Diverse Image Style Transfer via Invertible Cross-Space Mapping
可逆的跨空间映射实现多样化的图像风格传输
摘要
-
图像风格迁移可以将艺术风格迁移到任意照片上,以创建新颖的艺术图像。尽管风格迁移本质上是一个不适定问题,但现有方法通常假设某种唯一结果,而无法捕获潜在可能的完整分布。
-
本文提出一个多样化的图像风格迁移(DIST)方案,该方案通过执行可逆的跨空间映射来实现多样性。具体来说,由三个分支组成:解耦分支、逆向分支和风格化分支。
-
解耦分支可以分解内容空间和风格空间;逆映射分支则可以完成输入噪声向量与艺术图像风格空间之间的可逆映射;风格化分支渲染风格化输入的内容图像。
-
其中,解耦分支将艺术品分解为内容空间和风格空间;逆分支鼓励输入噪声向量的潜在空间与生成的艺术图像的风格空间之间的可逆映射;风格化分支以艺术家的风格呈现输入内容图像。有了这三个分支,本文的方法能够合成出显著不同的风格化图像而不损失质量。
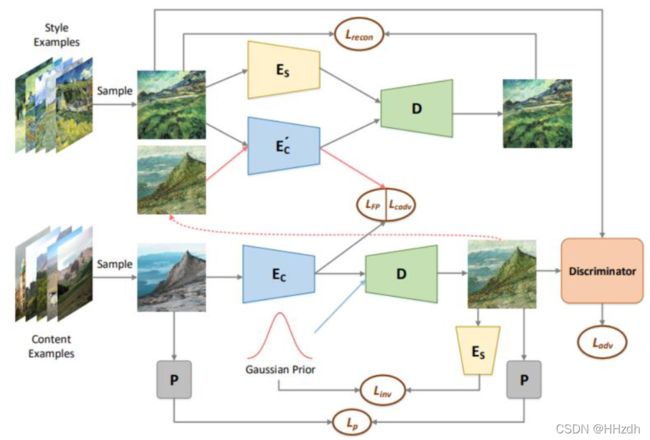
 图1 DIST生成的风格化示例。第一列显示内容图像。其他四列则是根据Paul Cezanne的风格呈现出不同的风格化结果。
图1 DIST生成的风格化示例。第一列显示内容图像。其他四列则是根据Paul Cezanne的风格呈现出不同的风格化结果。
Abstract
图像风格转换是将艺术作品的风格转换到任意的照片上,创造出新颖的艺术形象。尽管风格转换本质上是一个不适定的问题,现有的方法通常假设一个确定性的解决方案,因此不能捕获可能输出的全部分布。为了解决这个限制,本文提出一个多样化的图像风格迁移(DIST)方案,该方案通过执行可逆的跨空间映射来实现多样性。具体来说,由三个分支组成:解耦分支、逆向分支和风格化分支。解耦分支可以分解内容空间和风格空间;逆映射分支则可以完成输入噪声向量与艺术图像风格空间之间的可逆映射;风格化分支渲染风格化输入的内容图像。其中,解耦分支将艺术品分解为内容空间和风格空间;逆分支鼓励输入噪声向量的潜在空间与生成的艺术图像的风格空间之间的可逆映射;风格化分支以艺术家的风格呈现输入内容图像。有了这三个分支,本文的方法能够合成出显著不同的风格化图像而不损失质量。
1. Introduction
一件精美的艺术品可能需要一个勤奋的艺术家几天甚至几个月的时间来创作,这是劳动密集型和时间消耗。受此启发,一系列最近的研究方法研究了用艺术家的风格重新绘制现有照片的问题,无论是使用单一的艺术作品还是收藏的艺术作品。这些方法被称为风格转换。有了风格转换技术,任何人都可以创造艺术图像。
如何表现图像的内容和风格是风格转换的关键挑战。最近,Gatys et al. [7] 的开创性工作首先提出使用预训练的深度卷积神经网络 (Deep Convolutional Neural Networks, DCNNs) 从图像中提取内容和风格特征。通过对任意图像的内容和风格进行分离和重组,可以创作出新颖的艺术品。这项工作显示了 CNN在风格转换方面的巨大潜力,并引发了人们对这一领域的兴趣激增。在此基础上,又提出了一系列后续的方法,以期在效率 [13,21,34]、质量 [20,35,40,43,39,4] 和泛化[6,5,10,24,30,27,22] 等多个方面取得更好的性能。然而,作为另一个重要方面,多样性受到的关注相对较少。
