【Linux】初识进程间通信
文章目录
- 前言
- 一、预备知识
- 二、管道
- 匿名管道
-
- 测试1
- 匿名管道的特性总结:
- 进程间通信代码
- 测试2
- 理解命令行管道
- 命名管道
-
- 进程间通信代码
- 实现两个进程之间的通信
- 注意事项:
- 三、共享内存
-
- 3.1shmget
- 3.2shmdt
- 3.3shmctl
- 3.4shmat
- 进程间通信代码
- Makefile生成
- 3.4管道 vs 共享内存
- 3.5shmid vs key
- 四、消息队列
-
- 4.1msgget
- 4.2msgsnd
- 4.3msgrcv
- 4.4msgctl
- 进程间通信代码
- 结果:
- 初识原子性
- 初识信号量
- 五、信号量
-
- 5.1semget
- 5.2semctl
- 5.3semop
- 进程间通信代码
- 结果
- 总结
前言
一、预备知识
1.通信的本质是传递数据,进程间能“直接”传递数据吗?
进程与进程之间要保持独立性,是无法直接传递数据的,所有的数据操作,都会发写时拷贝。
2.两个进程要互相通信,他们就得看到同一份资源,这份资源往往是内存,系统通过某种方式提供的系统内存。
3.两种标准的差异:
System V,主机内通信。
POSIX,主机上的进程能跨网络。
本章讲述的接口都是Sysem V的!!
二、管道
匿名管道
供具有血缘关系的进程,进行进程间通信。(常见于父子)
理论讲解:
父进程以读,写各自打开一次文件(假设pipe_file),然后fork创建子进程,父子进程就都能看到这个pipe_file了。
分析:
子进程拥有独立的pcb,页表,进程地址空间,文件描述符表,但是文件描述表的内容是从父亲继承下来的,也就是文件描述表指向的文件跟父亲相同。
此时下图的3,4号文件描述符可以被父子进程看到。此时一个进程读,一个进程写,就能实现进程间通信。
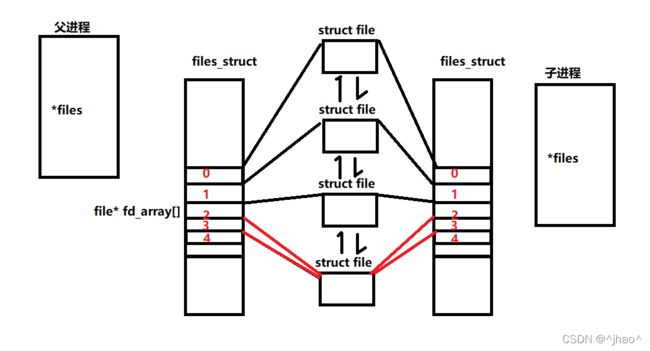
管道特性:单向通信
管道只能进行单向通信,所以上面只能一端写,一端读,如果又双向通信的需求,建立两个管道。且文件的读写位只有一个,如果要双向通信那么读写位需要两个,这样就完成不了了。
例如ftell返回值一个整数,标识文件指针位置,只有一个进程才能用。
管道文件性质
从上图看,管道也就是文件,只不过它不需要进行持久化保存,打开的文件使用完过后里面的数据不需要真的向磁盘上刷新。
以读写方式打开原因再fork的原因:
父进程假设只读,那么子进程看到的文件也是只读方式,两个只读的无法进行通信。同理两个进程都是写也无法进行通信。
而读写都打开可以让用户层协商谁读谁写,这样更加灵活。
为什么一定要关闭fork后不用的文件描述符
不关闭虽然能跑,但是关闭上能防住误操作,并且语义上也符合管道的属性。
测试1
验证pipe函数的使用
参数为输出型参数,我们外面定义会拿到打开管道文件的描述符。
pipe是帮我们创建一个管道文件的接口,让父子都能够看到这个管道文件,再让用户层协商谁来读谁来写。
fd[0],fd[1]读写记忆方式
close关闭文件描述符,数组下标0是读端,数组下标1是写端。
记忆方式:0想象成嘴巴,读,1像,是写端。
结束条件:
当写端不写了,并且关闭了文件描述符,那么读端就会读到0,读端也就会退出了。
以下我们用子进程进行写操作,父进程进行读操作,这样方便观察实验现象。
#include结果:

