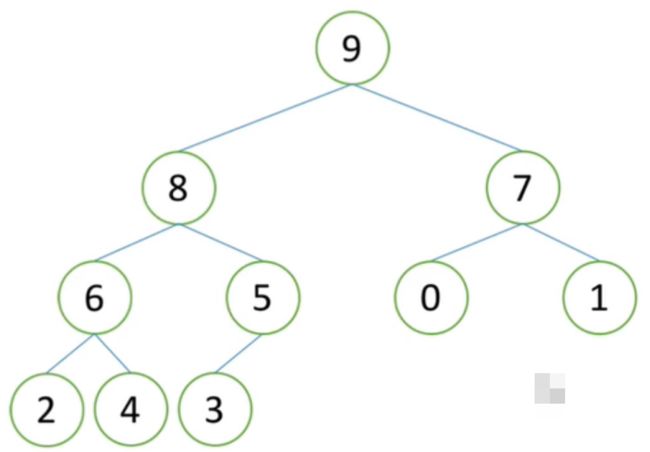
总结:以上整个移动过程,就是一次堆的向下调整。
四、堆排序的过程及工作原理
1、堆排序的过程
(1)建立堆;
(2)得到堆顶元素,为最大元素;
(3)去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序;
(4)堆顶元素为第二大元素;
(5)重复步骤3,直到堆变空。
2、堆排序工作原理(步骤2-5)
1)如下图所示,大根堆堆顶是列表中最大的数。取走9,得到列表中第一大的数。
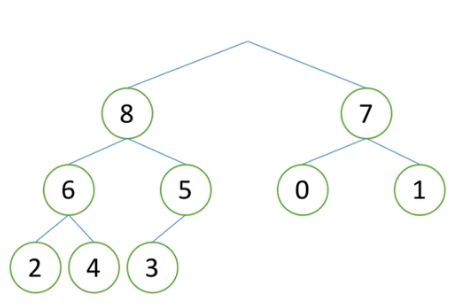
2)取堆中最后一个元素,这里是3,将3移动到堆顶,得到一个除了根节点外,子树都是堆的完全二叉树。
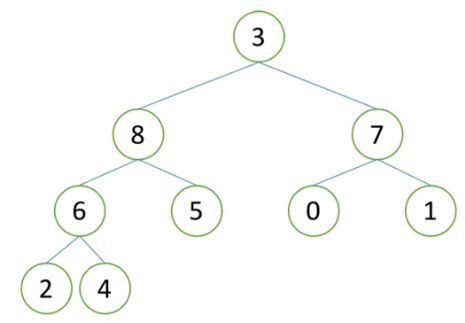
3)此时,可以通过一次向下调整(向下调整的过程见三->2中),可以得到如下图的大根堆。
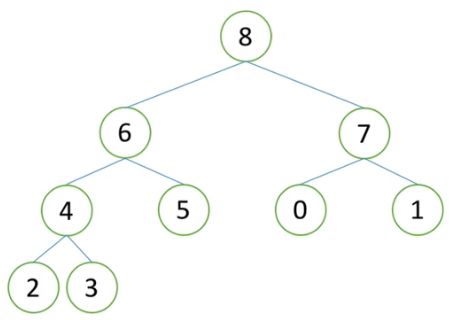
4)此时得到的新的大根堆堆顶值是该堆中的最大数值,是列表中的第二大数值,取走8。再重复2)和3)的过程,将堆的最后一个元素3移动到堆顶,再通过向下调整得到新的堆,此时的堆如下。堆顶数值为7。

5)不断重复2)和3)后,按大小顺序的到新堆的堆顶的值。
注意:根据堆写成列表的顺序,堆的最后一个元素是从右到左,从下到上的顺序。
例如:

写出列表是[6452],最后一个元素是2,最后第二个元素是5。
3、构建堆的过程
示例:
列表[6,8,1,9,3,0,7,2,4,5],画成二叉树如下图:
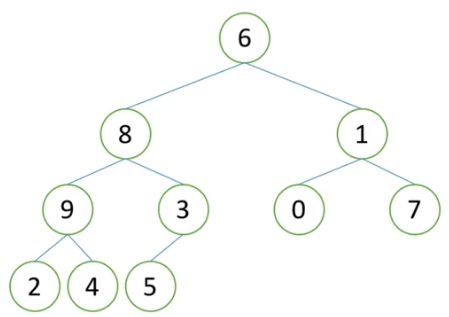
1)从最后一个非叶子节点开始,从小到大开始构建堆。如下图1中的红色方框内,首先调整该子树中元素的大小,使其父节点大于孩子节点。因此将5和3的位置交换,得到下图2。
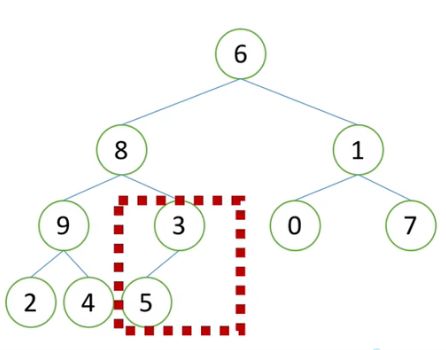
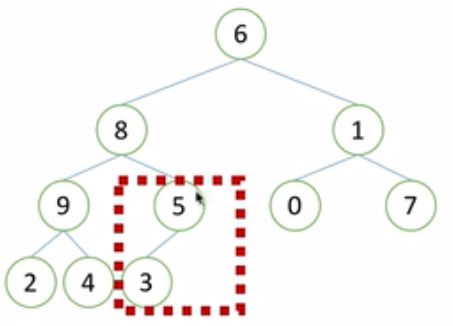
2)再看同一层的前一个子树,如下图,发现子树的父节点已经大于孩子节点,则不用做调整。
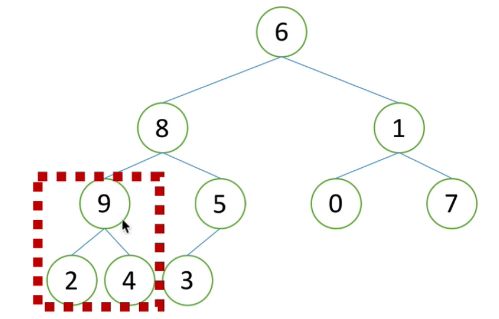
