(FCN)-Fully Convolutional Networks for Semantic Segmentation
文章目录
- Fully Convolutional Networks for Semantic Segmentation
-
- 摘要
- 全局信息和局部信息
- 感受野
- FCN算法架构
- 训练技巧
- 详细参考
Fully Convolutional Networks for Semantic Segmentation
摘要
卷积网络在计算机视觉领域是一个强有力的工具。我们证明了经过端到端、像素到像素训练的卷积网络超过了语义分割中最先进的技术。我们的核心思想是构建一个全卷积的网络可以输入一个任意的尺寸,经过有效的推理和学习过程产生相应尺寸的输出。我们定义和描述了全卷积网络的空间细节,解释了FCN网络在密集预测任务(dense prediction tasks)上的应用以及与先前模型的联系。我们改编了当前的分类网络(AlexNet、VGG、GoogLeNet)从全连接的方式为全卷积的方式并且通过微调的手段把它们的学习表现传递到分割任务中。我们定义了跳跃连接,其结合了深层的语义信息和来自浅层的表征信息来更准确和精细的进行分割。我们的FCN网络在PASCAL VOC、NYUDv2和SIFT Flow上达到了state-of-the-art的结果,同时对一个典型的图像推理只需要花费不到0.2秒的时间。
全局信息和局部信息

来看这幅图,左边输入原始图像后经过了三个下采样块(FCN中共有五次下采样,每个块之间的尺寸关系是二倍的关系),当经过前一个或两个下采样块的时候(如上图中第一个采样块所指的图像)这一部分叫浅层网络,这时拿到的图像信息是比较丰富和细致的,这些从浅层网络中提取到的信息就是局部信息。而随着网络的深入,等到后边的采样块的时候,这时就到了深层网络,图像的信息基本都被破坏,只剩下了计算机能够识别的高级特征。这时的空间信息比较丰富,这就是全局信息。对于局部信息而言,其感受野较小,有助于分割尺寸较小的目标,而全局信息的感受野较大,有助于分割尺寸较大的目标,有利于提高分割的精确程度。
在语义分割中存在的一个问题就是局部信息和全局信息内部相矛盾。其矛盾在于随着下采样的深入,局部信息全部产生在前边的特征图当中,最后得到的输出一定是全局信息,也就是说所有的局部信息都被处理当做了全局信息。那么就意味着如果不对先前的局部信息进行保留的话就会在后边的采样中丢失、破坏。对应的解决方式就是跳跃结构完成特征融合,来共同提高的分割的精度。
感受野
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小被称为感受野。通常来说,大感受野的效果要比小感受野的效果更好。
RFl+1=RFl+(kernel_size-1)×stride为计算感受野大小的公式,RFl表示第l层的感受野。由公式可见,感受野是一个相对的概念,即下面一层的感受野大小是和上一层有联系的,并不是一个绝对的数值,并且stride越大感受野也就越大。所以在深度学习中,按照惯例所有的感受野大小都是相对于原始图像而言的。
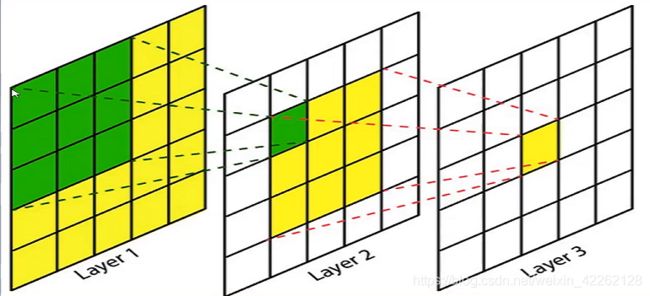
拿上图举例来说,如果输入是一个5×5的图像,采用3×3的过滤器来进行卷积,卷积后得到了Layer2中的绿色元素点,那么这个绿色元素点的感受野大小就是3。通过公式计算在Layer3中黄色元素点的感受野是5,即原始输入图像的大小。这是因为在Layer2中每个元素点对应原始图像的3×3的区域,在Layer2上应用一个3×3的过滤器最后得到了Layer3上的黄色元素点。那么这个元素点对应在Layer2上的区域是3×3的,而这个3×3的每个点都会对应到原始图像上,所有的点对应回去后就是原始图像本身。所以Layer3上黄色元素的点的感受野大小就是5了。
前文提到说stride越大,感受野也就越大。但是过大的stride会使feature map保留的信息变少,因此在减小stride的情况下,如何增大感受野或使其保持不变,成为了分割中的一大问题。
FCN算法架构

对于原始输入图像image,每经过一个卷积块和一个池化层,会得到一个feature map,并且每一次经过池化后图像尺寸变为了前一层的1/2。所以在FCN网络中经过了5次下采样,尺寸缩小为原始输入图像的1/32。在第六次和第七次卷积后,就没有再改变图像的尺寸了。但是从上图中可以发现,最后的输出,即32x upsampled prediction是和原始图像大小相等的,这是由于加入了一个反卷积的操作。