分析上面代码结果:
匿名管道的特性总结:
1.管道自带同步机制
观察上面的代码,我们发现父进程是被阻塞住了的,父进程一直在读取,但是却按着子进程的发送速率打印,说明父进程在等待,等管道内部有数据就绪
同理写端将管道写满,而读端没有读取,那么写端也会被阻塞住。此时就是等待管道内部有空闲空间。
1.1为什么要有信息同步机制?
为了数据的安全。
若管道空了还在读取,会读取到垃圾数据。若管道满了还在写,会覆盖之前写的有用的数据,这两种都会导致获取的信息不正确。
2.管道是单向通信的
3.管道是面向字节流的
计算机的文件是基于流的,字节流可以理解为当我们有一段缓冲区,我们往缓冲区上读和写都可以任意步长,我们可以通过多次读/写完成。
4.管道只能保证具有血缘关系的进程通信,常用于父子
5.管道可以保证一定程度的数据读取的原子性
有些数据不能分开读取,只有在一起读取上来才有意义。因为分开读取可能会有歧义。而管道支持4KB数据内的原子性,本身具有同步互斥机制。
进程间通信代码
验证管道内的空间大小:
我们让子进程一直写,count标识写了多少次,我们一次写一个字符(1字节),看什么时候塞满管道。
#include实验结果:64KB,云服务器的管道大小是64kb

也可以通过ulimit -a 单位512字节,8个;即4KB,这个4KB通过man 7 pipe,可以看到PIPE_BUF是4KB保证原子性的最大容量。
 PEPE_BUF介绍:
PEPE_BUF介绍:
测试2
如果读端不读,且关闭文件描述符,write该如何呢?
结论:读取关闭,此时写已经无意义了,是一种浪费系统资源的表现,操作系统就会给写端发送信号SIGPIPE,让写进程终止。
代码测试
#include结果:收到13号信号SIGPIPE
匿名管道通信情况总结:

理解命令行管道
命令行当中的兄弟进程管道实现进程间通信。
|实际上是一条匿名管道,他们是有血缘关系的。
sleep 1000 | sleep 2000 | sleep 3000 &


理解进程退出,曾经打开的文件被关掉:
进程退出,曾经打开的文件不会去读/写,读写位只有一个,关掉我这一端往后不会再有去对文件读写了(除非再次打开),所以操作系统会把数据拷贝到磁盘,关闭我们的文件。
命名管道
理解命名管道的特点
路径本身就有唯一性,文件有保存内容的属性。让不同的进程以读写方式打开同一份文件,相当于进程间能看到同一份资源,就是管道文件不会写入,都在内存当中完成。

与匿名管道相比,他不同的点在于它可以让任意进程间进行通信。
而匿名管道和命名管道都是管道文件;普通文件是需要将数据刷新到磁盘(持久化存储),而管道文件不需要,都在内存当中完成,所以说管道文件在进行进程间通信的效率是很高的。
进程间通信代码
mkfifo创建一个命名管道
mkfifo命令
执行下面代码:
[ljh@VM-0-11-centos 2.28]$ mkfifo mypipe
[ljh@VM-0-11-centos 2.28]$ while :; do echo "hello world"; sleep 1;done > mypipe
结果:管道文件的大小还是0,cat生成进程后可以输入重定向打印到显示屏上。实现了两个进程之间的通信。

实现两个进程之间的通信
我们用mkfifo就可以实现两个进程之间的通信,mkfifo既是命令,也是一个基于系统调用做了封装的函数,作用就是创建一个管道。
server.c
#includeclient.c
#include结果:与匿名管道一样,将调用pipe函数变为调用mkfifo函数,能够实现非亲缘关系进程间的通信,也就是通过文件系统标识唯一一个路径(一块内存),让双方实现通信
注意事项:
1.管道也是文件,管道的生命周期随进程。
2.匿名管道即是原子性的,又是字节流的,不冲突吗?
原子性限制的是一次读一次取,但是没有规定读取几个读取几个,你可以原子性一次读一个也可以读两个,它是满足流式的定义的。
3.匿名管道与命名管道他们的底层原理是基本一样的,唯独就是通信的进程是否亲缘关系。
三、共享内存
共享内存比管道通信速度快
管道通信分析:
管道中,我们需要进行进程间通信的时候,内核会为我们开辟一块内存,我们进程1用调用write函数将数据拷贝到内存,进程2若要读取需要调用read函数将内存当中写到buffer中。
上述过程当中管道是操作系统管理的一块内存,调用write函数需要从用户态到内核态,write执行结束需要从内核态转换为用户态。将数据拷贝至管道,而从进程2要读取管道中的内容,需要调用read函数从用户态到内核态,借操作系统将数据从管道搬运到进程2的用户级缓冲区当中,read结束便由内核态转化为用户态。
即上述过程涉及4次上下文切换,2次数据拷贝。
上下文切换的单次时间消耗在微妙级别,虽然很快,但是在高并发的场景下时间会变得更长。

