NLP入门之——Word2Vec词向量Skip-Gram模型代码实现(Pytorch版)
代码地址:https://github.com/liangyming/NLP-Word2Vec.git
1. 什么是Word2Vec
Word2vec是Google开源的将词表征为实数值向量的高效工具,其利用深度学习的思想,可以通过训练,把对词的处理简化为K维向量空间中的向量运算。简单来说,Word2Vec其实就是通过学习文本语料来用词向量的方式表示词的语义信息,即通过一个高维向量空间使得语义上相似的单词在该空间内距离很近。比如下图中的dog和cat同属于一类、tree和flower同属于一类,因此在语义上有关联的词在向量空间上也比较接近。

2. Skip-Gram模型
Word2Vec包括两种类型,分别是通过上下文去预测中间词的CBOW和通过中间词预测上下文的Skip-Gram。如下图分别为他们的模型原理图。Skip-Gram模型也是一种简单的神经网络结构,但此模型训练好后并不会直接用于具体任务,我们需要的是获取模型的隐藏层参数,这些参数即为词向量。

接下来举个例子看看算法运作流程:
- 假设有句子
I like nlp very much - 假设中心词为
nlp,则模型的输入为nlp,设参数窗口大小windows=2,那么窗口内的上下文词,即背景词为[‘I’,‘like’,‘very’,‘much’] - 模型要做的就是通过中心词,计算窗口内的背景词的条件概率,即为: P ( P( P(“I”,“like”,“very”,“much” ∣ | ∣ “nlp” ) ) )
- 假设给定中心词时,背景词之间相互独立,则可以进一步得到:
P ( P( P(“I” ∣ | ∣ “nlp” ) ⋅ P ( )\cdot P( )⋅P(“like” ∣ | ∣ “nlp” ) ⋅ P ( )\cdot P( )⋅P(“very” ∣ | ∣ “nlp” ) ⋅ P ( )\cdot P( )⋅P(“much” ∣ | ∣ “nlp” ) ) )
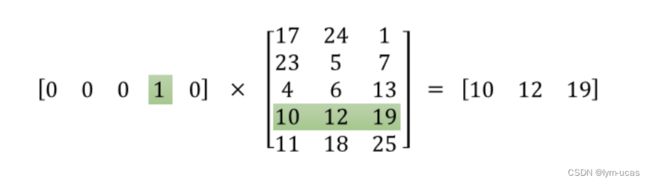
2.1 One-hot编码
因为计算机没法直接处理文本数据,因此我们需要将文本数据通过One-hot编码转换成数值型数据,还是以句子I like nlp very much为例,句子中每个词可以用5维(词表大小)的One-hot向量表示,比如nlp是词表中的第3个词,则表示为[0,0,1,0,0],编码后的矩阵为 n × n n\times n n×n维度, n n n为词表大小。
2.2 lookup查找表
为了将One-hot编码映射到词向量空间,我们需要通过lookup表建立这个映射过程,这个过程叫Word embedding,如下图的例子就是将词表中第4个词映射到对应词向量空间,此例子中词向量为3维,通过矩阵运算可以很容易建立对应映射关系,其中第二个矩阵就是我们的词向量矩阵,而映射过程其实就是词向量矩阵中的第几行就是词表中第几个词的词向量表示
2.3 负采样
负采样(negative sampling)是为了解决训练计算速度的问题,提出的策略。选为做负样本的词,一般叫做噪声词。噪声词的采样是根据词的概率来决定的,出现概率高的单词容易被选为负样本。为了增加一些出现频率少的词被选中的概率,减小常见词被选中的概率,通常按照以下公式采样。
P ( w i ) = f ( w i ) 3 / 4 ∑ j = 0 n ( f ( w j ) 3 / 4 ) P(w_i)=\frac{f(w_i)^{3/4}}{\sum_{j=0}^n(f(w_j)^{3/4})} P(wi)=∑j=0n(f(wj)3/4)f(wi)3/4
负采样的个数一般远远大于正样本的个数。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SkipGram(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGram, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.in_embedding = nn.Embedding(vocab_size, embedding_dim)
self.out_embedding = nn.Embedding(vocab_size, embedding_dim)
def forward(self, center, pos_words, neg_words):
input_embedding = self.in_embedding(center) # [batch_size, embedding_dim]
pos_embedding = self.out_embedding(pos_words) # [batch_size, windows*2, embedding_dim]
neg_embedding = self.out_embedding(neg_words) # [batch_size, windows*2*neg_num, embedding_dim]
input_embedding = input_embedding.unsqueeze(2) # [batch_size, embedding_dim, 1]
# unsqueeze()增加维度,suqueeze()降低维度
pos_loss = torch.bmm(pos_embedding, input_embedding).squeeze() # [batch_size, window*2, 1]
neg_loss = torch.bmm(neg_embedding, -input_embedding).squeeze() # [batch_size, window*2*num, 1]
pos_loss = F.logsigmoid(pos_loss).sum(1)
neg_loss = F.logsigmoid(neg_loss).sum(1)
loss = pos_loss + neg_loss
return -loss
def get_weight(self):
return self.in_embedding.weight.data.cpu().numpy()
3. 全局配置参数
新建config.py文件,定义常量超参数
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
embedding_dim = 100
epochs = 150
batch_size = 64
windows = 3
neg_sam = 5
root_dir = './data'
result_dir = './result'
en_corpus = 'en.txt'
zh_corpus = 'zh.txt'
stopwords = 'stopwords.txt'
lr = 0.01
4. 数据处理模块
在数据处理部分,我们新建mydata.py文件,用于编写数据处理相关代码。首先导入相关包
import torch
from torch.utils import data
import os
import numpy as np
import config
定义Mydata类,继承torch工具包下的Dataset类,在此处读取语料数据并将其转换为需要的数据类型。首先,在构造方法中定义语料路径,初始化参数窗口大小、负采样数量以及根据2.3中的公式计算负采样频率。在__getitem__方法中根据索引取出对应中心词、背景词以及根据负采样频率获取负采样词语,将一组中心词、正样本的背景词、负采样词作为训练实例返回。