模型图右侧分别有三个结果图,32x/16x/8x upsampled prediction,这是什么意思呢?在经过conv6-7后,图像是原始输入图像大小的1/32,通过一步反卷积直接还原32倍得到了最终的FCN-32s。这种操作在实际应用中是不好的,通常上采样和下采样会采用同样的比例,因为如果还原的比例跨度太大总是得不到理想的输出的。这里之所以这样做是为了证明跳跃连接在FCN中是有作用的,这在后边会有详述。
将conv6-7换为2x conv7即二倍反卷积,再结合pool4做一个融合,即跳跃连接。pool4得到的feature map为原始图像的1/16,这样由于在匹配时要求数据的维度是相同的,所以要对1/32的图像做二倍反卷积的还原,这样数据大小一致就可以融合了,再用16倍上采样最后得到了16x upsampled prediction。同理对于FCN-8s,要对conv7进行4倍的反卷积,pool4进行2倍的还原,才能与pool3的大小保持一致,进行三个特征图的特征融合,得到了1/8的预测输出。这样对比三种还原操作还是FCN-8s是最柔和最精细的。
整个过程是非常简单的,前边的下采样都是根据定义好的VGG网络来完成的,再加入ImageNet上的预训练权重加入到网络中,最后结合反卷积还原完成了网络的构建。
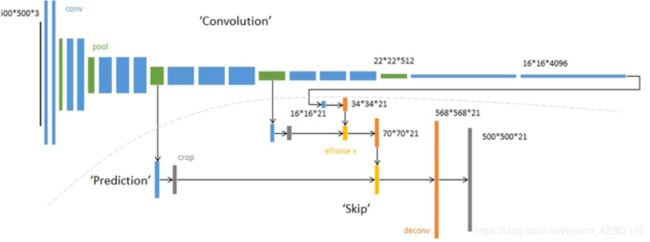
如图所示就是一个比较详细的FCN-8s架构。对于一个500×500×3的输入,经过一层层的卷积和池化(蓝色代表卷积、绿色代表池化)和两个6-7层的卷积后得到16×16×4096大小的特征图。将其拿出先做一个1×1的卷积,将通道改变为21,然后反卷积还原,扩大为34×34×21。这时与pool4的特征图裁剪相同尺寸后相加融合,再扩大尺寸为70×70×21。再与pool3的特征图匹配相加融合8倍反卷积,最终裁剪为与输入图像尺寸相等的特征图。这样就达到了端到端同尺寸输入输出的目的。
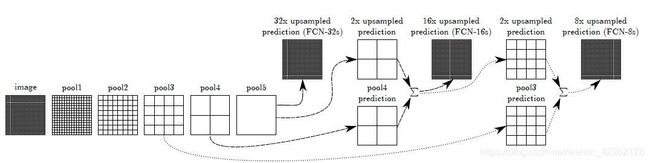
在论文的第二版中,对上述的架构图进行修改优化,省略掉了卷积层,直接以池化的形式给出逐个步骤。然后对于每一次的相加融合以及反卷积还原有了更加直观的解释。
训练技巧
1)加载预训练模型:文章中反复提到模型会加载经典算法的预训练模型。
2)初始化反卷积参数:使用线性插值的方式,对反卷积的卷积核进行初始化,这样做的目的是为了让其更快的收敛,若是不这样做收敛速度很慢或是出现根本就不收敛的情况。intermediate upsampling layers are initialized to bilinear upsampling, and then learned.
3)至少175个epoch后算法才会有不错的表现:文章作者进行了大量实验,最后得出这一经验性的总结。所以在实验中要进行接近200次的循环才能等到一个可以接受的结果,在之前loss下降的不快或者是算法结果提升的不够高都属于一个正常的现象。We report the best results achieved after convergence at a fixed learning rate (at least 175 epochs).
4)学习率在100次后进行调整:调整学习率是一个很常见的优化手段,这一手段不局限于多少个epoch之后调整,只是说越到后边学习率要调整的越小,这样才不会错过loss 的全局最小值。The learning rate is decreased by a factor of 100.
5)pool3之前的特征图不需要融合:之所以不用pool1和pool2,在论文中解释为通过实验证实了加到pool1和pool2后对实验的模型有一个负优化的作用,负优化后的结果不是很明显但对结果的提升可以说是微乎其微的。那么不再引入这两层就可以避免再次引入大量的参数,避免对FCN整体的效率产生影响。At this point our fusion improvements have met diminishing returns, both with respect to the IU metric which emphasizes large-scale correctness, and also in terms of the improvement visible e.g. in Figure 4, so we do not continue fusing even lower layers.
详细参考
详细参考:FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)