共享内存通信分析:
共享内存区是最快的IPC形式,只需通过内存映射到共享他的进程的地址空间,这些进程间数据传递就不需要涉及内核。
那么共享内存是如何做到比管道速度更快的呢?
- 1.OS申请物理空间(shmget)
- 2.OS将该内存映射到对应进程的共享区(shmat)
- 3.再把虚拟地址给用户(shmat的返回值)
操作系统是硬件的管理者,又是进程的管理者,申请一块内存是可以做到的。
这就是共享内存申请使用的一个机制。假设进程1申请了一块共享内存,申请了4096字节(一页),然后在上面写入字符串。写入的过程可以类似malloc返回一个指针,我们可以直接进行写入操作,不需要调用read/write接口。而进程2在进程写入之后立马就能够看见。所以共享内存是很快的,并且他的写入操作无需调用系统调用,也以为不需要进行上下文切换,所以他是最快的一种IPC方式是名不虚传的。

由于共享内存是很多的,同一时间可能有多个进程,有多个进程通过共享内存在通信,所以共享内存需要组织,管理起来。
在这个期间内核当中需要对一个共享内存进行标识,也就是key值,如果没有key值,我们的进程甚至不知道哪一块共享内存是属于自己的,key值是由用户调用函数生成的(ftok)
ftok:通过pathname和proj_id通过某种算法每次都生成一个绝对的数值,如果重复可以更改pathname或者proj_id,pathname和proj_id可以放在comm.h,这个是通信双方确定的。
NAME
ftok - convert a pathname and a project identifier to a System V IPC
key
SYNOPSIS
#include 生成了一个key值后,因为这个key值是我们用户层的,我们需要把他弄到内核当中标识一个唯一的共享内存。我们采用shmget将key设置到内核描述的结构体当中。
其中的size最好是以页的倍数来是申请,不管你是否使用,常见的4096字节就是一页,我们申请就尽量4096*n,就能减少内碎片问题。
shmflg可以设置共享内存的权限以及IPC_CREAT|IPC_EXCL| 0644可以保证建立一个不重复的共享内存,而使用方shmflg字段设置为0就可以了。
而使用的时候可以用shmflg设置成0就可以了,单独使用IPC_EXCL没有意义。
返回值是用户层来用于标识共享内存。
3.1shmget
功能:用来创建共享内存
原型
int shmget(key_t key, size_t size, int shmflg);
参数
key:这个共享内存段名字
size:共享内存大小,建议是4096的整数倍
shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1
3.2shmdt
这个函数可以让进程与共享内存取消挂接,我们通过命令ipcs -m可以看到nattch的数目减一,当然,如果没有调用这个函数而进程退出了,nattch也会减一。
类似free
功能:将共享内存段与当前进程脱离
原型
int shmdt(const void *shmaddr);
参数
shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段
3.3shmctl
删除一个共享内存,当当前进程执行该函数时,该进程自动会与共享进程取消挂接,并且等待其他进程退出然后将共享内存取消。若有进程未退出,则ipcs -m的status一栏可以看到dest的标识。
功能:用于控制共享内存
原型
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
shmid:由shmget返回的共享内存标识码
cmd:将要采取的动作(有三个可取值)
buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1
在内核建立完成后,我们需要和我们的进程关联起来,shmat就是让进程看到这块共享内存的函数。其中的shmaddr设置为NULL可以让系统根据进程自动选择一块,而shmflg可以

