杨志丰:一文详解,什么是单机分布式一体化?
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/

3 月 25 日,第一届 OceanBase 开发者大会在北京举行,OceanBase 首席架构师杨志丰(花名:竹翁)带来了 《OceanBase 的单机分布式一体化》 的分享,为大家介绍了单机分布式一体化架构的概念及思考,以及对业务的价值。
以下为演讲实录:
今天我的演讲主题是《OceanBase 的单机分布式一体化》,主要来解释 OceanBase 为什么要做单机分布式一体化,我将从以下 3 个方面进行今天的分享:
首先,单机分布式一体化是什么?
其次,单机部署时如何获得与单机数据库相当的性能?
最后,分布式部署时如何实现高性能低时延?
什么是单机分布式一体化?
每个人听到“单机分布式一体化”可能都会有自己不同的理解,也会有很多疑问,事实上,单机分布式一体化不是 OceanBase 突然冒出来的概念,而是基于三方面的原因。
第一,产品迭代。 OceanBase 从 2010 年开始自研,在走出蚂蚁集团开始服务金融行业,到现在走到云上去服务更多互联网行业客户的过程中,基于客户的反馈,我们的产品不断在演变、完善。
第二,硬件趋势的不断发展。 OceanBase 在 1.0 最初设计的时候,当时我们在蚂蚁集团的内部集群,用的机器都是普通 16 核的机器,后面随着硬件技术的发展,我们的主流机器都在 96 核以上,服务器单机的性能有了极大的提升。
第三,云技术的发展。 近几年,云技术发展突飞猛进,OceanBase 刚刚创立之初,云技术刚刚兴起,而现在云基础设施触手可得。技术的发展伴随着 OceanBase 架构的发展,OceanBase 的技术经历了三个大的版本迭代。
▋ 从 0.1 到 4.0,OceanBase 的发展历程
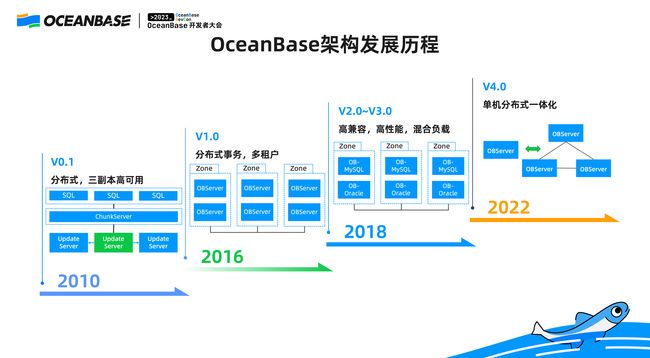
第一个版本是 0.5 版本,虽然是十几年前的版本,但其实它已经完全是分布式的架构,在当时,OceanBase 把 SQL 层和存储引擎做了分离,上面是一组 SQL 无状态服务,下面是由 ChunkServer 和 UpdateServer 组成的存储集群,对外暴露的就是表的 API。当时由于我们刚刚开始去做数据库的实现,所以我们做了一些限制——没有多点写入,所以当时实际上是不支持分布式事务的。
当 OceanBase 从 0.5 往 1.0 演进的时候,我们有一个深刻的感受:传统单机数据库采用紧耦合的设计,存储和计算放在一起,后来因为有了 NoSQL,很多人觉得是不是应该把存储层单独隔离开,OceanBase 在零点几版本的时候就遵循这样的设计思路,所以我们做了分离,但分离以后带来非常大的问题。
这个问题在于做 NoSQL 还可以,但是要做关系型数据库并没有那么简单,如果你对时延有要求的话,松耦合的方式会导致效率上有很大开销。所以 OceanBase 从 1.0 开始,我们就在重新思考这个问题—— 把存储事务 SQL 做成紧耦合的架构,即全分布式架构,将原来的三个 Server 合成一个 OBServer 的节点,同时处理存储事务 SQL,同时我们将高可用的粒度,由原来机器级别的高可用粒度,切分成若干个 Zone, 这些都得益于我们在蚂蚁集团的场景实践。
