【C语言进阶】 假期测评③
day01
1. 改变形参不影响实参
以下程序执行后的输出结果为()
#include A: 2 B: 编译错误 C: 1 D: 无法确定
【答案解析】C
调用函数func时传的是s的值,形参p的改变,并不会改变s本身, *s拿到的还是首地址的字符’1’
2. 二维数组省略
已知数组D的定义是
int D[4][8]; 现在需要把这个数组作为实参传递给一个函数进行处理。下列可以作为对应的形参变量说明的是【多选】( )
A:int D[4][]
B:int *s[8]
C:int(*s)[8]
D:int D[][8]
【答案解析】CD
数组D是一个二维数组,函数传参时数组名退化为首元素地址,就是第一行的地址,是一维数组的地址,为int(*)[8]类型,C正确,
B选项是指针数组的,这里不行;
若想写成数组的形式,则列不能省行可以省,(对于多维数组,较低维度都是不可省略的)
D选型格式是对的,A选项不对
3. 查找质数
博客讲解
单纯的使用枚举法会超出时间限制

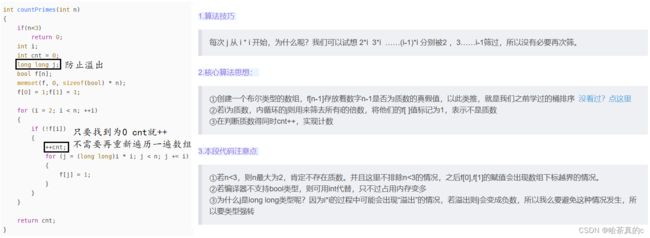
day02
4. 位运算
day03
5. 字符串赋值给指针
设有定义: char *p; ,以下选项中不能正确将字符串赋值给字符型指针 p 的语句是【多选】( )
A:p=getchar();B:scanf("%s",p);C:char s[]="china"; p=s;D:*p="china";
【答案解析】ABD
A选项,首先类型就不匹配,getchar()函数返回值是int ,只能赋值给整型,此时p为char*类型。
B选项,p指针在定义的时候没有分配内存,这行代码在运行的时候会报野指针错误。
C选项,指针p指向数组s。
D选项,*p代表p指向内存的内容, 这里要使用p = "china"才正确

6. 指针类型的判断
若有定义语句:
char s[3][10],(*k)[3],*p;则以下赋值语句错误的是()
1.p = s;
2.p = k;
3.p = s[0];
4.k = s;
A: 124 B: 1234 C: 12 D: 234
【答案解析】A
题目主要就考指针类型是否一样,char s[3][10]中s运算时会退化为数组指针,类型为char (*)[10],所指向的每个数组长度为10;
char (*k)[3]很明显k就是一个数组指针,类型也为 char (*)[3],所指向的每个数组的长度为3;
char *p类型为char *指针,s[0]代表二维数组第一行,运算时会退化为第一行首元素地址,类型为char *
在没有强制类型转换的情况下,只有类型完全相同的指针才能相互赋值
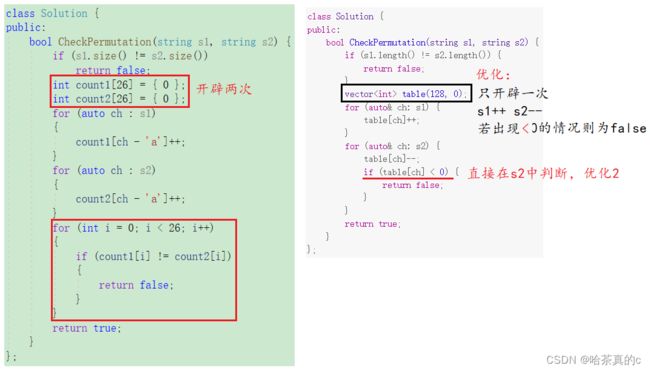
7. 判断两字符串元素是否相等
day04
8. 指针++移动
运行以下C语言代码,输出的结果是( )
#include A: stra strb strc B: s t r C: stra tra ra D: s s s
【答案解析】C
p是char*类型,每次++,后移一个地址, char *p = str[0]相当于char *p = “stra”,p先指向其中的字符’s’,printf输出遇到0停止,第一次输出"stra",p++后,指向字符’t’,第二次输出"tra",第三次输出"ra"
9. 循环判断
程序的结果是什么( )
A: abdcccd B: abdd C: abcc D: abddcccd
#include【答案解析】D
内层while循环的作用让指针it2跳过字符’c’,第一次越过后停在原字符串第一个’d’上,而在之前it1和it2是同步的,赋值不会改变字符串内容,此时it1停在第一个’c’上,*it1++ = *it2++;语句将’c’替换为’d’,字符串变更为"abddcccd",同时指针it1加加停在第四个字符’d’上,it2再次跳过字符’c’,停在最后一个’d’上,赋值后,字符串不变, 再后移外层循环遇到0结束
day05
10. 忘记释放内存后果
假设C语言程序里使用 malloc 申请了内存,但是没有 free 掉,那么当该进程被kill之后,操作系统会( )
A: 内存泄露 B: segmentation fault C: core dump D: 以上都不对
【答案解析】D
不管用户程序怎么用malloc,在进程结束的时候,用户程序开辟的内存空间都将会被回收。只有在进程运行的过程中,忘记释放内存才会造成内存泄漏
11. 联合体的性质
设有以下定义,则下面叙述中正确的是【多选】()
union D
{
int d1;
float d2;
}d;
A: 变量d与各成员的地址相同
B: d.d1和d.d2具有相同的地址
C: 若给d.d2赋10后,d.d1中的值是10
D: 若给d.d1赋10后,d.d2中的值是10
【答案解析】AB
虽然d1,d2地址相同,但存储的是二进制,浮点型的10和整型的10,二进制是不同的,所以读取出来的结果也是不同的
C,D所要表达的意思就是以浮点数/整型存储再以整型/浮点数的形式读取,显然结果不同
12. 移位操作:<< >>区别