class Mydata(data.Dataset):
def __init__(self, root, corpus_name, stop_file, windows=2, neg_sam=5):
super(Mydata, self).__init__()
# 语料库文件
self.data_path = os.path.join(root, corpus_name)
# Skip窗口大小
self.windows = windows
# 每个词的负采样数量
self.neg_sams = neg_sam * 2 * windows
# 中文停用词文件
self.stop_file = os.path.join(root, stop_file)
# -, -, 编码后的序列, 词频表
self.word2id, self.id2word, self.sequence, self.word2count = self.get_data()
# 负采样频率
word_freq = np.array([count for count in self.word2count.values()], dtype=np.float32)
word_freq = word_freq**0.75 / np.sum(word_freq**0.75)
self.word_freq = torch.tensor(word_freq)
def __getitem__(self, index):
center = self.sequence[index]
# 周围词
pos_index = list(range(index-self.windows, index)) + list(range(index+1, index+1+self.windows))
pos_index = [i%len(self.sequence) for i in pos_index]
pos_words = self.sequence[pos_index]
# 返回负采样词
neg_words = torch.multinomial(self.word_freq, self.neg_sams, False)
# 数据放入device
center = center.to(config.device)
pos_words = pos_words.to(config.device)
neg_words = neg_words.to(config.device)
return center, pos_words, neg_words
def __len__(self):
return len(self.sequence)
在Mydata类中自定义一个get_data()方法应用于将文本数据编号并转化为tensor格式,定义字典word2id用于保存词到编号的映射、id2word用于保存编号到词语的映射、word2count用于保存每个词出现的次数。对原始语料数据首先经过停用词表的清洗,去除掉停用词以及标点符号后,得到训练语料,将训练语料加入词表并统计词频,同时将训练语料转换成词表中对应编号的tensor形式表示。
class Mydata(data.Dataset):
'''省略'''
def get_data(self):
# 词表字典
word2id = {}
id2word = {}
# 词频率
word2count = {}
# 词表编码后的语料
sequence = []
with open(self.stop_file, 'r', encoding='utf-8') as file:
stopwords = file.read().split()
with open(self.data_path, 'r', encoding='utf-8') as file:
words = file.read().split()
print("original corpus size: ", len(words))
vocal = [word for word in words if word not in stopwords]
print("new corpus size: ", len(vocal))
for word in vocal:
if word not in word2id:
index = len(word2id)
word2id[word] = index
id2word[index] = word
word2count[word] = word2count.get(word, 0) + 1
sequence.append(word2id[word])
# print("size: ", len(word2id), len(id2word), len(word2count))
sequence = torch.tensor(sequence)
return word2id, id2word, sequence, word2count
编写get_dataloader()函数,传入相应超参数,返回dataloader对象和dataset对象
def get_dataloader(root, corpus_name, stop_file, batch_size, shuffle=True, windows=2, neg_sam=5):
dataset = Mydata(root=root,
corpus_name=corpus_name,
stop_file=stop_file,
windows=windows,
neg_sam=neg_sam)
dataloader = data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=shuffle)
return dataloader, dataset
5. 训练模块
新建main.py文件,首先导入相应包
import torch
import config
import numpy as np
from mydata import get_dataloader
from model import SkipGram
import os
import json
import tqdm
编写train()函数,传入模型、dataloader等参数训练模型,结束后保存模型,并返回loss值
def train(model, dataloader, learning_rate, epochs, save_name):
model.train()
optimizer = torch.optim.SGD(params=model.parameters(), lr=learning_rate)
loss_list = []
for epoch in tqdm.tqdm(range(epochs)):
total_loss = 0
for i, (center, pos_words, neg_words) in enumerate(dataloader):
optimizer.zero_grad()
loss = model(center, pos_words, neg_words).mean()
loss.backward()
optimizer.step()
total_loss += loss.item()
loss_list.append(total_loss)
torch.save(model.state_dict(), os.path.join(config.result_dir, save_name + '_model.pth'))
return loss_list