当 OceanBase 发展到 2.0 版本时,OceanBase 从蚂蚁集团走向了外部客户,在这个过程中客户反馈说:“OceanBase 只支持 MySQL,是很好,但我们这里面有很多的 legacy(遗留) 系统是不可能把它完全的改成用 MySQL 或者用开源的方式去做的”,所以 OceanBase 在 2.0 的时候引入了重要的特性,在多租户的能力之上又兼容了 Oracle,但它的整体架构和 1.0 是一样的,在 4.0 版本时,我们就进入了全新的单机分布式一体化的阶段。
▋ 单机分布式一体化的三个含义
现在,我来正式定义一下 OceanBase 单机分布式一体化到底是什么,单机分布式一体化有三个层面的含义。

第一个层面,OceanBase 以一个程序的形式存在,既可以在单机的形式下部署,也可以做成多机部署。 这个并不是非常容易做到的事情,只有我们把单机分布式一体化作为一个目标,才能去实现这样的形态。
第二个层面,我们所谓的单机分布式一体化,其实有一个租户的概念。 即使你部署了一个分布式的 OceanBase 集群,但是里面的某一个租户如果在单机上,我们也认为这是一种单机的形态。
第三个层面,单机分布式可动态转换。 在两种形态之间,OceanBase 可以随意切换,可以灵活地做动态的调整,单机可以变成分布式,分布式可以变成单机,同样在租户层面和集群层面都可以做到。
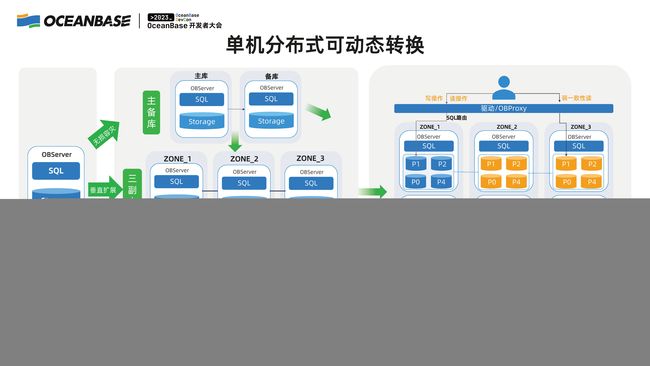
虽然也会有其他方面的很多挑战,但切换的最大挑战显然是关于性能的,所以接下来我将分享 OceanBase 怎么做到在单机分布式一体化架构下面,在单机部署的时候可以做到单机数据库相当,在分布式部署的时候我们在保证可扩展性的同时,又可以做到比其他的分布式数据库更高的性能和更低的时延。
▋ 单机分布式一体化,匹配企业不同发展阶段
首先看业务的价值,对于很多企业来说他是有一个从小到大的过程,或者说在大企业内部有个小的业务,业务都是从小开始变大,有一天可能某个业务突然冒出来,但最初的时候其实并不需要那么多的资源,我们希望用户既可以享受到分布式数据库带来的优势,使用起来又不存在非常多的困难,可以一个数据库解决企业多个不同发展阶段的需求。
OceanBase 正式支持单机形态部署。如果你对读写分离有要求,你可以使用 OceanBase 主备库的能力,就像传统的 MySQL 的主备库一样,没有任何的区别;如果你觉得 MySQL 的主备库在切换的时候会产生丢数据的问题,特别是远程容灾的时候,可以从主备库动态的升级到 OceanBase 三副本模式;如果你觉得高可用、三副本的模式不能在现阶段掌握,或者对你来说不是很关键,那么 OceanBase 其实具有非常强的单机模式下 scale-up 垂直扩展的能力,所以我们并不是做分布式数据库就不管单机的性能。
当企业或者业务发展到大规模场景的时候,有非常多的问题要考虑。比如,业务特别多,在蚂蚁集团内部,大家可以想象有非常多的业务、甚至有上万台的机器在使用 OceanBase,这个时候如果你只有 10 人的 DBA 团队,你怎么去管理一万个 MySQL,这是非常大的挑战,所以我们的多租户和整个分布式的架构,使得我们可以把集群的数目控制在一个合理范围之内,在每个集群内部有很多自动化运维的手段,让我们的 DBA 真的可以安稳的睡一个好觉,此时有很多非功能性的需求就提出来了。
比如,分布式数据库是很好,但是我可能在当前这个阶段并不需要。但是我想说“有了 OceanBase 的单机分布式一体化架构,大家不会有担心,你可以在你需要的时候选择你所需要的特性”。反过来说,如果我引入了分布式数据库,同时给你搭售了三副本和很多其他你不需要的能力,那不是我们所希望的,这也是我们单机数据库核心的价值。
单机部署时如何获得与单机数据库相当的性能
▋ 过度分层设计虽然简化了实现,但牺牲了性能