3)再往前调整更上一层的子树结构,如下图1,可以发现1小于7,所以需要调整父节点和孩子节点的值,调整后如下图2。
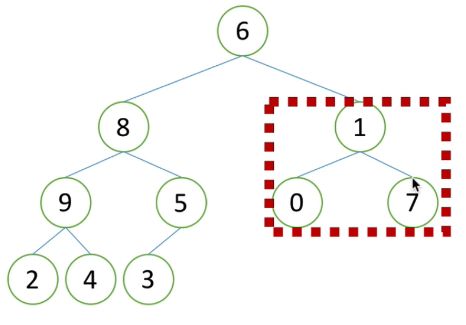

4)继续向左找到子树结构,如下图1,红框内所示,得到一个除根节点外,其余子树为堆的二叉树结构,此时可以使用堆的向下调整的,调整该子树为大根堆,如下图2。


5)再继续到上一层的二叉树结构,如下图1为整个二叉树结构。发现目前的结构同步骤4的一样,得到一个除根节点外,其余子树为堆的二叉树结构,因此使用堆的向下调整的,构建成了一个大根堆,如下图2。
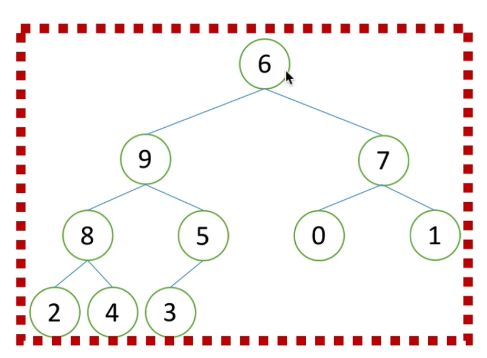

4、总结
堆排序,先按照步骤构建一个堆,再通过堆排序的原理,挨个选出堆顶的元素,得到最后的有序列表。
五、向下调整函数的代码实现
'''
description:
param {*} li:列表
param {*} low:堆的根节点位置
param {*} high:堆的最后一个元素的位置
return {*}
'''
def sift(li,low,high): # 堆排序的向下调整
i = low # i是最开始指向堆顶位置,后面指向父节点
j = 2 * i + 1 # j是i的左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有元素,即i的左孩子索引不超过堆的最后一个元素
# 结束该if,得到j指向两个孩子节点中值更大的节点。
if j + 1 <= high and li[j] < li[j+1]: # 右孩子比左孩子大,且右孩子存在
j = j + 1 # j指向右孩子
if li[j] > tmp: # 当前孩子节点的元素比取下来的值大
li[i] = li[j] # 将j指向的元素移到空位上,i位置因为取走了数,是空的状态。
i = j # 往下看一层,得到新的i
j = 2 * i + 1 #得到新的j
else: # tmp大于li[j],将tmp放在i的空位上
li[i] = tmp #将tmp放在某一层的父节点位置
break # 结束while循环
else: # j > high时,i指向的是叶子节点,其没有孩子节点,这是tmp直接放到i所在空位上
li[i] = tmp六、堆排序的代码实现
1、构造堆代码解析
(1)如何求解最后一个非叶子节点的下标(索引)?
