大数据技术之Spark
第1章 Spark概述
1.1 什么是Spark
回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。
区别:
1、MR是基于磁盘,spark是基于内存
2、MR的task是进程
3、spark的task是线程,在executor进程里执行的线程。
4、MR在Container里执行(留有接口方便插入),spark在worker里执行(自己用,没有接口)。
5、MR适合做一次计算,Spark适合做迭代计算
1. 2 spark的使用场景
离线、实时、机器学习、图计算
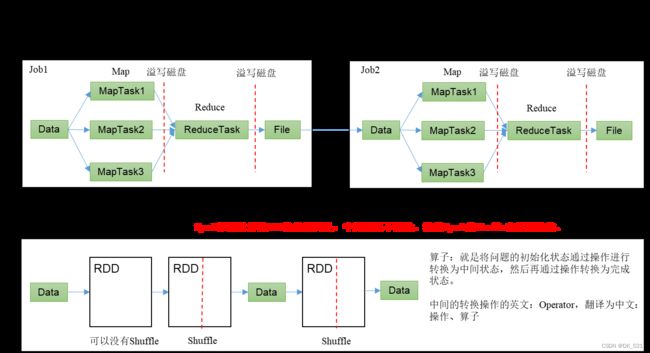
1.3 Hadoop与Spark框架对比
1.4 Spark内置模块
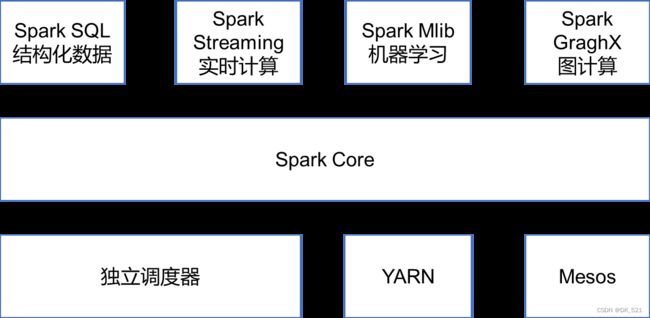
- Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
1.5 Spark的特点

第2章 Spark运行模式
部署Spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
下面详细列举了Spark目前支持的部署模式。
(1)Local模式:在本地部署单个Spark服务
(2)Standalone模式:Spark自带的任务调度模式。(国内常用)
(3)YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内最常用)
(4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。(国内很少用)
2.1 Local模式
1、local模式: 单机安装,解压即可用
1、任务提交: bin/spark-submit --master loca/local[*]/local[N] --class xx.xx.x.x xx.jar 参数 ...
master=local: 使用单个线程模拟执行,同一时间只能执行一个task.
master=local[*]: 使用cpu个数个线程模拟执行,同一时间只能执行cpu个数个task.
master=local[N]: 使用N个线程模拟执行,同一时间只能执行N个task.
2.1.1 安装使用
后续更新
2.2 集群角色
1、Master和Worker集群资源管理
Master: 负责资源管理与分配
Worker: 资源节点与任务执行节点
Master与Worker是随着集群的启动而启动,随着集群的停止而消失。
Master与Worker只有standalone模式才有。

