spark-core 源码
1. getPartitions
就是计算一下你读取的文件一共将分成多少个切片(或者说分区) 首先切片大小肯定小于物理文件块的大小
用的是 InputFormat接口下的 FileInputFormat
2.compute
这个函数是指明 我已经分区好了,未来我这个计算要向分区所在的哪个地方移动去,也就是计算向数据移动 我要找文件所在物理块号
这个函数其实返回的就是一个迭代器,里面有hasNext()和getNext()方法
1. cartesian笛卡尔积
笛卡尔积操作 cartesian函数
他不需要shuffle 因为他需要的是另一个rdd全部的数据,不需要区分具体每条数据属于哪个分区,直接用IO的方式拉取所有数据,用两层for循环进行笛卡尔积操作
2. cogroup
就是两两结合 但是他不能用笛卡尔积那种全量IO 因为他的组合是KV键值对组合 只有对相同的K他才要,如果全部IO过来好多东西可能用不到,浪费IO
它是先用shuffle,将相同的key shuffle过来 然后进行组合
3. 聚合函数

由于avg的计算设计两个job 优化为只用一个job的可以用reduceByKey的底层 combineByKey

4. 面向分区操作

如果选择将所有分区每一条记录,都一条一条拿过来,没拿一条进行一次数据库连接等操作,浪费时间与资源。
选择一次性对全部分区的数据进行操作,针对每个分区开创一个数据库连接。
上面的程序也有弊端,因为spark本质是一个pipeline 迭代器嵌套的模式,在内存里面跑的是迭代器而不是真实的数据 ,所以只会一条一条数据放入内存,内存不存在溢出的现象。
而上面的程序用了ListBuffer 它将每次数据又重新放入内存保存起来,这样就直接导致内存溢出。
改进:
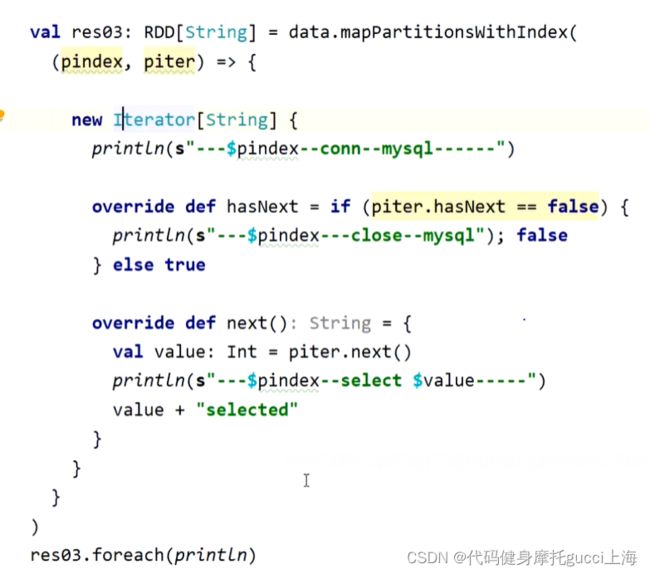
利用迭代器的方式 就可以直接不存储数据 每一条直接输出select结果
而上面的方式是先统一查询 直到最后才一口气输出结果
5. repaitition函数可以改变RDD分区 主要是内部调coalesce触发shuffle调整分区数量
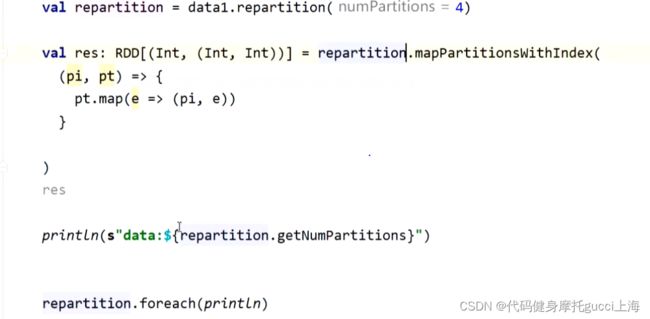
调coalesce时,如果shuffle为false 即关闭shuffle,那么不能将分区数量由小变大,因为变大分区需要调取数据,调取数据的方式只有全量IO和shuffle,现在shuffle关闭了,分区还变大,就没法给对应分区调取适量数据
但是如果shuffle关闭 可以将分区数量从大往小变。 因为 分区减小后,可以将之前某一分区的全量数据 通过IO方式合并给另一个分区,这种方式不需要计算各个数据需要向哪里移动, 类似于归并操作。在这种方式下,需要进行计算的机器,只有你规定的分区数的机器数。