开始训练。在训练结束后获取模型的隐藏层权重参数,即我们需要的词向量,将词向量保存为json文件便于读取
### 选择语料类型: 'zh' | 'en' ###
corpus = 'en'
################################
corpus_name = config.zh_corpus if corpus == 'zh' else config.en_corpus
dataloader, dataset = get_dataloader(root=config.root_dir,
corpus_name=corpus_name,
stop_file=config.stopwords,
batch_size=config.batch_size,
shuffle=True,
windows=config.windows,
neg_sam=config.neg_sam)
vocab_size = len(dataset.word2id)
model = SkipGram(vocab_size, config.embedding_dim).to(config.device)
loss_list = train(model=model, dataloader=dataloader, learning_rate=config.lr, epochs=config.epochs, save_name=corpus)
np.savetxt(corpus + "_loss.csv", np.array(loss_list), delimiter=',')
# 保存词向量
embedding_weights = model.get_weight()
dic = {word: embedding_weights[idx].tolist() for word, idx in dataset.word2id.items()}
with open(os.path.join(config.result_dir, corpus + '_embed.json'), 'w', encoding='utf-8') as file:
file.write(json.dumps(dic, ensure_ascii=False, indent=4))
6. 词向量工具模块
新建utils.py文件,在这个文件下,主要编写与可视化工具相关的代码,首先导入需要的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from scipy import spatial
import json
import seaborn as sns
import adjustText
编写plot_loss()函数,传入记录的loss列表数据,将loss数据可视化
def plot_loss(loss, name):
length = len(loss)
x = np.arange(1, length + 1)
plt.plot(x, loss)
plt.title(name)
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
创建Tool()工具类,处理词向量,在构造方法中设置pyplot能正常显示汉字,同时读取训练时保存的词向量文件,载入词向量数据
class Tool():
def __init__(self, embedding_path):
# 使得pyplot可输出汉字
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
file = open(embedding_path, 'r', encoding='utf-8')
self.wordVec = json.load(file)
编写find_near_word()方法,根据指定词语,计算其与其他所有词的余弦相似度,选择相似度最大的前num个词作为结果返回
class Tool():
def __init__(self, embedding_path):
'''省略'''
def find_near_word(self, word, num):
'''
:param word: 选定的词
:param num: 需要查找的近义词数量
:return: num个近义词列表
'''
embedding = self.wordVec[word]
cos_sim_list = []
for key, value in self.wordVec.items():
cos_sim = 1 - spatial.distance.cosine(value, embedding)
cos_sim_list.append((cos_sim, key))
cos_sim_list.sort(reverse=True)
return cos_sim_list[0:num]
编写draw_heatmap()方法,通过热力图可视化一系列词向量
class Tool():
def __init__(self, embedding_path):
'''省略'''
def find_near_word(self, word, num):
'''省略'''
def draw_heatmap(self, words):
'''
:param words: 一列的词
'''
vectors = [self.wordVec[word] for word in words]
f, ax = plt.subplots(figsize=(15, 9))
sns.heatmap(vectors, ax=ax)
ax.set_yticklabels(words)
plt.show()
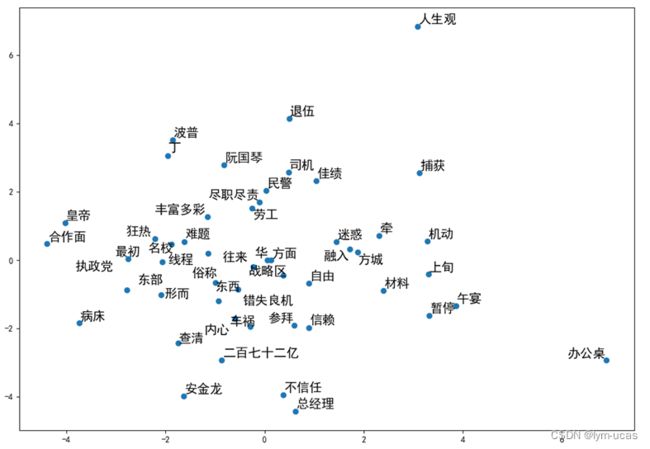
编写draw_scatter()方法,通过散点图可视化各个词在空间中的位置,由于词向量维度太高,因此我们需要使用主成分分析法将词向量降维到2维,才能正常显示在坐标轴上
class Tool():
def __init__(self, embedding_path):
'''省略'''
def find_near_word(self, word, num):
'''省略'''
def draw_heatmap(self, words):
'''省略'''
def draw_scatter(self, words):
'''
:param words: 一列词
'''
pca = PCA(n_components=2)
vectors = [self.wordVec[word] for word in words]
coordinates = pca.fit_transform(vectors)
plt.figure(figsize=(13, 9))
plt.scatter(coordinates[:, 0], coordinates[:, 1])
text = [plt.text(coordinates[i, 0], coordinates[i, 1], words[i], fontsize=15) for i in range(len(words))]
adjustText.adjust_text(text)
plt.show()
7. 实验效果
损失值变化

查找与“中国”接近的5个词,结果为[(1, ‘中国’), (0.9770937577320784, ‘说’), (0.9704815043334012, ‘中’), (0.9691968812096485, ‘美国’), (0.966375220591473, ‘政府’)]

显示词义接近的20个词的热力图

可视化词的坐标