反过来想这个问题,如果我有一个分布式的数据库,左侧是其他的分布式数据库的典型形态,将存储节点和计算节点做一个分离,他们之间通过网络进行通讯,这样的话是可以各自做拓展的。分布式数据库当然不是仅分片那么简单,数据库很重要的是事务处理的中心节点,数据库要保证数据全局的一致性和原子性,所以很多数据库会引入这样一个全局事务管理器的模块。

OceanBase 也有类似的模块,我们叫全局时间戳服务,功能都是类似的,像上边的右图一样,将三个节点装到一台单机上。
很多人说这样的“单机分布式一体化”我们也可以,但这里面是有非常多开销的,因为分布式处理所涉及的很多协议,对于单机来说都是开销,各个组件之间,如果你通过 RPC 做通讯,会产生非常多额外的开销,另外 RPC 协议是需要专门去设计的,所以在设计这种通讯协议的时候,不能像函数调用一样,可以尽量灵活的做很多快捷的处理。
此外,还有一层隐藏的含义,就是从我们从事数据库研发的视角来说,如果你以分布式作为开头,你在实际实现过程中不会去想单机是什么情况,这个是大家可以理解的。
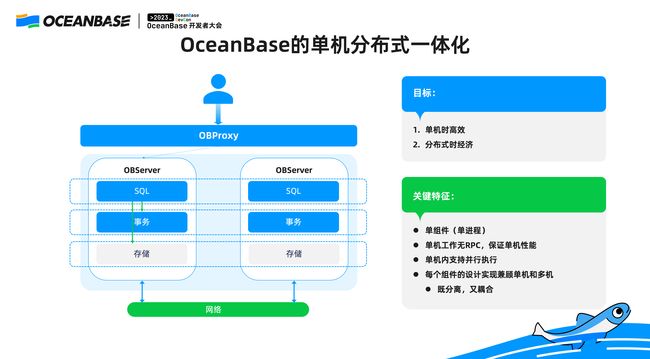
▋ OceanBase 的单机分布式一体化
我们看一下 OceanBase 单机分布式一体化整体的架构,说起来非常简单: 每一台机器都具有自己独立的 SQL 存储事务的模块,在单机之内,SQL 存储事务之间直接通过函数调用,和单机没有任何区别;在机器和机器之间通过网络去做通讯。
上图中的架构有几个特征:第一,每个节点单进程,OceanBase 没有那么多角色区分,整个 SQL 事务存储是在单个进程内共享内存的;第二,单机内工作是没有 RPC 的,并且对于单机数据库来说,为了提升垂直的扩展性,OceanBase 还支持单机内并行,在更深层次上,每个组件的设计,OceanBase 都会兼顾单机和分布式。
在这样的设计里面,我们每一个功能的设计都要考虑在单机内怎么样做最好,分布式时怎么做最好,所以我们的设计都会有这样两个维度。
首先看单机的两个含义,第一,每个 Zone 里面一个OBServer,所以即使一个 Zone 里面有很多个资源的单元,即 Unit,如果你的租户是单个 Unit,就等于这里所讲的单机。
为了提升单机内垂直的扩展性,OceanBase 在 SQL 引擎、事务引擎、存储引擎都会做到极致的优化:第一,单机内可以并行;第二,在事务引擎里,我们在做事务的高并发处理的时会做组提交的技术。同样在存储引擎里面,我们的存储引擎属于准内存的存储引擎,写入的时候只需要放到内存里就可以了,并不需要像传统的 B+ 树一样,把它写到数据块里。单机内同样在 IO 层面支持很多并行。
你会看到早期的 MySQL 给他一个 96 核的集群,想把 CPU 跑满,是不可能的,这就是垂直扩展性的表现。
▋ OceanBase 4.0 VS MySQL 8.0

上图是 OceanBase 4.0 和 MySQL 8.0 的性能对比,在六种场景下,OceanBase 4.0 和 MySQL 8.0 的性能都是相当的。

上图是我们垂直扩展性的试验,同样在 Sysbench 的六种负载场景下, 从 4 核到 64 核的机器,大家都可以看到 OceanBase 具有非常好的垂直扩展性,多给一倍的核数,OceanBase 的性能就提升一倍。
分布式部署时如何实现高性能低时延
对于 OLTP 业务来说,大家用分布式数据库很担心时延的指标,那么单个操作的时延指标是不是能像单机数据库一样呢?这是 OceanBase 着力在优化的点。基本原因就是:无论你在怎么样的数据中心,做一次 RPC 就需要 0.5 毫秒,这个时间不可忽略。
