大数据技术——spark集群搭建
目录
spark概述
spark集群搭建
1.Spark安装
2.环境变量配置
3.Spark集群配置
4.启动Spark集群
存在问题及解决方案
请参考以下文章
spark概述
Spark是一个开源的大数据处理框架,它可以在分布式计算集群上进行高效的数据处理和分析。Spark的特点是速度快、易用性高、支持多种编程语言和数据源。Spark的核心是基于内存的计算模型,可以在内存中快速地处理大规模数据。Spark支持多种数据处理方式,包括批处理、流处理、机器学习和图计算等。Spark的生态系统非常丰富,包括Spark SQL、Spark Streaming、MLlit
GraphX等组件,可以满足不同场景下的数据处理需求。
spark集群搭建
在部署spark集群时,我们知道有三种:
一种是本地模式,一种是Standalone 集群,还有一种是云端。
1.Spark安装
首先我们需要在master节点上进行Spark的安装。
其中1台机器(节点)作为Master节点,主机名为hadoop1,另外两台机器(节点)作为Slave节点(即作为Worker节点),主机名分别为hadoop2和hadoop3。
在Master节点机器上,访问Spark官方下载地址Downloads | Apache Spark,按照如下图下载:

我们选择2.1.0的版本,也可以选择其他的版本,但是需要注意的是,如果你选择的Spark版本过高,可能导致无法与你的hadoop版本适配。
完成下载后,进行如下的命令行操作,和hadoop安装时十分类似。
$ tar -zxvf scala.2.11.8.tgz #解压到当前路径


$ cd /usr/local
$ sudo mv ./spark-2.1.0-bin-without-hadoop/ ./spark #重命名

spark安装与上述Scala步骤一致
2.环境变量配置
同样在master机器上,打开bashrc文件进行环境变量配置。
$ vim ~/.bashrc
在文件中添加如下内容
export PATH=$PATH:/usr/local/scala/bin并使其生效。

保存文件并退出vim编辑器,执行如下命令让改环境变量生效:
$ source ~/.bashrc
设置好后,可以使用Scala命令来检验一下是否设置正确:
$ scala

输入scala命令以后,屏幕上会显示Scala和java版本信息,并进入“scala>”提示符状态,这时就可以开始使用Scala解释器了,可以输入scala语句来调试scala代码。
3.Spark集群配置
进入到/usr/local/spark的conf路径下,进行以下文件的配置。
a)配置slaves文件
但是由于其开始并没有这个文件,而只有slaves.template文件,所以我们需要先拷贝重命名一下。
$ cd /usr/local/spark/conf/
$ cp ./slaves.template ./slaves

然后打开这个slaves文件,并将默认的localhost替换相应的两个slave结点:
hadoop2
hadoop3
分别在三台虚拟机上修改slaves文件:
hadoop1:

hadoop2:

hadoop3:

b)配置spark-env.sh文件
同样的,我们需要先将template文件拷贝重命名。
将 spark-env.sh.template 拷贝到 spark-env.sh
$ cp ./spark-env.sh.template ./spark-env.sh
然后在文件中添加如下内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export SPAEK_MASTER_HOST=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop分别在三台虚拟机上修改spark-env.sh文件:
hadoop1:

hadoop2:

hadoop3:

c)集群规划
| 节点 |
spark节点 |
hadoop节点 |
| hadoop1 |
master worker |
datanode namenode secondarynamenode(hadoop) resourcemanager nodemanager(yarn) |
| hadoop2 |
worker |
datanode nodemanager |
| hadoop3 |
worker |
datanode nodemanager |
4.启动Spark集群
因为我们的Spark是基于hadoop来运行的,因此我们首先需要将hadoop启动起来。
启动Hadoop集群

在master机器上运行如下指令启动hadoop集群
$ cd /usr/local/hadoop/
$ sbin/start-all.sh
hadoop1:

hadoop2:

hadoop3:

启动spark集群
然后我们再再master机器上启动Spark的master进程。
$ cd /usr/local/spark/
$ sbin/start-master.sh
使用jps命令查看master机器上的进程情况,结果如下。
hadoop1:

我们发现,除了hadoop的相关进程之外,还多了一个Master进程,证明master节点已经成功启动。
然后我们同样在master机器上再启动worker进程。
用以下命令启动所有的slave节点
$ sbin/start-slaves.sh
hadoop1:

分别在hadoop2、hadoop3节点上运行jps命令,可以看到多了个Worker进程
hadoop2:

hadoop3:
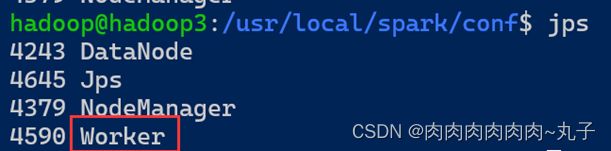
我们发现,同样的除了hadoop的相关进程,多出来一个Worker进程,证明worker节点也已经成功启动。
在浏览器上查看Spark独立集群管理器的集群信息
在master主机上打开浏览器,
分别访问http://192.168.43.33:50070,如下图:

分别访问http://192.168.43.33:8080,如下图:

$ spark-shell #进入shell

关闭spark集群
①关闭master节点
$ sbin/stop-master.sh
②关闭worker节点
$ sbin/stop-slaves.sh
③关闭Hadoop集群
$ cd /usr/local/hadoop/
$ sbin/stop-all.sh

存在问题及解决方案
请参考以下文章
大数据技术——搭建spark集群出现的问题_肉肉肉肉肉肉~丸子的博客-CSDN博客