day06
13. 内存管理函数性质
关于内存管理,以下有误的是( )
A: malloc在分配内存空间大小的时候是以字节为单位
B: 如果原有空间地址后面还有足够的空闲空间用来分配,则在原有空间后直接增加新的空间,使得增加新空间后的空间总大小是:newSize
C: 如果原有空间地址后面没有足够的空闲空间用来分配,那么从堆中另外找一块newsize大小的内存,并把先前内存空间中的数据复制到新的newSize大小的空间中,然后将之前空间释放
D: free函数的作用是释放内存,内存释放是标记删除,会修改当前空间的所属状态,并且会清除空间内容
【答案解析】D
选项A:malloc函数用来动态地分配内存空间,其原型void* malloc (size_t size); size 为需要分配的内存空间的大小,以字节(Byte)计。
选项B:realloc函数,其原型extern void *realloc(void *mem_address, unsigned int newsize);如果有足够空间用于扩大mem_address指向的内存块,则分配额外内存,并返回mem_address。realloc是从堆上分配内存的,当扩大一块内存空间时,realloc()试图直接从堆上现存的数据后面的那些字节中获得附加的字节,即如果原先的内存大小后面还有足够的空闲空间用来分配,加上原来的空间大小= newsize,得到的是一块连续的内存。
选项C:realloc函数,如果原先的内存大小后面没有足够的空闲空间用来分配,那么从堆中另外找一块newsize大小的内存,并把原来大小内存空间中的内容复制到newsize中,返回新的mem_address指针,而后释放原来mem_address所指内存区域,同时返回新分配的内存区域的首地址。
选项D:free函数,作用是释放内存,内存释放是标记删除, 只会修改当前空间的所属状态,并不会清除空间内容(在代码实现过程中,free结束,通常后面要加上xxx = NULL)
14. 柔性数组
如下程序输出的结果是什么( )
#include A: 4byte B: 8byte C: 5byte D: 9byte
【答案解析】B
题目中的char data[0]或写成char data[],即为柔性数组成员;
在计算机结构体大小的时候data不占用struct的空间,只是作为一个符号地址存在。因此sizeof的值是两个指针所占字节,即4+4=8字节
15. free/malloc 性质
以下有关C语言的说法中,错误的是( )
A: 内存泄露一般是指程序申请了一块内存,使用完后,没有及时将这块内存释放,从而导致程序占用大量内存,但又不使用不 释放
B: 可以通过malloc(size_t)函数调用申请超过该机器物理内存大小的内存块
C: 无法通过内存释放函数free(void*)直接将某块已经使用完的内存直接还给操作系统,free函数只是将动态申请内存的使用权释放
D: 可以通过内存分配函数malloc(size_t)直接申请物理内存
【答案解析】D
free释放的内存不一定直接还给操作系统,可能要到进程结束才释放。malloc不能直接申请物理内存,它申请的是虚拟内存
16. 读写文件
若要用 fopen 函数打开一个新的二进制文件,该文件既能读也能写,则文件方字符串应是( )
A: “ab++” B: “wb+” C: “rb+” D: “ab”
【答案解析】B
w+以纯文本方式读写,而wb+是以二进制方式进行读写。
mode说明:
w打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
wb只写方式打开或新建一个二进制文件,只允许写数据。
wb+读写方式打开或建立一个二进制文件,允许读和写。
**r打开只读文件,该文件必须存在,**否则报错。
r+打开可读写的文件,该文件必须存在,否则报错。
rb+读写方式打开一个二进制文件,只允许读写数据。
a以附加的方式打开只写文件。
a+以附加方式打开可读写的文件。
ab+读写打开一个二进制文件,允许读或在文件末追加数据。
加入b字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件
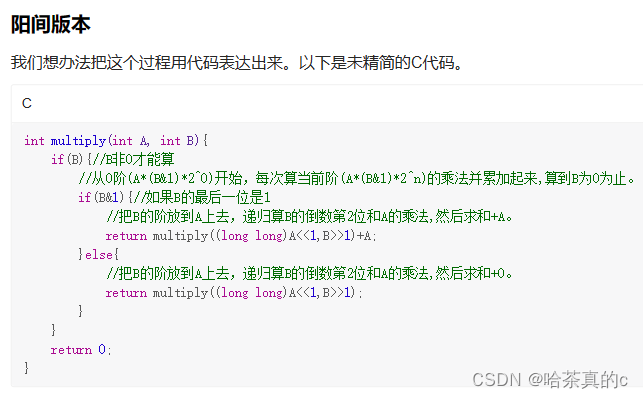
17. 十进制乘法转换成二进制移位
详细解法:


day07
18. fputc函数返回值
若调用 fputc 函数输出字符成功,则其返回值是( )
A: EOF B: 1 C: 0 D: 输出的字符
【答案解析】D
fputc()写入成功时返回写入的字符,失败时返回EOF即-1,返回值类型为int也是为了容纳这个负数
19. 5的倍数
【答案解析】


20. 强转的意义
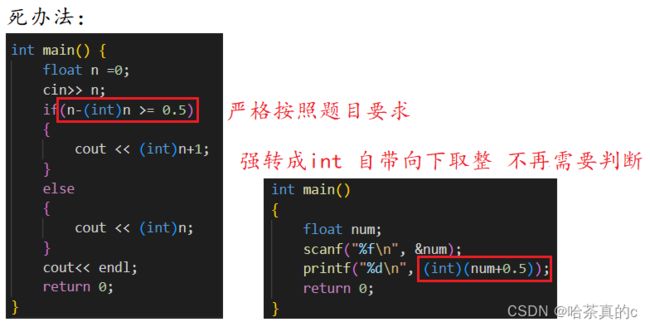
day08
21. #define的替换
以下代码的输出结果是( )
#include A: 10…10 B: 10…50 C: Error D: 0
【答案解析】A
**define在预处理阶段就把main中的a全部替换为10。**另外,不管是在某个函数内,还是在函数外,define都是从定义开始直到文件结尾,所以如果把foo函数的定义放到main上面的话,则结果会是50…50
22. 数据推导:建表
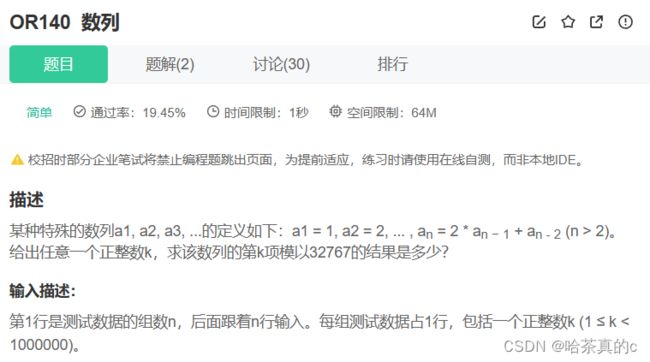
【答案解析】
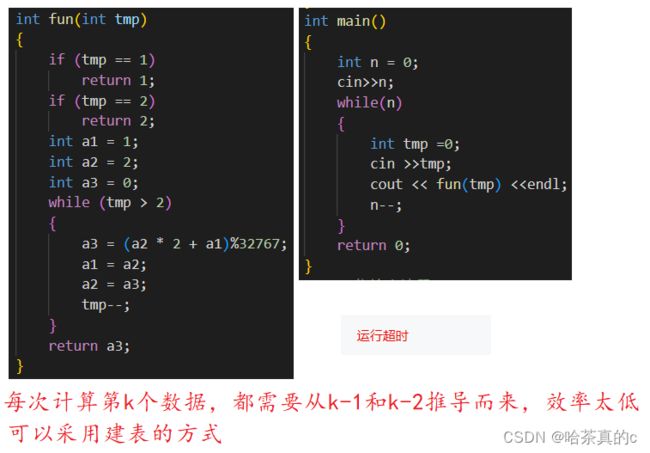
这道题其实本身并不难,有了具体的公式直接循环往后推导就可以得到结果。但是当测试用例有多个的情况下,每次重新计算第k个数据,效率就要差很多了,毕竟每个数都要从头重新计算一遍。
因此程序进入后首先可以先生成一个较大的数列,后边测试用例中需要第几个直接取出即可。
#include 