▋ 分布式性能需要高性能低时延
下图是在某个特定的负载下面,随着分布式事务比例的增加,单机数据库和两种分布式数据库的性能表现,绿色是单机数据库。
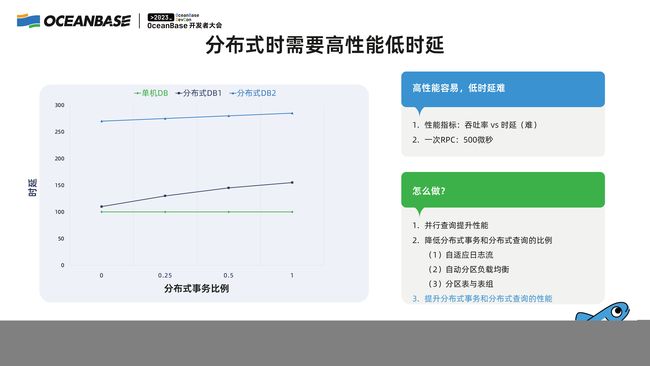
随着某种分布式事务的增加,对于比如 TPC-C 来说,即跨 warehouse 交易的增加,和单机数据没有什么差别。如果有两种数据库, OceanBase 的设计目标是变成下面 DB1 的性能曲线,随着分布式事务增加,肯定有开销,但当我还没有分布式事务的时候,DB2 的性能就比 MySQL 差非常多,这不是我们想设计的分布式数据库。
此时有两种方式可以做到,第一就是降低分布式事务和分布式查询的这个比例,正如 CTO 杨传辉所说: “实际上对于很多在线型的交易,全局性的事务,他的比例往往并没有大家想的那么多。在典型的 TPC-C 场景下,TPC-C 里跨 warehouse 的交易查询只有10%” (可移步阅读《OceanBase CTO杨传辉:万字解读,打造开发者友好的分布式数据库》)。做在线交易的时候,DBA 同学很清楚自己的业务,并不是所有的东西都要付出分布式的开销,为了能够达到这样的效果,我们做了很多的工作,其中最主要的就是 4.0 里面自适应的日志流。
OceanBase 做了很多自适应的策略,去自动化的根据表的设计去做自动的负载均衡,自动的做数据排布减少分布式事务和分布式查询的比例,如果这些自动化的措施都达不到这个目标,用户同样可以用我们提供的分区表和表组的功能自己去控制、降低分布式事务。
如果以上的要求都做不到怎么办呢?我们就必须硬碰硬地降低分布式事务和分布式查询整个的开销,这块 OceanBase 有很多独特的设计。
▋ OceanBase 分布式为何能高效经济?
回到单机分布式一体化架构,在这个架构下面我们看看分布式场景下它是怎么工作的。
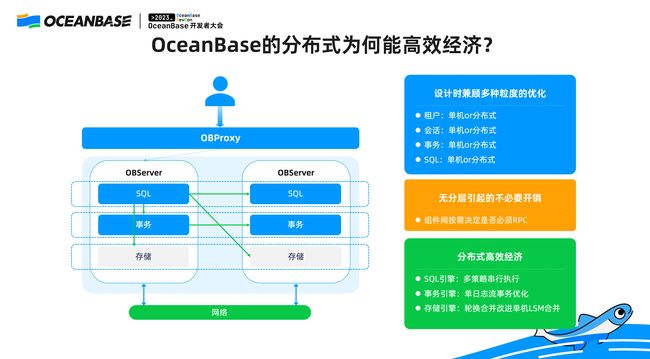
对于上面这种分层的设计来说,如果 SQL 层、存储层、事务层是分层的设计,无论自己怎么操作,这个 SQL 和本地的事务之间是没有感知的,所有的东西都是全局的,本地的交易数据还是远程的交易数据对于 SQL 层都没有差别。OceanBase 不是这样,我们显式的就区分了这两者的区别,所以 OceanBase 的 SQL 层可以直接访问到另外一台机器的存储层。如果需要访问另外一台机器存储层的时候我做 RPC,如果我访问的存储是在本地,就不需要做 RPC。
整体设计的时候有几个不同的粒度,本质上设计时我们做得更加精细化,精细化是说单机分布式并不是简单的概念,而是多个粒度的单机,在我们看起来有四个基本的粒度:
第一,租户。 是分布式的租户还是单机的租户。
第二,会话。 OceanBase 会通过 Proxy 路由协议使得在很多其他数据库里面分布式的做一件事情,在 OceanBase 会变成单机的事情。最典型的就是我们会根据这条 SQL 的特征,把它路由到存储所在的节点上,这样即使整体上看起来好像是分布式,但是对于那条 SQL 的执行,它就变成本地执行。
第三,事务。 在事务层面上,OceanBase 如果在单个事务内只操作一个日志流内的分区,分布式事务提交的协议和单机的协议也是有区别的。
第四,SQL。 如果是一个单机的 SQL 执行和需要远程访问 SQL 的执行,我们有两种独立的执行路径。在此基础之上,为了使分布式的执行更加高效,我们整个 SQL 引擎在 OLTP 上面做串行执行的时候会有自适应的策略。
