数字化时代,如何建造会“运转”的数仓
在建设数仓之前需要根据数据基础和业务需求来决定要建设什么标准的数仓。
常见数仓问题
1、公共底层加工逻辑分散:对于来自多个数据源,但需要使用相同过滤和解析方式公共底层数仓,其过滤和解析代码在每个任务或配置中直接静态复制,未做到统一管理。加工逻辑分散带来的影响是如果公共底层数仓字段需要更改(增删,修改过滤、解析方式等),需要刷新一遍所有相关任务的代码。如果还存在着无法感知到所有的修改位置、修改进度不一致、修改过程出现问题等情况,下游的数据使用就可能出现问题。
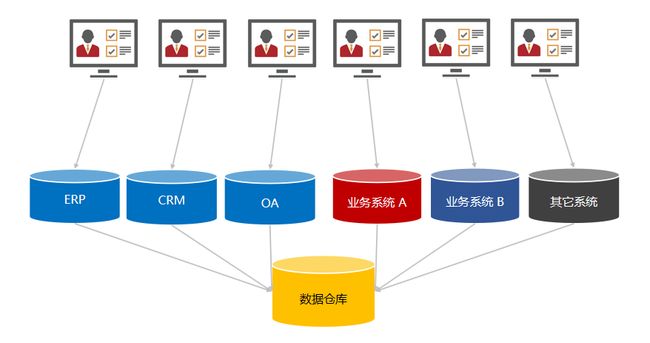
数据仓库 - 派可数据商业智能BI可视化分析平台
2、烟囱式开发:针对每一个需求或者每一个计算指标,都从底层数据开始,使用相同或极其相似的限定条件、计算逻辑、接出方式,产出的结果仅在很小范围内使用。烟囱式开发带来的影响是下游数据口径产生差异,重复解析造成的计算和存储资源浪费,无法通过扩大规模提升开发效率,并且不利于数据的团队内外共享。
3、批流建设分离:实时数仓和离线数仓在机制上无法使用相同的清洗和加工逻辑。这是Lambda架构下很常见的问题,可能直接影响到实时数仓和离线数仓的数据一致性。
局部业务问题
1、数据含义模糊:存在于数仓各个层级的数据中,包括但不限于字段内数据存在多义性、字段名与含义不符、维度和指标的组合存在偏差等。
数据的多义性会给下游使用带来困难,有时候下游需要确定性的某一种ID,那么就还需要恢复处理,如果判断条件不足还会出现无法分离的情况;字段名含义不符增大了数仓的使用成本,即每一次个字段的使用都要通读上游所有代码才能确定其含义;维度指标偏差则可能产生错误数据,并且给下游使用方带来困扰。
2、溯源性差:由于数仓加工代码逻辑限制,或者数据表的生命周期设置不合理,造成的历史数据重跑困难,或者历史问题现场无法恢复。数据的重算和问题溯源是常见的数仓需求,如果无法回溯则可能导致错误数据的累积,或者无法很好地帮助业务定位问题。
指标 - 派可数据商业智能BI可视化分析平台
3、指标膨胀:由于缺少规范上的约束,导致指标中涵盖了本可以作为维度的内容,造成了指标膨胀。随着业务的发展,膨胀过度的指标会导致应用数仓越来越臃肿且难以维护。
4、数仓规范缺失:数仓开发中缺少统一的规范限制,导致任务设置、元数据管理、数据层级调用、字段命名、计算口径等随着开发野蛮生长,并最终导致开发效率降低。
明确建设步骤
开始建设数仓之前,首先要全面了解业务逻辑,这样更便于做出正确的数据域和数仓架构划分。
确定了业务逻辑以后,下一个关键步骤就是抽象业务行为,也就是划分数据域。如果你的业务是内容类,那么曝光(页面、元素)、点击、播放、进入退出应用等就是业务内的基本行为;如果你的业务内容是电商类,那么加购物车、下单、支付、发货、退款等就是业务内的基本行为。
电商平台 - 派可数据商业智能BI可视化分析平台
不论自身业务的数据源质量如何,数据开发人员的价值体现为无论基于什么上报基础都能构建对下游友好的数仓。但也可以明显看出,如果数据源质量太过恶劣,那势必消耗数据开发人员大量的时间在清洗与规整上,在数仓其他方面的建设不免分身乏术,这时可能就需要考虑数据源治理的事情了。
遵循建设原则
一致性
一致性包含但不限于批流清洗逻辑的一致、指标计算口径的一致和维度含义的一致。
目前多数业务都有实时和离线两种时效性的数仓需求,无论是lambda架构还是kappa架构,要保证多事件(业务下所有数据域)、跨计算引擎(批处理引擎和流处理引擎)场景下的数仓逻辑统一,需要从机制上保证而不是直接在代码中,靠开发人员的工程素养,通过手动修改来保证。