俗话说,“一千个人眼中有一千个哈姆雷特”。同样,不同的人对一件艺术品的风格也有不同的理解和解读。一个形象的艺术风格没有统一的、定量的定义。因此,风格化的结果应该是多样化的,而不是独一无二的,这样才能满足不同人的偏好。换句话说,风格转移是一个未确定的问题,可以找到大量的解决方案。不幸的是,现有的样式转换方法通常采用确定性的解决方案。因此,它们无法捕获可能输出的全部分布。
处理风格传递多样性的一种直接方法是将随机噪声向量与内容图像一起作为输入,即利用输入噪声向量的可变性来产生不同的风格化结果。然而,网络往往更关注高维和结构化的内容图像,而忽略了噪声向量,导致了确定性输出。为了保证潜在空间中的可变性能够传递到图像空间中,Ulyanov等人[35]通过扩大生成图像在像素空间中的距离来增强图像之间的差异性。同样,Li et al.[23]引入了多样性损失,在小批量中惩罚不同样本的特征相似性。虽然这些方法可以在一定程度上实现多样性,但也存在明显的局限性。首先,强制放大输出之间的距离会导致结果偏离局部最优,导致图像质量下降。其次,为了避免在生成的图像中引入过多的伪影,一般将多样性损失的权重设置为一个较小的值。因此,风格化结果的多样性相对有限。第三,多样性不仅仅是生成图像之间的像素距离或特征距离,它包含更丰富、更复杂的内涵。最近,Wang等人的[37]在保持原始风格信息不变的情况下,利用正交噪声矩阵对图像特征映射进行扰动,从而获得了更好的分集。然而,这种方法容易产生失真的结果,提供不理想的视觉质量。因此,不同风格的转移问题仍然是一个开放性的挑战。
本文提出了一个多样化的图像风格传输 (DIST) 框架,通过强制一个可逆的跨空间映射来实现显著的多样性而不损失质量。具体来说,框架将随机噪声向量和照片作为输入,前者负责风格变化,后者决定主要内容。但是,通过以上分析,可以了解到噪声向量在网络中很容易被忽略。本文提出的 DIST 框架通过三个分支来解决这个问题:解纠缠分支、逆分支和风格化分支。
- 解构分支将艺术品分解为内容空间和风格空间。
- 逆分支鼓励输入噪声向量的潜在空间与生成的艺术图像的风格空间之间的可逆映射,其灵感来自 [32]。但与 [32] 不同的是,由于输入噪声矢量主要影响生成图像的风格,所以本文将风格信息而不是生成的整个图像转换为输入噪声矢量。
- 风格化分支以艺术家的风格呈现输入内容图像。
通过这三个分支,DIST 能够合成出明显不同的风格化图像而不降低图像质量,如图 1 所示。
3. Approach
受[29,17,18,33]的启发,我们学习艺术风格不是从单一的艺术品,而是从相关的艺术品集合。形式上,我们的任务可以这样描述:给定一组照片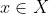 和一组艺术品
和一组艺术品![]() (X和Y的内容可以完全不同),我们的目标是学习具有显著多样性的风格转换
(X和Y的内容可以完全不同),我们的目标是学习具有显著多样性的风格转换![]() 。为了实现这一目标,我们提出了一个由三个分支组成的DIST框架:解纠缠分支、逆分支和风格化分支。在本节中,我们将详细介绍这三个分支。
