看图说容器
前言
关于容器,Docker有两句深入人心的宣传口号:
- 第一句:Build, Ship and Run
- 第二句:Build once, Run anywhere
两句简洁又直抵人心的口号直接戳中软件开发和运维人员的痛点。我们下面利用一些图片来帮助我们更好地理解容器。
容器的本质

如上图蓝色的鲸鱼驼着许多集装箱所直观表达的信息: 集装箱里装着我们需要的物品,大家并不关注箱子怎么样,是由哪条鲸鱼运送到哪里,只要保证货物平安运送到目的地,打开箱子货物完好就可以啦。由于箱子按一定标准设计,并可以层层重叠,各个箱子里的货物互不打扰。所以可以大量放置在鲸鱼的背上运输送到世界各地。同样的道理,对于软件来说,容器技术就是将每个应用及其所有依赖都封装到一个容器内,部署到目标机器上,运行在任何支持容器运行时的环境里,多个容器相互之间隔离,互不可见,共享 Host的资源。具体到容器的使用过程就是:
- Build:就是装箱过程,提供打包的方法,把应用程序及其依赖环境封装到一个镜像中。
- ship: 就是交付,部署。
- Run: 在任意支持容器运行时的环境中运行。
所以容器的本质就是: 环境的封装,空间的隔离,资源的共享。下面我们继续看看它们分别是用什么技术实现的。
容器的关键技术
封装

容器将应用程序及其所依赖的环境打包所依赖的是UnionFS(联合文件系统)。它是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。

当容器基于镜像启动时,会有一个新的可写层被加载到镜像的顶部,这一层通常被称为容器层。所有对容器的修改都会发生在容器层,只有容器层是可写入的,容器层以下的镜像层都是只读的。
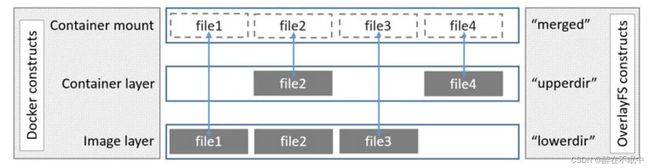
如上图所示,当我们对容器进行操作时,底层的工作原理如下:
- 读取文件:当容器需要读取文件时,会先在容器层寻找,如果没有发现,则会从最上层的镜像层往下寻找,当找到文件后读取到内存使用。
- 增加文件:当增加文件时,文件会直接写到最上面容器层,不会影响到镜像层内容。所以,当我们将容器删除时,容器中的文件也会随着消失。
- 修改文件:此时,如果该文件是在容器层的,则会直接修改。否则的话,Docker会从上往下依次在各层镜像中查找此文件,当找到后将其复制到容器层中,并进行修改。这被称为容器的写时复制特性(Copy-on-Write),这个技术保证了我们对容器的修改不会影响到底层的镜像,也实现了一个镜像可以被多个容器共用。
- 删除文件:当我们需要删除文件时,Docker也是由上往下寻找该文件,如果在容器层的文件会被直接删除,而在镜像层的文件则会被标记,此时在容器将不会再出现此文件,但镜像中的文件并不会做更改。
运行态的镜像叫做容器,我们可以在里面做一些修改,添加,删除等操作。做完操作之后,如果你觉得这是一个很好的模板,希望下次可以直接拿来使用,可以将当前容器创建一个镜像出来,下次要使用的时候直接作为基础镜像使用即可。
隔离
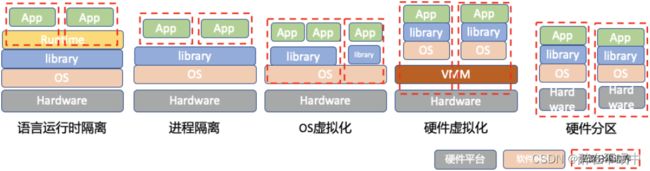
当前的资源隔离技术大致可以分成上图5类,由图可见,这些隔离技术的隔离程度是不一样的。容器的隔离属于OS虚拟化这条技术路线。
容器技术需要解决的核心问题之一运行时的环境隔离,它的目标是给容器构造一个无差别的运行时环境,用以在任意时间、任意位置运行容器镜像。
容器通过NameSpace的方式实现容器进程资源的隔离。