Master和Worker是Spark的守护进程、集群资源管理者,即Spark在特定模式(Standalone)下正常运行必须要有的后台常驻进程。
2、Driver与executor
Driver的职责:
1、负责将代码转成job
2、负责将task提交到executor中执行
3、负责监控task的执行情况
4、负责程序运行过程中web ui界面展示
Executor: 任务执行进程
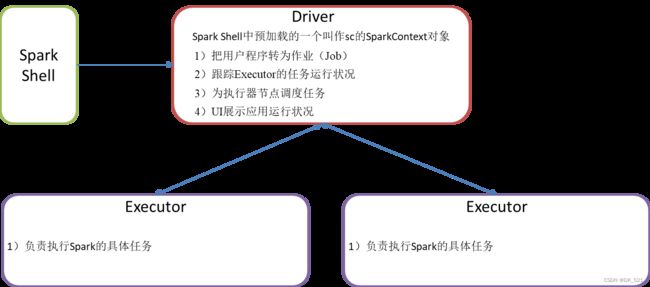
spark执行的是task,task是线程,是启动在executor中的线程
Driver与executor是随着任务的提交而启动,随着任务的完成而消失。
2.3 Standalone模式
2.3.1 安装使用
任务提交: bin/spark-submit --master spark://master主机名:7077,... --class 全类名 jar包所在位置 参数值 ...
后续更新
2.3.2 运行流程
Spark有standalone-client和standalone-cluster两种模式,主要区别在于:Driver程序的运行节点。
1. 客户端模式
[hadoop102 spark-standalone]$ bin/spark-submit --master spark://hadoop102:7077,hadoop103:7077 --deploy-mode client --executor-memory 2G--total-executor-cores 2 --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.1.3.jar
10
--deploy-mode client,表示Driver程序运行在本地客户端,默认模式。
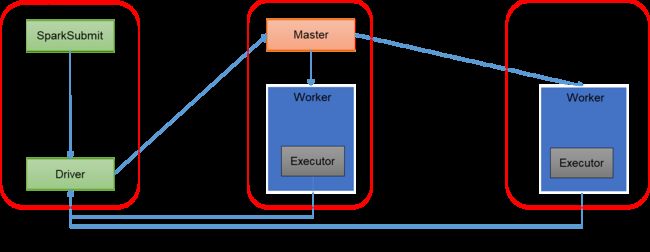
2. 集群模式模式
[hadoop102 spark-standalone]$ bin/spark-submit --master spark://hadoop102:7077,hadoop103:7077 --deploy-mode cluster --executor-memory 2G--total-executor-cores 2 --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.1.3.jar
10
--deploy-mode cluster,表示Driver程序运行在集群。

standalone的client与cluster部署模式的区别
client模式: Driver在SparkSubmit进程中,此时该进程不能关闭,关闭之后Driver消失无法进行任务调度,程序会终止。
cluster模式: Driver在任意一个Worker中,此时SparkSubmit关闭不影响程序执行
2.4 Yarn模式
Spark客户端直接连接Yarn,不需要额外构建Spark集群。使用yarn作为资源调度器。
2.4.1 安装使用
任务提交: bin/spark-submit --master yarn --class 全类名 jar包所在位置 参数值 ...
待更新
2.4.2 运行流程
Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster,适用于生产环境。
1. 客户端模式(默认)
[hadoop102 spark-yarn]$ bin/spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.1.3.jar
10

2. 集群模式
[hadoop102 spark-yarn]$ bin/spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.1.3.jar
10

yarn的client与cluster部署模式的区别
client模式: Driver在SparkSubmit进程中,此时该进程不能关闭,关闭之后Driver消失无法进行任务调度,程序会终止。
cluster模式: Driver在ApplicationMaster进程中,此时SparkSubmit关闭不影响程序执行。
2.5 几种模式对比
| 模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
| Local |
1 |
无 |
Spark |
| Standalone |
3 |
Master及Worker |
Spark |
| Yarn |
1 |
Yarn及HDFS |
Hadoop |
2.7 端口号总结
1)Spark查看当前Spark-shell运行任务情况端口号:4040
2)Spark Master内部通信服务端口号:7077 (类比于yarn的8032(RM和NM的内部通信)端口)
3)Spark Standalone模式Master Web端口号:8080(类比于Hadoop YARN任务运行情况查看端口号:8088) (yarn模式) 8989
4)Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)
2.8 spark-submit常用参数
--master 指定任务提交到哪个资源调度器中
--executor-memory 指定每个executor的内存大小
--executor-cores 指定每个executor的cpu核数
--total-executor-cores 指定所有executor的cpu总核数[仅限于standalone模式使用]
--num-executors 指定任务需要的executor个数[仅限于yarn模式使用]
--queue 指定任务提交到哪个资源队列中[仅限于yarn模式使用]
--deploy-mode 指定任务的部署模式[client/cluster]
--driver-memory 指定driver的内存大小
--class 指定待运行的带有main方法object的全类名