当孩子节点的下标为i时,父节点的下标为(i-1)//2。构建堆是从下往上(农村包围城市),所以从最后一个叶子节点开始倒推,其下标为列表长度-1(下标是从0开始的)。则i = n-1(n是列表长度),该叶子节点的父节点下标为:((n-1)-1)//2 = (n-2)//2。
(2)如何指定“农村包围城市”过程中的每一个子树的high指针的指向?
1)high的作用是确保j指针不越界,即不超过堆的最后一个元素。
2)如下图所示,红框内的二叉树对应的high位置应该是7的位置,但是7位置的索引求解很复杂,不一定是2i+1或2i+2,因为二叉树结构不一定只有两层,一般是多层结构。
3)指定high一直都为整个二叉树的最后一个元素的位置,例如下图中,如果i指向7的时候,对应的j越界,位置在7的下层的红圈,红圈的位置不可能在3的前面,依旧是大于最后一个元素的,因此j > high,也可以确保j不越界。
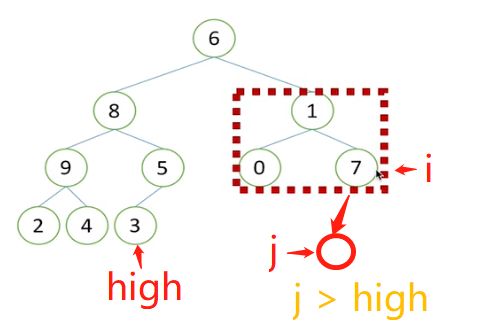
(3)构建完堆后,挨个出数时,将取出的数放到该列表的末尾,不重新建一个列表,可以减少空间复杂度,因此每次堆的取数就是和堆的最后一个元素交换位置,li[i],li[0]=li[0],li[i],再进行堆的向下调整。
2、代码实现
#堆排序
'''
description:
param {*} li:列表
param {*} low:堆的根节点位置
param {*} high:堆的最后一个元素的位置
return {*}
'''
def sift(li,low,high): # 堆排序的向下调整
i = low # i是最开始指向堆顶位置,后面指向父节点
j = 2 * i + 1 # j是i的左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有元素,即i的左孩子索引不超过堆的最后一个元素
# 结束该if,得到j指向两个孩子节点中值更大的节点。
if j + 1 <= high and li[j] < li[j+1]: # 右孩子比左孩子大,且右孩子存在
j = j + 1 # j指向右孩子
if li[j] > tmp: # 当前孩子节点的元素比取下来的值大
li[i] = li[j] # 将j指向的元素移到空位上,i位置因为取走了数,是空的状态。
i = j # 往下看一层,得到新的i
j = 2 * i + 1 #得到新的j
else: # tmp大于li[j],将tmp放在i的空位上
li[i] = tmp #将tmp放在某一层的父节点位置
break # 结束while循环
else: # j > high时,i指向的是叶子节点,其没有孩子节点,这是tmp直接放到i所在空位上
li[i] = tmp
# 堆排序主体
def heap_sort(li): # 堆排序,参数为列表
n = len(li) # 列表长度
for i in range((n-2)//2, -1, -1): # 从后往前,堆顶的下标是0,range()函数包前不包后,需写到-1,-1为步长,倒序。
# i表示建堆时,需要调整的根节点
#开始做堆的向下调整
sift(li,i,n-1) #i为堆顶low,n-1为树的最后一个元素high,不用寻找每个子树的最后一个元素,也可确保j不越界
#完成上面的for循环,建堆完成
#下面开始挨个出数
for i in range(n-1, 0, -1): #range()用-1做倒序,列表的最后剩下的数不需要排序,不需要取到索引0
# i指向当前堆的最后一个元素,不断往前推进。
#互换堆顶元堆的最后一个元素,堆顶元素填到列表后面
li[i], li[0] = li[0], li[i] # 无序区为除了根节点其他子树为堆的二叉树
sift(li, 0, i-1) # i-1是新的high,向下调节无序区,成为堆;
print(li)
li = [4,6,2,8,7,5,0,9]
heap_sort(li)输出结果:
[0, 2, 4, 5, 6, 7, 8, 9]说明:
第36行代码, for i in range(n-1, 0, -1): 与课程中 for i in range(n-1, -1, -1):做了修改。
其中,课程中的range(n-1, -1, -1),做了n次循环,对堆的最后一个元素也做了一遍向下调整的过程。而实际上这一步可以省略,堆剩下的最后一个元素时,有序列表直接就生成了,无需再对最后一个元素做调整,挨个取数的循环,只需要n-1次即可。
七、时间复杂度
堆排序的时间复杂度为 。
。
虽然堆排序的时间复杂度和快速排序的时间复杂度一样,但是实际运行中,快速排序的速度比堆排序要快一些。
解释分析:
(1)向下调整函数sift()为每一层选择一个数,不是左孩子节点往下找,就是右孩子节点往下,是按照树的深度调整,规模是逐半减少的,也可以通过while循环对比j的值,j = 2i+1,成倍数增加,因此可得其时间复杂度为O(logn)。
(2)堆排序主体代码各自独立的两个for循环,每个for循环的时间复杂度为O(n),且每个for循环内部一个sift()函数,即n * logn = nlogn。因此,每个for循环家sift函数的时间复杂度为O(nlogn)。两个独立的for循环时间复杂度相加,2nlogn。则简化为O(nlogn)。
八、堆的内置模块
python内置的堆相关模块:heapq ,其中q代表的是Queue(队列)。
1、常用的函数:
(1) heapify(li): 创建小根堆(该模块只能建立小根堆)
(2)haeppop(heap):对外依次去除向下调整后的堆的堆顶值。
(3)heappush(heap,item): 将item压入堆中(形成小根堆)
2、函数代码示例
# 堆排序的内置模块
import heapq
import random
li = list(range(20)) #生成随机列表
random.shuffle(li) #打乱顺序
#创建小根堆
heapq.heapify(li)
print(li)
#实现堆排序
heap = []
for i in range(len(li)):
x = heapq.heappop(li) # 每次取出小根堆对顶的元素
heap.append(x)
print(heap)
#创建小根堆方法2
lis = list(range(10))
random.shuffle(lis)
heap2 = []
for i in lis:
heapq.heappush(heap2, i) #将元素加入堆中
print(heap2)输出结果:
[0, 1, 5, 2, 3, 9, 6, 13, 4, 11, 17, 10, 14, 12, 16, 19, 18, 8, 7, 15]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
[0, 2, 1, 5, 3, 8, 4, 7, 9, 6]九、堆排序—topk问题
1、topk解决思路
(1)问题
现在有n个数,设计算法得到前k大的数。(k 排序后切片 O(nlogn) ——使用的O(nlogn)的NB组排序,再切片。 排序LowB三人组 O(kn) ——从大到小排序,只用排k趟。 堆排序思路 O(nlogk)——该办法的时间复杂度最低,效率最高,空间复杂度分析详见(5)。 1)去列表前k个元素建立一个小根堆。堆顶就是目前第k大的数(堆顶是堆最小的数,但是取出的堆一共就k个数,最小的数也就是这个堆的第k大数)。 2)依次向后遍历原列表(索引k+1开始的列表),对于列表的元素,如果小于堆顶,则忽略该元素:如果大于堆顶,则将堆顶更换为该元素,并且对堆进行一次向下调整。 1)如下图为一个需要取出前5大数的列表。 2)取出列表的前5个数,并创建小根堆,如下图所示。这时堆顶元素1是这个堆中最小的数,也是这个小根堆中第五大的数。 3)在剩余的列表中依次和堆顶的数做对比,0明显小于1,不变更0和1的位置,并删除0。 4)继续在剩下的列表的第一个数与小根堆堆顶元素对比,7大于1,那么将7替换1的位置,元素1删除,并做一次向下调整,得到小根堆,如下图1,和图2。 