我们的设计从来都是一个整体,对于 LSM-Tree 来说,合并是非常消耗资源的后台任务,但是如果在分布式的部署场景下,我们发明了一种聪明的方法: 使得每台机器的合并和它的服务可以错开,我们称之为“轮转合并”,就是如果一个副本在提供服务就先不合并,我让 follower 副本去做合并,这样使得后台的 LSM-Tree 合并对于前台的操作在这台机器上没有影响。
▋ 单机分布式自适应的执行引擎如何提升分布式查询性能
如果我没有办法优化业务来减少分布式 SQL,对于分布式 SQL 这部分我怎么去执行?OceanBase 整体的 SQL 自适应执行引擎,分为串行执行和并行执行。
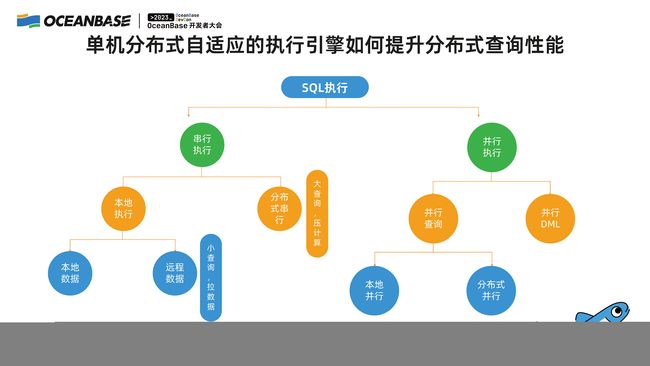
并行执行可以在单机内并行,这一点相对于一些开源的单机数据库是有优势的,早期的 MySQL 版本单机内并行是没法做到的,又可以利用多机,如果一台机器 CPU 还不够,我可以把整个集群的 CPU 用起来去做并行执行。串行执行我们就显式地去区分了,它到底是一个大数据量的访问,还是一个小数据量的访问。
如果是一个小数据量的访问,我们会把数据拉到本机来执行;如果是一个大数据量访问,我们会把整个 SQL 的执行计划下压到那台机器上去做数据过滤,整个过程是优化器自适应去选择的。
▋ 兼顾单机和分布式的事务处理协议以提升事务性能
最后,事务是非常难做分布式优化的,OceanBase 在事务引擎方面有非常多的创新的专利。在这里我介绍两个点,下图是分布式事务执行提交的流程,事务从整体上来看分成 “事务开启”和“事务提交” 两个关键操作。
第一,在“事务开启”的阶段,左侧是其他的分布式数据库典型的两阶段提交的过程。在开启事务的时候,为了实现多版本的隔离,读和写互相不影响,在 MVCC 的场景下,它需要获得一个全局的快照——即当前哪些事务在操作,哪些事务已经提交了快照,对于很多分布式数据库来说,这个快照的操作是非常大的开销。
而 OceanBase 在这个阶段做了优化,我们在很多场景下,OceanBase不需要访问全局的时间戳服务。我们创新地实现了一些对于 GTS 服务的优化,使得这部分的开销是可扩展的。证明就是 TPC-C 测试,TPC-C 有 1500 个节点,1500 台机器每秒处理 2000 多万次事务(是事务并不是 SQL),但只有一个 GTS 服务节点,看起来好像这个 GTS 不容易扩展的,实际上我们优化后变得很容易扩展。
第二,在“事务提交”的阶段, 对于提交的协议来说,大家可以看到左侧两阶段的提交协议,传统的两阶段提交协议需要写四个阶段的日志,在参与者上要写事务的日志,在协调者上也需要记录日志,使得两阶段提交在容灾的场景上是安全的。
OceanBase 在两阶段提交上做了一个非常创新的设计,OceanBase 的参与者是三副本、高可用的,所以并不担心协调者的节点数据丢失,所以我们在参与者上不记日志,这样就节省了两条日志。第二,我们会在第一个阶段就给应用返回成功,这是我们非常独特的一个优化,使得整体的 roundtrip 少了一次。所以整体来说,即使在分布式事务场景下面,OceanBase 的分布事务比其他的分布式数据库有很大的优势。

最后附上 OceanBase 与市场上几款常见的分布式数据库在 Sysbench 500 线程下的性能对比,这也就是全分布式场景下 “OceanBase 的低时延是什么” 的最好呈现,我的分享就到这里,谢谢大家!
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/