3.4shmat
类似malloc
功能:将共享内存段连接到进程地址空间
原型
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数
shmid: 共享内存标识
shmaddr:指定连接的地址
shmflg:它的两个可能取值是SHM_RND和SHM_RDONLY
返回值:成功返回一个指针,指向共享内存第一个节;失败返回-1
进程间通信代码
comm.h
#pragma once
#define PATH "./Makefile"
#define PROJ_ID 8080
#define SIZE 4096
server.cc
#include"comm.h"
#includeclient.cc
#include"comm.h"
#include结果:

共享内存类比堆:
之前我们学过的malloc是在堆上面开辟一块空间,再将这块空间与进程地址空间挂接,让申请的进程独享这块空间,而共享内存则是在共享区申请一块内存,有需要的进程都可以来挂接这块内存,让多个进程看到同一块资源。
1.申请共享内存
2.进程1和进程2分别挂接对应的共享内存到自己的地址空间(共享区)
3.双方看到同一份资源,就可以进行正常通信了。
以上均有对应的系统调用接口提供服务。
OS内存在大量的共享内存,那么就需要管理起来。
管理即先描述,后组织。
描述用的是结构体。
Makefile生成

注意: ipc资源资源随内核,如果进程没有调用shmctl或者没有ipcrm -m,并且ipcrm -m删除用shmid比较好,因为这也是一条命令,命令是用户调用的,也会贯穿操作系统的体系结构执行。
1.共享内存的生命随系统
2.共享进程不提供任何同步与互斥的操作,双方彼此独立
3.共享内存是所有进程间通信最快的
3.4管道 vs 共享内存
减少两次拷贝(read/write)!!

共享内存的大小:
系统分配共享内存的时候,是以4KB为基本单位的!4097则会浪费4095的内存,并且这部分内存别的内存申请不到!!
3.5shmid vs key
key是内核层的标识,是用户层生成的唯一键值,核心作用在内核当中保证一块共享内存的唯一性。 类比 文件的inode
shmid是用户层的标识,是系统给我们返回IPC资源的标识符,用来进行操作ipc资源。 类比 文件的fd。
而命令和代码都是用户层操作,也是操作IPC资源的标识符!
共享内存的数据结构

类似于切片,通过强转成消息队列或者共享内存就可以用数组的方式将ipc资源维护起来。


大家都是用key来标识一块内存,只不过描述的方式可以不同
四、消息队列
消息队列原理:

进程间通信的本质都是让进程去看到同一块内存资源,只是内存管理的方法有所不同,对应性质也会有所不同。
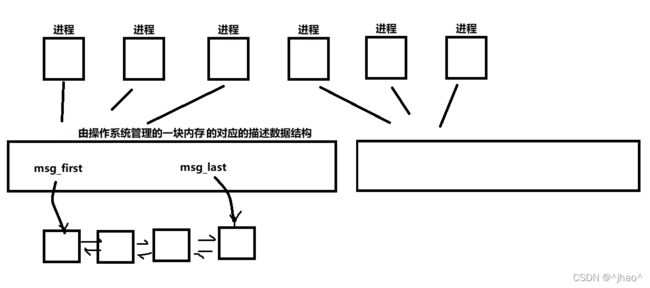
1.进程要能定位到同一块共享内存(操作系统要管理很多共享内存)
2.每个数据块都被认为是有⼀个类型,接收者进程接收的数据块可以有不同的类型值
3.消息队列也有管道⼀样的不⾜,就是每个消息的最⼤⻓度是有上限的(MSGMAX),每个消息队
列的总的字节数是有上限的(MSGMNB),系统上消息队列的总数也有⼀个上限(MSGMNI)
4.1msgget
和shmget一摸一样,key值用ftok生成,server端创建的时候用O_CREAT|O_EXCL保证创建出一个新的消息队列
功能:⽤来创建和访问⼀个消息队列
原型
int msgget(key_t key, int msgflg);
参数
key: 某个消息队列的名字
msgflg:由九个权限标志构成,它们的⽤法和创建⽂件时使⽤的mode模式标志是⼀样的
返回值:成功返回⼀个⾮负整数,即该消息队列的标识码;失败返回-1