。为了实现这一目标,我们提出了一个由三个分支组成的DIST框架:解纠缠分支、逆分支和风格化分支。在本节中,我们将详细介绍这三个分支。
3.1. Stylization Branch
风格化分支的目标是用![]() 的风格重新绘制 。为此,本文使用判别器器 D 对 G 进行训练,使 G 能够近似 Y 的分布: G 试图生成与 Y 中的图像相似的图像,而 D 试图将程式化的图像与真实的图像区分开来。对这两个网络的联合训练将产生一个能够产生所需程式化的生成器。这个过程可以表述如下 (注意对于 G,本文采用编码器
的风格重新绘制 。为此,本文使用判别器器 D 对 G 进行训练,使 G 能够近似 Y 的分布: G 试图生成与 Y 中的图像相似的图像,而 D 试图将程式化的图像与真实的图像区分开来。对这两个网络的联合训练将产生一个能够产生所需程式化的生成器。这个过程可以表述如下 (注意对于 G,本文采用编码器  和解码器 D 组成的编解码器体系结构),如公式(1)。
和解码器 D 组成的编解码器体系结构),如公式(1)。
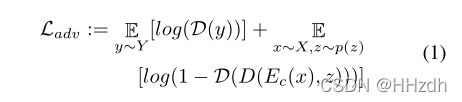
其中![]() 是一个随机噪声向量,p(z) 是标准正态分布
是一个随机噪声向量,p(z) 是标准正态分布![]() 。本文利用它的可变性来鼓励生成图像的多样性。
。本文利用它的可变性来鼓励生成图像的多样性。
仅使用上述对抗性损失无法保留生成图像中 x 的内容信息,不满足风格转移的要求。最简单的解决方案是利用内容图像和风格化图像![]() 之间的像素损失。然而,这种损失太过严格,损害了风格化图像的质量。因此,本文软化约束:本文不是直接计算原始图像之间的距离,而是首先将它们输入到平均池化层 P 中,然后计算它们之间的距离。本文将这种内容结构损失表示为公式(2)。
之间的像素损失。然而,这种损失太过严格,损害了风格化图像的质量。因此,本文软化约束:本文不是直接计算原始图像之间的距离,而是首先将它们输入到平均池化层 P 中,然后计算它们之间的距离。本文将这种内容结构损失表示为公式(2)。
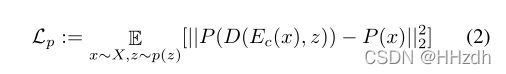
与要求内容图像和风格化图像完全相同的像素损失相比,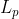 以更粗粒度的方式衡量它们的差异,只要求它们在一般内容结构上相似,更符合风格转移的目标。
以更粗粒度的方式衡量它们的差异,只要求它们在一般内容结构上相似,更符合风格转移的目标。
3.2. Disentanglement Branch
[32] 通过加强输入噪声向量与生成图像之间的双射映射,缓解了 GAN 中的模式坍缩问题。与 [32] 只使用噪声向量作为输入不同,本文的模型将噪声向量与内容图像一起作为输入,前者负责风格变化,后者决定主要内容。因此,在反过程中,本文不像 [32] 那样将整个生成的图像反到输入噪声向量,而是将风格化图像的样式信息反到输入噪声向量 (详见第3.3节)。具体来说,本文利用f风格编码器从风格化图像中提取风格信息,并加强风格编码器输出与输入噪声向量之间的一致性。现在的主要问题是如何获得这样的风格编码器。本文通过解耦分支来解决这个问题。
首先,解耦分支采用编码器![]() ,以风格化图像