5)不断进行同步骤3和步骤4相同的操作,小于堆顶的数删除,大于堆顶的数替换,直到列表为空,此时得到最后的小根堆,小根堆中的数据就是前k大的数,如下图。 6)最后将小根堆的数据依次根据堆排序得到有序列表。 第一步,创建一个k个元素的堆排序,时间复杂度为O(klogk)。每次向下调整只需要调整k个元素,因此向下调整的时间复杂度为O(logk)。最后实现一次堆排序,时间复杂度为O(2klogk)。在不忽略小于堆顶数的前提下,一共向下调整(n-k)logk次,总的时间复杂度为:klogk + 2klogk + (n-k)logk = (k+2k+n-k)logk=(n+2k)logk,因此时间复杂度简化为O(nlogk)。 1)排序中的Low B三人组以及快速排序和堆排序都是比较排序,只要改变大小值对比符号,就能更改升序或降序排序。 2)第27行代码,学习视频中是错误的,range()是包前不包后的,为了遍历整个剩余列表,剩余列表的最后一个数的索引是len(li)-1,因此遍历范围为range(k, len(li))。(2)解题思路
(3)堆排序解题思路
(4)堆排序解题示例

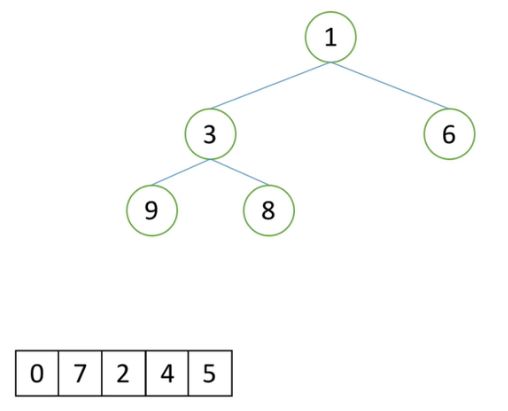

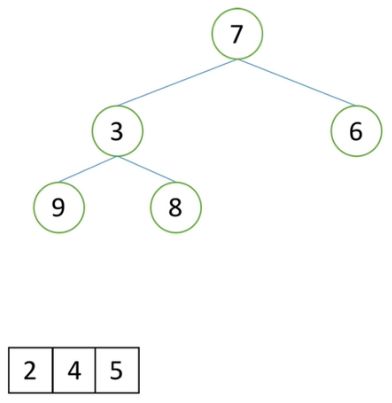
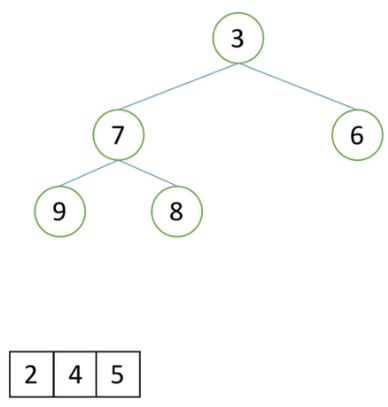
(5)空间复杂度解析
2、topk问题代码实现
(1)输入代码
#小根堆的向下调整
def sift(li,low,high): # 堆排序的向下调整
i = low # i是最开始指向堆顶位置,后面指向父节点
j = 2 * i + 1 # j是i的左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有元素,即i的左孩子索引不超过堆的最后一个元素
# 结束该if,得到j指向两个孩子节点中值更小的节点。
if j + 1 <= high and li[j] > li[j+1]: # 右孩子比左孩子小,且右孩子存在
j = j + 1 # j指向右孩子
if li[j] < tmp: # 当前孩子节点的元素比取下来的值小
li[i] = li[j] # 将j指向的元素移到空位上,i位置因为取走了数,是空的状态。
i = j # 往下看一层,得到新的i
j = 2 * i + 1 #得到新的j
else: # tmp小于li[j],将tmp放在i的空位上
li[i] = tmp #将tmp放在某一层的父节点位置
break # 结束while循环
else: # j > high时,i指向的是叶子节点,其没有孩子节点,这是tmp直接放到i所在空位上
li[i] = tmp
def topk(li, k): # topk问题
heap = li[0:k] # 切片操作,包前不包后,实际取的索引0-(k-1)的k个数
# 1、建小根堆
for i in range((k-2)//2, -1, -1): # 从后往前,堆顶的下标是0,倒序。
sift(heap, i, k-1) # 向下调整
# 2、遍历
# 剩余从第k+1个数到最后一个数,即对应数的索引为从k到len(li)-1,range包前不包后,要写到len(li)
for i in range(k, len(li)):
if li[i] > heap[0]: # 列表值大于堆顶值
heap[0] = li[i] # 覆盖原堆顶值
sift(heap, 0, k-1)
#3、挨个出数-堆排序
for i in range(k-1, 0, -1): # i指向当前堆的最后一个元素
heap[i], heap[0] = heap[0], heap[i] #不断用最后一个数替换堆顶
sift(heap, 0, i-1)
return heap
lis = [5,3,4,7,2,8,9]
maxk = topk(lis,3)
print(maxk)(2)输出结果
[9, 8, 7](3)补充说明