有了消息队列,就可以往消息队列里面发送数据,让其他进程再去读取。
4.2msgsnd
第一个参数是msgget的返回值,第二个参数要传递一个结构体的指针,这个结构的描述方式大概如下图,他的第一个字段可以用来描述发送数据的类型,第二个字段就是进程要真正发送的数据;第三个参数msgsz的作用是标识真正要发送数据的大小(不包含第一个字段);第四个字段可以在队列满的时候选择是阻塞式等待还是立即返回。
功能:把⼀条消息添加到消息队列中
原型
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
参数
msgid: 由msgget函数返回的消息队列标识码
msgp:是⼀个指针,指针指向准备发送的消息,
msgsz:是msgp指向的消息⻓度,这个⻓度不含保存消息类型的那个long int⻓整型
msgflg:控制着当前消息队列满或到达系统上限时将要发⽣的事情
msgflg=IPC_NOWAIT表⽰队列满不等待,返回EAGAIN错误。
返回值:成功返回0;失败返回-1
注意:
消息结构在两⽅⾯受到制约:
⾸先,它必须⼩于系统规定的上限值 ;
其次,它必须以⼀个long int⻓整数开始,接收者函数将利⽤这个⻓整数确定消息的类型
这里的其他数据可以是任何类型,并且不管是二进制数据还是文本,内核根部不解释消息数据的内容。
这里的mtext设置成char [1]类似于一种模板,通常一个字节是不够用的,一个消息的数据可以由应用去定义消息结构。
模板:

应用层自定义结构体: 只要是第一个字段放long就可以了,这个结构体也可以只放一个long,即发送真正的数据长度为0.

4.3msgrcv
接受方可以定义一个struct msgbuf的结构体,然后填入msgrcv第二个参数,通过第四个参数msgtype 从指定的队列当中 希望能获得的数据类型,就会通过这个数据类型在消息队列里面找,找到填入struct msgbuf;第二个参数为接受的消息长度;第四个参数和上面一样,消息队列有可能被填满,也有可能没有消息,设置msgflg可以决定发生没有数据的时候是阻塞等待还是立即返回。
功能:是从⼀个消息队列接收消息
原型
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtype, int msgflg);
参数
msgid: 由msgget函数返回的消息队列标识码
msgp:是⼀个指针,指针指向准备接收的消息,
msgsz:是msgp指向的消息⻓度,这个⻓度不含保存消息类型的那个long int⻓整型
msgtype:它可以实现接收优先级的简单形式
msgflg:控制着队列中没有相应类型的消息可供接收时将要发⽣的事
返回值:成功返回实际放到接收缓冲区⾥去的字符个数,失败返回-1
注意:
msgtype=0返回队列第⼀条信息
msgtype>0返回队列第⼀条类型等于msgtype的消息
msgtype<0返回队列第⼀条类型⼩于等于msgtype绝对值的消息,并且是满⾜条件的消息类型最⼩的消息
msgflg=IPC_NOWAIT,队列没有可读消息不等待,返回ENOMSG错误。
msgflg=MSG_NOERROR,消息⼤⼩超过msgsz时被截断
msgtype>0且msgflg=MSG_EXCEPT,接收类型不等于msgtype的第⼀条消息。
4.4msgctl
消息队列的控制函数,和共享内存差不多,可以用于删除消息队列,也可以用户定义一个struct msgbuf替换已有的消息队列的节点。
功能:消息队列的控制函数
原型
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
参数
msqid: 由msgget函数返回的消息队列标识码
cmd:是将要采取的动作,(有三个可取值)
返回值:成功返回0,失败返回-1
cmd的三种状态

设置如下字段就可以特定的队列进行节点替换了。

消息队列有同步互斥机制!
进程间通信代码
comm.h
#pragma once
#includeclient.c:
#include"comm.h"
#includeserver.c
#include"comm.h"
#include结果:

注意:消息队列本身保证原子性。
初识原子性
原子性只有两种状态,一件事做了和没做。
例如生活当中的灯,灯要么是亮的,要么是暗的。
如果不是原子性的会造成什么问题呢?
如今天小红微信转账一万元给小明,微信程序得知后将小红的余额减去1万元,此时机器出问题了或者小明的微信注销了,导致小明的余额没有增加,而小红亏损了1万元。
即上述例子就不是原子性的。
初识信号量
信号量(灯)分为二元信号量和多元信号量。
之前如果学习过锁的就清楚,对于临界区的访问要加锁,那种情况资源只有一份(计数器的值是1),所以二元信号量也可以在这种情境下使用,也是符合互斥的语义。