如上图所示,通过Namespace,每个容器都拥有自己独立的资源视图。PID,IPC,Network等系统资源不再是全局性的,而是属于某个特定的Namespace。每个namespace下的资源对于其他namespace下的资源都是透明,不可见的。
从另外一个角度也可以说容器隔离技术解决的是资源供给问题,它可以把一个大的服务器资源切分为小的分区使用。
实现容器隔离技术的组件叫做容器运行时。
资源的限制

一台物理机上的资源总是有限的,更高效、合理地分配资源对于负载和成本都具有重要的意义。容器通过Cgroup技术实现对 cpu、内存以及IO等资源实现精细化的控制,限制容器进程能够的资源使用。
上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 该 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 第二个 cgroups 层级结构 attach 了 memory 子系统,该cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。
最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
交付部署
单机部署

实现容器的单机交付部署,需要一系列的工具。上图以Docker为例,基于前面所述的命名空间隔离和资源限制技术之上,Docker提供了容器运行所需要的运行时环境。再往上,通过Docker daemon,提供对镜像、容器、网络和存储卷的统一管理,接受用户通过命令行(CLI)程序发送过来的命令。通过Registry提供上传、下载、发现各种各样的镜像的能力。
集群管理

现在的互联网应用都非常的复杂、庞大。不同于单点嵌入式环境,仅需要提供单一的、固定的服务。在互联网环境,需要的是多样化、多变的、高并发、基于大数据的大规模服务。对于服务的用户,也不在意这些服务是由什么位置或由哪一台机器提供的。所以这些服务往往都是分布式的,部署在很多分布式节点,服务已经集群化。一个大的服务框架需要将这些分布式节点的资源池化,提供动态的编排调度服务。比如这么一个场景:某个时刻A服务在1节点,B服务在2节点,后面A服务和B服务的业务量没那么大,访问量下来了,那么就可以让A服务和B服务都跑在1节点上,这样就节省了2节点的资源。通过编排调度服务,使得服务的规模能够依据业务的需求进行伸缩、扩展、负载均衡。还有灾备,故障迁移的能力以保证服务的高可用性。另外所有的服务可能面临持续的变更、升级,这种管理工作也需要有编排调度引擎帮忙完成。
于是就涌现出了众多类似Kubernetes这样的容器编排引擎。如上图所示,在每个物理的Node节点都部署了Kubelet接收来自K8s Master节点的命令,负责管理本地的容器资源,用户可以通过Kubectl客户端访问K8s Master提供的编排调度服务,也能通过其提供的仪表盘监视集群内容器的运行状况。
容器带来的变革

容器可以以各种粒度打包各种服务:Web service(比如nodeJS), 数据库(比如MySQL、mongoDB),负载均衡(比如NGINX),中间件(比如redis)等,还可以是邮件服务、存储服务、AI识别服务等等,还可以小到FAAS(Function as a Service)等等,都成了容器打包的对象。
容器可以部署到各种环境:公有云(Amazon、Windows Azure)、私有云(vmware、openstack搭建);云端、边缘、终端;物理机、虚拟机。只需要有运行时环境的支持,可以随处部署,不再受限于物理的限制,从而可以实现迁移、根据业务需要弹性伸缩。
基于容器的能力,引发了一系列的变革,比如:
- 封装程度的变革:serverless(Faas)(参考:Serverless简介)、SaaS(参考:干货:什么是SaaS?)
- 开发模式的变革:DevOps(参考:什么是DevOps?)
- 应用架构的变革:声明式API(参考:声明式API)、serverless (参考:Serverless简介)、服务网格(参考:快速掌握服务网格系列一:什么是服务网格(Service Mesh))、微服务(参考:微服务和容器)、云原生(参考:云原生五大技术)
- 运维模式的变革:不可变基础设施 (参考:下一个趋势,可能就是Immutable Infrastructure)
拥抱容器,拥抱未来!