终极解决方案是通过数据开发中台,保证全链路的逻辑一致性,使用界面拖拽代替代码开发来建设和修改数仓。但由于业务数据的复杂性极高,这种方案的研发投入和维护成本也特别高,故目前大多数业务使用到一些折中的方案。目前已经实现的是批流清洗逻辑的机制一致性。
准确性
准确性是数仓开发的生命线,对于希望使用数据驱动的业务来说,一份不准确的数据的危害比没有数据还要大。更细地来说,准确性可分为明细层字段的准确性,和聚合层计算逻辑的准确性。
数仓建模 - 派可数据商业智能BI可视化分析平台
明细层字段的准确性可以通过上报校验或者白名单入数仓来规范,上报校验的结果定期反馈给上报开发方进行修正。白名单过滤掉不合规范的数据,保证数仓内的数据100%可用,但因为更新白名单的成本高,并且会丢弃相当一部分业务数据,很少被正式业务所采用。
聚合层计算逻辑的准确性由于和业务耦合较深,一般通过业务开发间相互的代码CR、产品运营的数据敏感度和测试同学的用例测试来保证其准确性。
复用性
数据分层将数仓各个功能模块解耦,分别满足不同等级的数据需求,是重要的数据加工手段。这里二八定律依然有效,即20%的表可以满足80%的数据需求。根据每一个需求,从流水数据一路开发到应用数据的烟囱式开发是不可取的,因为在业务量扩大后,维护这些数据的统一就会变成一件非常麻烦的事情。
构建数据模型
无论上游的数据源多么复杂,数据上报是否规范,数据工程师的必备技能就要求能够将这些数据进行分类、筛选和处理,产出一套对下游来说含义清晰、使用便捷的数仓。
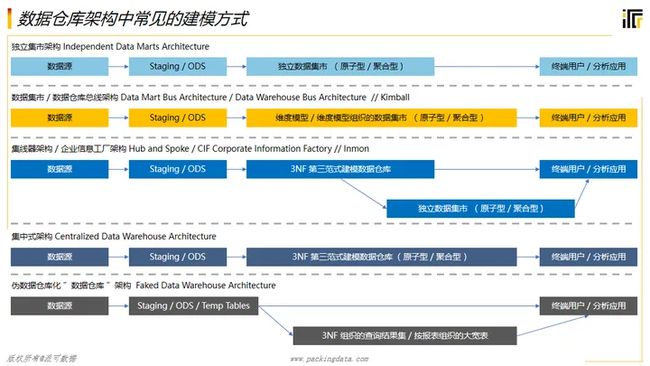
绝大多数业务,其基础数仓表都可以分为流水表和维表两大类,在此之上可以建立各种类型的聚合表、应用表、模型表等,构成如图所示的大致引用关系。
流水表
流水表是对用户的任意一个在现实中发生的不可拆分的行为的记录,也可称之为原子行为。例如交易就不是一个原子行为,因为其中包含了很多的过程;而下单、点击支付、支付成功可以算是——至少在一些简单业务里可以算是——原子行为。类似的还可以推广到一次瞬发技能释放、一个页面曝光、一次扫二维码、一条聊天发送等等。
轻度聚合表
指标 - 派可数据商业智能BI可视化分析平台
轻度聚合表主要实现对相似数据域的指标聚合和口径统一,并且保留部分重要的去重参数以便应用层进行后续计算。
可加和类指标(次数、金额等)从流水层需要经过一些计算逻辑才能变成对应指标,这个口径统一维护在轻度聚合层,不仅下游使用方可以避免理解复杂的计算逻辑,直接使用轻度聚合层加工好的指标,而且在口径需要修改时可以做到无需下游改动,同时生效。
轻度聚合层很明显地体现了数仓建设原则中的一致性和复用性。
维表
维表是对任意一层数据表中信息的关联与拓展,字典表也算一种维表。
一般情况下维表需要落地一份存储供下游使用,而不是从原始数据层直接解析后写在关联逻辑里。一方面避免读取上游表全部分区的情况,另一方面使下游维度的使用保持一致。
模型表
基于基础数仓可以根据使用需求构建一系列模型表。以下举两个例子简单描述其使用场景,其他种类的模型表可以举一反三。
用户模型表不仅可以保存性别、年龄、学历等基础信息,也可以附带来源渠道、活跃度、进行某些关键行为的次数、内容消费习惯等业务拓展信息,提供更全面的分析基础。
漏斗模型表可以统计群体用户在某种周期内,每一个步骤的操作。在内容类应用里,可以是用户从进入应用的每一步跳转直到退出的过程;在交易类应用里,可以是从浏览、加购物车、下单、支付直到完成售后的过程。