,以风格化图像 ![]() 作为输入。鉴于内容图像和风格化图像共享相同的内容和风格有很大的不同,如果鼓励的输出 (其输入内容图像) 和
作为输入。鉴于内容图像和风格化图像共享相同的内容和风格有很大的不同,如果鼓励的输出 (其输入内容图像) 和![]() (其输入是程式化的形象)之间的相似性, 和
(其输入是程式化的形象)之间的相似性, 和 ![]() 应提取共享内容信息和忽视具体样式信息。注意, 和
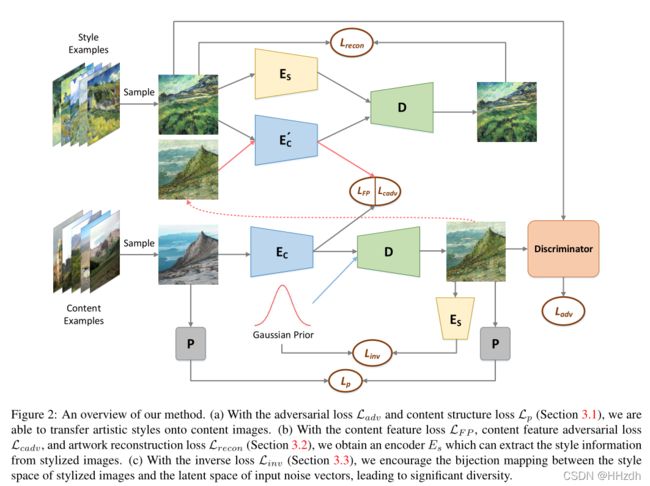
应提取共享内容信息和忽视具体样式信息。注意, 和![]() 是两个独立的网络,不共享权值。这是因为在提取照片内容和艺术品内容时存在一些差异。本文将相应的内容特征损失定义为公式(3)。
是两个独立的网络,不共享权值。这是因为在提取照片内容和艺术品内容时存在一些差异。本文将相应的内容特征损失定义为公式(3)。
然而,![]() 可能鼓励和
可能鼓励和![]() 输出特征图中每个元素的值是很小的(也就是说,
输出特征图中每个元素的值是很小的(也就是说,![]() )。在这种情况下,尽管如果P是最小化,
)。在这种情况下,尽管如果P是最小化,![]() 之间的相似性和
之间的相似性和![]() 不增加。为了缓解这个问题,我们使用了一个特征鉴别器
不增加。为了缓解这个问题,我们使用了一个特征鉴别器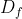 ,并引入了一个内容特征对抗损失。
,并引入了一个内容特征对抗损失。
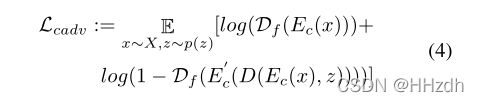
![]() 测量的是分布偏差,与
测量的是分布偏差,与 ![]() 相比,
相比,![]() 对其输入值的敏感性较小。此外,
对其输入值的敏感性较小。此外,![]() 与
与 ![]() 一起可以促进两个维度的相似性,进一步提高性能。
一起可以促进两个维度的相似性,进一步提高性能。
然后解耦分支采用另一个编码器 ,再加上内容编码器
,再加上内容编码器 ![]() 和解码器 D 来重构艺术图像。由于
和解码器 D 来重构艺术图像。由于 ![]() 被约束提取内容信息,必须提取风格信息来重建艺术形象。因此,本文得到所需的样式编码器 。本文将重建损失定义为公式(5)。
被约束提取内容信息,必须提取风格信息来重建艺术形象。因此,本文得到所需的样式编码器 。本文将重建损失定义为公式(5)。
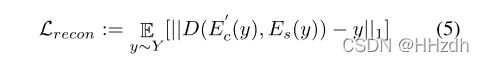
3.3. Inverse Branch
借助风格编码器 ,可以进入艺术形象的风格空间。为了实现分集,逆分支利用逆损失,强制潜在空间和风格空间之间的一对一映射。逆损失确保样式信息生成的图像 ![]() 可以倒到相应的噪声向量 z,这意味着
可以倒到相应的噪声向量 z,这意味着 ![]() 保留 z 的影响和变化。通过这种方式,本文可以得到不同的格式化结果由标准正态分布 N(0, 1) 随机抽样的不同的 z。
保留 z 的影响和变化。通过这种方式,本文可以得到不同的格式化结果由标准正态分布 N(0, 1) 随机抽样的不同的 z。
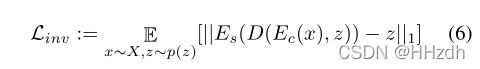
3.4. Final Objective and Network Architectures