论文笔记:Label Verbalization and Entailment for Effective Zero and Few-Shot Relation Extraction

论文来源:EMNLP 2021
论文地址:Label Verbalization and Entailment for Effective Zero and Few-Shot Relation Extraction (aclanthology.org) https://aclanthology.org/2021.emnlp-main.92.pdf
https://aclanthology.org/2021.emnlp-main.92.pdf
论文代码:GitHub - osainz59/Ask2Transformers: A Framework for Textual Entailment based Zero Shot text classificationhttps://github.com/osainz59/Ask2Transformers
引用:
Sainz O, de Lacalle O L, Labaka G, et al. Label Verbalization and Entailment for Effective Zero and Few-Shot Relation Extraction[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 1199-1212.
小知识——什么是文本蕴含
文本蕴含关系,简单来说描述的是两个文本之间的推理关系,其中一个文本作为前提(premise),另一个文本作为假设(hypothesis),如果根据前提P能够推理得出假设H,那么就说P蕴含H,记做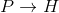 。这跟一阶逻辑中的蕴含关系是类似的。
。这跟一阶逻辑中的蕴含关系是类似的。
文本蕴含就是判断后一句话(假设句)能否从前一句话(前提句)中推断出来
Abstract
关系抽取系统需要大量的标注实例,标注成本很高。在这项工作中,本文将关系抽取重新定义为蕴含任务,使用简单的手工构建的关系表达器,在不到15分钟的时间内生成每个关系。该系统依赖于预训练的文本蕴含引擎。(个人认为这篇论文的摘要其实写的不太好,并没有对自己的方法进行概括,看完摘要之后还是不清楚本文的实际做法)
Introduction
对于小样本或者零样本任务,基于提示学习的方法提出了手工构建或自动学习任务和标签表达器作为微调预训练语言模型的替代。在这些方法中,提示和实例被一起输入到语言模型,并使用语言模型目标进行学习和推理。另一方面,一些作者将目标任务(如文档分类)重新定义为枢纽任务(通常是问答或者文本蕴含),这允许使用现成的问答训练数据。在所有情况下,基本思想都是将目标任务转换为一个公式,使我们能够利用预训练语言模型或通用问答或蕴含引擎中隐含的知识。(常用方法)
当标签表达器是由一两个单词给出时(如文本分类),基于提示的方法非常有效,主要是因为他们可以很容易的由语言模型预测,但在标签需要更详细的描述时,如关系抽取,本文建议将关系抽取重新表述为蕴含问题,其中关系标签表达器被用于生成由现成的蕴含引擎确定的假设。(本文思想)
本文为给定的一组关系手动构建语言模板。考虑到一些表述可能是模糊的(如city of birth和country of birth),本文用实体类型约束来补充它们,为了确保所涉及的手工工作在实际应用中是有限的和实际的,每个关系最多15分钟的手工工作。对于零样本RE,表达器是按原样使用的,但本文也将标记的RE实例改写为蕴含对,并微调小样本RE的蕴含引擎。(本文方法)
Entailment for RE
Zero-shot relation extraction
本文将RE重新表述为蕴含任务:给定包含两个实体的输入文本作为前提,并将关系的表达器描述作为假设,该任务是根据自然语言推理(NLI)模型推断前提是否包含假设。Figure 1展示了该系统的3个主要步骤。
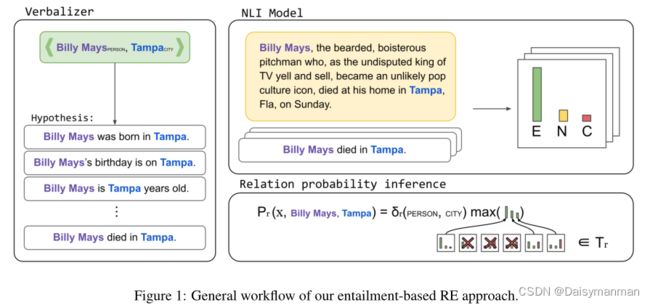
第一步侧重于关系表达器,以生成假设集合;第二步运行自然语言推理模型并为每个假设生成蕴含概率;最后一步基于概率和实体类型,返回使假设最大化的关系标签,包括NO-RELATION标签。
Verbalizing relations as hypothesis(关系描述为假设)
假设是使用一组模板自动生成的,每个模板都描述了两个实体提及之间的关系。例如,关系PER:DATA_OF_BIRTH可以用如下模板表示:{subj}'s birthday is on {obj}。给定包含两个实体![]() 的文本x和模板t,假设h由
的文本x和模板t,假设h由![]() 生成,并分别用实体
生成,并分别用实体![]() 和
和![]() 替换模板中的subj和obj,如Figure 1 Verbalizer部分为给定的实体对生成了4个假设。
替换模板中的subj和obj,如Figure 1 Verbalizer部分为给定的实体对生成了4个假设。
一个关系标签可以用一个或多个模板来表示。例如,关系PER:DATA_OF_BIRTH除了可以用前面的模板表示,还可以表示为{subj} was born on {obj}。同时,一个模板可以描述多个关系标签,例如{subj} was born on {obj}表示PER:COUNTRY_OF_BIRTH和PER:CITY_OF_BIRTH。为了处理这种模糊的表述,本文为每个关系添加了实体类型信息,例如,关系PER:CITY_OF_BIRTH的模板为{subj} was born in the city of {obj}。
本文为每个关系定义了一个函数,用于检查模板和当前关系标签之间的实体一致性:
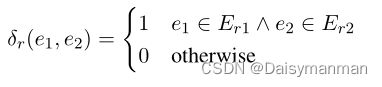
其中, 和
和![]() 是第一个和第二个参数的实体类型,
是第一个和第二个参数的实体类型,![]() 和
和![]() 是关系r中第一个实体和第二个实体的允许类型集。该函数用于推理时,以丢弃不匹配给定类型的关系。
是关系r中第一个实体和第二个实体的允许类型集。该函数用于推理时,以丢弃不匹配给定类型的关系。
NLI for inferring relations
给定包含两个实体![]() 和
和![]() 的文本x,系统从可能的关系标签集合R中返回蕴含概率最高的关系
的文本x,系统从可能的关系标签集合R中返回蕴含概率最高的关系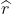 :
:

每个关系的概率![]() 为在可能的假设集中计算产生的最大蕴含概率的假设的概率 。如果两个实体与所需的实体类型不匹配,则概率为零。
为在可能的假设集中计算产生的最大蕴含概率的假设的概率 。如果两个实体与所需的实体类型不匹配,则概率为零。

其中,![]() 是输入文本与模板表达器生成的假设之间的蕴含概率,虽然蕴含模型返回蕴含、矛盾和中性的概率,但是
是输入文本与模板表达器生成的假设之间的蕴含概率,虽然蕴含模型返回蕴含、矛盾和中性的概率,但是![]() 只是使用蕴含概率。Figure 1的右侧显示了NLI模型的应用以及每个关系的概率
只是使用蕴含概率。Figure 1的右侧显示了NLI模型的应用以及每个关系的概率![]() 是如何计算的。
是如何计算的。
Detection of no-relation
在有监督RE中,NO-RELATION情况被视为一个附加标签。
在基于模板的检测中,本文提出了一个额外的模板;在基于阈值的检测中,我们将阈值 应用于公式2中的
应用于公式2中的![]() 。如果没有任何关系超过阈值,则返回NO-RELATION。
。如果没有任何关系超过阈值,则返回NO-RELATION。
Few-Shot relation extraction
本文系统基于一个NLI模型,该模型已经在带标注的蕴含对上进行了预训练。当有标记的关系实例存在时,将其重新表述为标记的NLI对,并使用它们来微调NLI模型,即将最高蕴含概率分配给正确关系的表达器,低蕴含概率分配给假设的其余部分。
给定一组标记关系实例,使用以下步骤来生成标记蕴含对,以便对NLI模型进行微调。(1)对于每个积极关系实例,生成至少一个带有描述当前关系模板的蕴涵实例。也就是说,生成一个或几个被标记为蕴涵的前提-假设对;(2)对于每个积极关系示例,生成一个中性的前提-假设实例,从不代表当前关系的模板中随机选取。(3)对于每个负面关系的例子,我们生成一个矛盾的例子,从其余关系的模板中随机选取。
Results
各场景下的数据集统计

Zero-Shot
不同预训练NLI模型以及参数量和MNLI匹配准确率
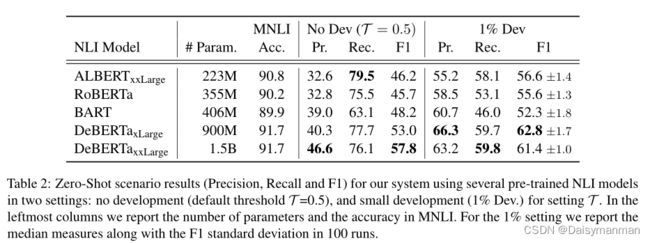
Few-Shot

Full training