如今天电影院当中有100个位置,我提前订票,相当于电影院在某个时间点有一个位置是我的,即使后面我不去,那个位置也会帮我留着。电影院的位置相当于一种资源,相当于100份,就能在同一时间点接受100个进程/线程来访问,但是如何保证第101个进程/线程不能在同一时间点来访问资源呢?
只要访问的资源不是通过一个,他们是可以支持并行访问的。
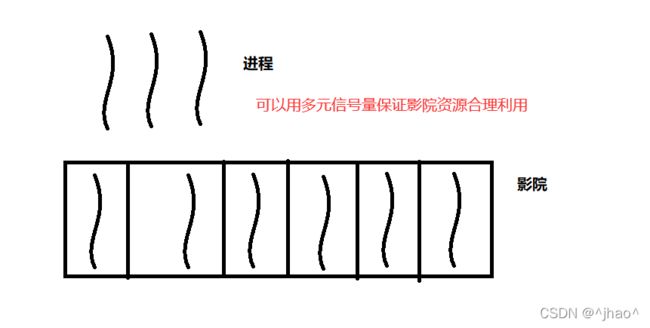
信号量本质是一个计数器,用来描述临界资源中,资源数目的计数器。
打个不恰当的比方,比如影院的是一个int count = 100;当有人预定票则count–,若有人退票或者消费完毕,则count++,释放信号量,而当count==0,则不允许进程再申请资源。但是由于count++的用法不是原子性的,导致信号量也是一种临界资源,并且多个进程无法操作一个count值,会发生写实拷贝,即使是malloc,也会有原子性的问题,有原子性的问题说明他自己也是临界资源,无法保护临界资源的安全性。所以信号量的实现并不是真的使用int count实现的。
每个进程都得先看到信号量,相当于大家都得先看到信号量,信号量本身就是一个临界资源。
申请资源叫P操作,释放资源叫V操作,也称之PV原语。
PV操作伪代码
int* count = (int*)malloc(sizeof(int));
*count = 3;
P:
begin:
Lock();
if(count <= 0){
goto begin;
}
else {
*count–;
}
Unlock();
V:访问资源
Lock();
唤醒相应等待队列s.queue中等待的⼀个进程
改变其状态为就绪态
并将其插⼊就绪队列
*count++;
UnLock();
五、信号量

System V中如何在多进程的环境下,保证信号量被多个进程看到?
5.1semget
nsems这里式信号量的个数,即多少个计数器,如要实现的是二元信号量,则填1即可;key 和 semflg和共享内存一样。
功能:⽤来创建和访问⼀个信号量集
原型
int semget(key_t key, int nsems, int semflg);
参数
key: 信号集的名字
nsems:信号集中信号量的个数
semflg: 由九个权限标志构成,它们的⽤法和创建⽂件时使⽤的mode模式标志是⼀样的
返回值:成功返回⼀个⾮负整数,即该信号集的标识码;失败返回-1
5.2semctl
1.semnum表示的是操作哪一个信号,从semget可以获取多个信号量,内核用数组组织,所以该位从0开始,二元信号量此处填0即可。
2.此处的函数为可变参数列表,由于我们semget创建了多个信号量,而对于每一个信号量的初始数值没有初始化,我们可以自定义联合体并将cmd设置为SETVAL,然后第四个参数填入自定义初始化好的联合体(下图有关于联合体的介绍)。
3.此处的semget当中的权限显得重要起来,之前那些地方的没用上,但这里如果权限没有设置,无法将这个联合体放到内核处。
否则会报出Segmentation fault!
功能:⽤于控制信号量集
原型
int semctl(int semid, int semnum, int cmd, …);
参数
semid:由semget返回的信号集标识码
semnum:信号集中信号量的序号
cmd:将要采取的动作(有三个可取值)
最后⼀个参数根据命令不同⽽不同
返回值:成功返回0;失败返回-1
semget的第二个参数创建一批信号量,内核用数组来维护的。
ipcs查看nsems就是信号量的个数。