分组取TOPN

这段代码里面groupByKey()可能会发生溢出,这个算子尽量少用,因为如果一个key里面的value数量太多,全部分组会发生内存溢出
中间他用了后一个HashMap临时保存东西来进行去重,同样可能发生溢出操作
方法二: 利用shuffle去重 即reduceByKey(但还是有groupby 可能溢出)

方法三: 为了避免内存溢出 可以重写groupBy内部的combineByKey
//第五代
//分布式计算的核心思想:调优天下无敌:combineByKey
//分布式是并行的,离线批量计算有个特征就是后续步骤(stage)依赖其一步骤(stage)
//如果前一步骤(stage)能够加上正确的combineByKey
//我们自定的combineByKey的函数,是尽量压缩内存中的数据
val kv: RDD[((Int, Int), (Int, Int))] = data.map(t4=>((t4._1,t4._2),(t4._3,t4._4)))
val res: RDD[((Int, Int), Array[(Int, Int)])] = kv.combineByKey(
//第一条记录怎么放:
(v1: (Int, Int)) => {
Array(v1, (0, 0), (0, 0))
},
//第二条,以及后续的怎么放:
(oldv: Array[(Int, Int)], newv: (Int, Int)) => {
//去重,排序
var flg = 0 // 0,1,2 新进来的元素特征: 日 a)相同 1)温度大 2)温度小 日 b)不同
for (i <- 0 until oldv.length) {
if (oldv(i)._1 == newv._1) {
if (oldv(i)._2 < newv._2) {
flg = 1
oldv(i) = newv
} else {
flg = 2
}
}
}
if (flg == 0) {
oldv(oldv.length - 1) = newv
}
// oldv.sorted
scala.util.Sorting.quickSort(oldv)
oldv
},
(v1: Array[(Int, Int)], v2: Array[(Int, Int)]) => {
//关注去重
val union: Array[(Int, Int)] = v1.union(v2)
union.sorted
}
)
res.map(x=>(x._1,x._2.toList)).foreach(println)优化是核心,常用combineByKey优化 因为他会压缩内存当中的东西 每次计算一条一条进 但是只用了三个格子存储数据 来回比较来回替换
除此之外 如果频繁的创建新的对象 如oldv.sorted会创建一个新的Array对象 旧的他会导致虚拟机频繁gc
所以选用原地排序的scala.util.Sorting.quickSort(oldv)
union同理
调优
调优的关键就是1. 减少IO 2. 减少stage 尤其哪些有ByKey的算子 肯定会用shuffle 一用shuffle就会导致拉取数据增加复杂度

像上图的job 用了map之后 groupByKey还会再拉取一次数据 造成shuffle 浪费了时间与IO成本
在这个场景下是没有必要的 (场景是wordCount)
因为你map这边会进行一个比如哈希取模的运算,比如你前面第一个map会造成“hello”去1号机器,在后面的第二个map里面 他的key还是hello 改变的只是value内容,这个时候你用map的话 还会让“hello”取模一次,并让他未来的groupByKey再次调动shuffle,因为你可能又导致他会去一个新的机器里面。这一次的shuffle是没有必要的
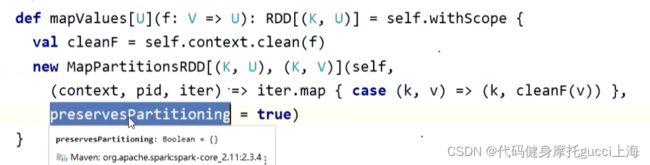
所以应该用mapValues这个算子 他和map的不同就是下面那个boolean参数是true,他就会阻断shuffle行为 默认丢弃分区器