全景天窗式科普数据仓库
数据仓库是一个面向主题的、集成的、随时间变化但信息本身相对稳定的数据集合,用于支持管理决策过程。其本质就是完成从面向业务过程数据的组织管理到面向业务分析数据的组织和管理的转变过程,也是商业智能BI中数据仓库的主要作用。

数据仓库 - 派可数据商业智能BI可视化分析平台
数据仓库就像企业的总的大仓库,能够存储不同来源、不同格式的数据,并且可以通过ETL和数据模型,对数据进行高质量的筛选,分级分类进行存储。具有很强的稳定性,不会频繁的进行增删改等操作,能够反映历史变化。
今天我们从数据的源头开始说起,数据的源头是数据采集和上报。
(一)数据采集
采集内容
数据采集一般需要涵盖4W(When、Where、Who、What)四大要素,像作文一样分别从时间、地点、人物、事件对用户的行为予以描述。
When
操作时间。有些数据上报并不是在采集后马上进行的,而是累计采集N条后打包上报;有些参数的获取需要前后台彼此交互,所以时间的采集可以细分为动作发生的时间、采集时间、前后台交互完成时间、上报时间等,根据各业务需求和复杂程度决定采集的类型和范围。

数据展示 - 派可数据商业智能BI可视化分析平台
Where
操作地点。一般可以通过IP地址或经纬度确定。
Who
身份标识。这里主要介绍2种身份标识:用户账号和设备号。
用户账号是各个应用按照自己的规则赋予用户的内部身份标识。其中有些应用根据流量域属性、内容生产和消费属性等设计了多级账号体系;有些应用则使用单账号体系;有些使用大生态下的开放账号体系。
设备号是硬件设备的身份标识,包括但不限于手机、电脑、电视、智能可穿戴设备等。设备号的作用是识别一台具体设备,例如IMEI、IDFA、OAID等,生成设备ID的相关的算法也在不断优化升级以达到更准确的识别和标记。
在硬件推送(PUSH)场景下,用户账号要先转化为设备号才能进行正常推送。除此之外,设备号在黑产打击方面也有大规模的应用。
What
操作内容。诸如页面、曝光、点击等操作和相关的业务参数在此进行采集。在前端框架技术上支持的情况下,用户操作的来源和去向也可以根据统计需要进行采集。
数据采集和上报是为了优化服务的,不能过度影响到应用的正常功能,所以需要在一定程度上进行权衡与精简。而操作内容的采集场景,存在大量的前后端数据交互,若请求数据结构过大,则可能影响传输性能进而影响使用体验。
采集方式
埋点采集
前后端应用开发人员在特定场景下的特定时机,根据需要采集特定的参数。早期和中小型应用多使用该采集方式。其优点是开发成本低,修改灵活;但缺点是容易造成全局采集逻辑不一致的情况,后续维护成本和数据加工成本高。
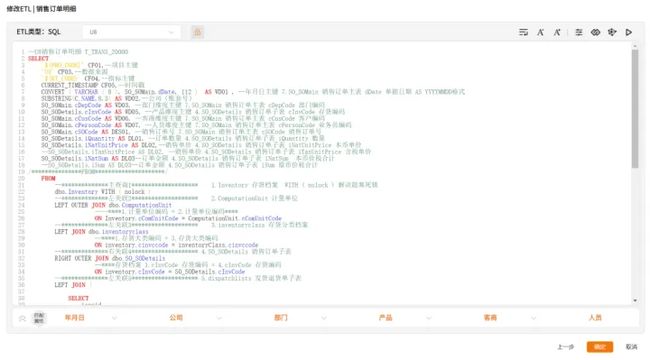
SQL - 派可数据商业智能BI可视化分析平台
SDK采集
SDK通过内部集成采集和缓存能力,统一采集时机和采集策略,标准化采集事件来进行全局参数采集,是从数据源头改善数据质量的重要方式,已经被越来越多的大型业务所使用。其优点是标准化程度高,降低前后端开发人员的开发量;缺点是开发这一套工具需要较大的前期投入。
采集时机和采集策略的统一是SDK采集相较于埋点采集的重大改进。用曝光场景举个例子,若使用埋点上报,有些开发人员在目标露出屏幕100个像素时采集,另一些开发人员可能在目标露出5%时进行采集;不同的开发人员在采集同一个参数时,使用的代码和采集路径也不一定完全相同。在大型应用中,数据的采集不是一次就能完成的,而是一个分阶段进行的过程,采集的参数个数也可能不是几个,而是几十上百个,所以不同的采集时机和采集策略就意味着能采集到参数的个数和质量也不尽相同。
BINLOG采集
BINLOG可以获取数据库的每一条变更记录,由此完成DB数据的采集。目前已经有比较成熟的开源组件可以直接使用。其优点是无需前后端开发人员的额外工作,但缺点是后续的数据加工会变得非常复杂,需要频繁的去重和取最新数据的操作,这在实时数据处理场景下几乎是致命的。
数据采集的质量决定了数仓质量的上限,数据开发的工程量是数据源质量和数仓设计与实施质量共同决定的。一个团队多做一点,另一个团队就少做一点,但在一些关键节点上,一个团队修补另一个团队的开发空缺可能是几倍甚至几十倍的工作量。在预期提供相同质量数仓的前提下,决策者需要合理平衡数据源开发和数仓开发的工作配比,才能更大程度地发挥数据价值。
(二)数据上报
拿到采集的数据以后,需要进行数据的上报,才能被后续的链路所使用。
客户端(前端)上报
客户端在采集到的数据后,直接或在缓存N条以后,批量将数据通过网络发送到日志服务器。这个过程可能由于网络波动或者用户直接杀掉进程导致部分数据上报缺失;有些应用为应对网络问题会内置上报重试逻辑,一定程度上解决上报缺失的同时也引入了重复上报的可能性。

数据大屏 - 派可数据商业智能BI可视化分析平台
无论是上报缺失或者上报重复,都是小概率事件,并且一般通过客户端上报的数据都是页面、曝光、点击这类的描述性数据,故在统计容忍的范围内仍可接受。
后台上报
后台服务在用户触发较为关键性的操作时(例如访问、下单、关注等)或者后台主动操作时(例如发券、回收权限等)进行相关参数的采集和上报,也是通过网络发送到日志服务器上。但因为后台服务一般处于比较稳定的内部生产环境,所以上报的成功率会比客户端更高,一些对准确性要求较高的统计数据可以使用后台上报的方式。
BINLOG上报
数据库BINLOG的采集和上报一般是集成在一起的,可以在采集后立即发送到消息队列(多为Kafka队列)完成数据上报。
(三)数据源选择
数仓里的数据不是业务DB里的数据,中间经过了采集和加工过程。
数据在加工链路上不可避免地会产生一定程度的丢失和延迟,所以在要求高准确性和低延迟的简单统计场景下,在不会影响到应用基本功能的前提下更推荐在DB内直接统计数据;在同样要求高准确和低延迟的较复杂场景时,也可以通过提高数仓建设标准和一定程度的定制开发,使用经数仓加工后的数据。

数据仓库 - 派可数据商业智能BI可视化分析平台
数据源的选择同样面临投入产出比的衡量,业务DB由于范式概念的设计,较难实现复杂的统计需求,但具有准确和快速的优点,数仓可以进行大规模复杂计算,但面对极低延迟和极强准确性的需求时也会提高其建设成本。