/usr/include/bits/sem.h可以找到这个联合体相关的定义,可以看的出他有8字节(64位),能够将我们所需要设置的4种情况都由可变参数列表传入。只有信号量的*ctl函数是可变参数,这里是作为一种初始化的作用。

5.3semop
第三个参数对多少个信号量操作。
sops是自定义的结构体,结构体用来对已经创建初始化好的信息量进行操作,结构体的sem_num表示对哪个编号进行操作,sem_op则是我们初始信息量部分帮我们 预定电影票 的作用的,sem_flag则是信息量为空是阻塞还是立即返回的选择。
功能:⽤来创建和访问⼀个信号量集
原型
int semop(int semid, struct sembuf *sops, unsigned nsops);
参数
semid:是该信号量的标识码,也就是semget函数的返回值
sops:是个指向⼀个结构数值的指针
nsops:信号量的个数
返回值:成功返回0;失败返回-1
sem_num是信号量的编号。
sem_op是信号量⼀次PV操作时加减的数值,⼀般只会⽤到两个值:
⼀个是“-1”,也就是P操作,等待信号量变得可⽤;
另⼀个是“+1”,也就是我们的V操作,发出信号量已经变得可⽤
sem_flag的两个取值是IPC_NOWAIT或SEM_UNDO
进程间通信代码
comm.h
[ljh@VM-0-11-centos mypv]$ cat comm.h
#pragma once
#includeserver.c
#include"comm.h"
int main()
{
//申请信号量
key_t key = ftok(PATH_NAME, PROJ_ID);
int semid = semget(key, 1, IPC_CREAT | IPC_EXCL | 0644);
if (semid < 0)
{
perror("semid");
return 1;
}
union semun _un;
_un.val = 1;//表示有信号量有一份资源,即这里的是二元信号量
//对于已有的信号量做初始化
if (semctl(semid, 0, SETVAL, _un))
{
perror("semctl");
return 2;
}
//通过共享内存进行验证
key_t key2 = ftok(PATH_NAME2, PROJ_ID2);
//权限在shmctl的时候很有作用
int shmid = shmget(key2, BUF_SIZE, IPC_CREAT | IPC_EXCL | 0644);
char* ipc_ptr = (char*)shmat(shmid, NULL, 0);
*ipc_ptr = '\0';
while (1)
{
//访问资源前先上锁
struct sembuf s;
s.sem_flg = 0;//表示以什么方式拿取(阻塞)
s.sem_num = 0;//表示访问第一个
s.sem_op = -1;//表示对拿取一份资源
if (semop(semid, &s, 1) < 0)
{
perror("semop");
return 1;
}
//这里开始访问资源,看对端是否有发送数据
printf("%s\n", ipc_ptr);
sleep(1);
//访问资源结束
s.sem_op = 1;
semop(semid, &s, 1);
}
return 0;
}
client.c
#include"comm.h"
int main()
{
//申请信号量
key_t key = ftok(PATH_NAME, PROJ_ID);
int semid = semget(key, 1, IPC_CREAT);
if (semid < 0)
{
perror("semid");
return 1;
}
union semun _un;
_un.val = 1;
//对于已有的信号量做初始化
semctl(semid, 0, SETVAL, _un);
key_t key2 = ftok(PATH_NAME2, PROJ_ID2);
int shmid = shmget(key2, BUF_SIZE, 0);
char* ipc_ptr = (char*)shmat(shmid, NULL, 0);
int count = 5;//5次后退出,这里没什么意义,只是让client晚点退出
while (count--)
{
//访问资源前先上锁
struct sembuf s;
s.sem_flg = 0;//表示以什么方式拿取(阻塞)
s.sem_num = 0;//表示访问第一个
s.sem_op = -1;//表示对拿取一份资源
if (semop(semid, &s, 1) < 0)
{
perror("semop");
}
//这里开始访问资源
for (int i = 0; i < 26; ++i)
{
ipc_ptr[i] = 'a' + i;
sleep(1);
}
//访问资源结束
s.sem_op = 1;
semop(semid, &s, 1);
}
shmdt(ipc_ptr);
return 0;
}
结果
双方能够通过信号量实现同步了!!!

注意上面的ipc资源都需要手动释放!!
总结
!_!