【PyTorch】第六节:乳腺癌的预测(二分类问题)
作者️♂️:让机器理解语言か
专栏:PyTorch
描述:PyTorch 是一个基于 Torch 的 Python 开源机器学习库。
寄语:没有白走的路,每一步都算数!

介绍
上一个实验我们讲解了线性问题的求解步骤,本实验我们以乳腺癌的预测为实例,详细的阐述如何利用 PyTorch 求解一个非线性问题。
知识点
- 数据集的标准化
- 数据集的划分
- Sigmoid 函数
- 乳腺癌的预测
数据集的预处理
数据集的加载
首先,让我们来加载数据集合。这里我们使用 pandas 对数据集合进行加载:
import pandas as pd
df = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/2534/breast_cancer.csv', index_col=False) # index_col 指定某个列为索引。
df
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.16220 | 0.66560 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.12380 | 0.18660 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.14440 | 0.42450 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.24140 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.20980 | 0.86630 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.19800 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.13740 | 0.20500 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 564 | 21.56 | 22.39 | 142.00 | 1479.0 | 0.11100 | 0.11590 | 0.24390 | 0.13890 | 0.1726 | 0.05623 | ... | 26.40 | 166.10 | 2027.0 | 0.14100 | 0.21130 | 0.4107 | 0.2216 | 0.2060 | 0.07115 | 0 |
| 565 | 20.13 | 28.25 | 131.20 | 1261.0 | 0.09780 | 0.10340 | 0.14400 | 0.09791 | 0.1752 | 0.05533 | ... | 38.25 | 155.00 | 1731.0 | 0.11660 | 0.19220 | 0.3215 | 0.1628 | 0.2572 | 0.06637 | 0 |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | 0 |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | 0 |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | 1 |
569 rows × 31 columns
可以看到该数据集合一共有 569 条数据,每条数据有 30 个和乳腺癌相关的病变特征,最后一列是该患者是否患有乳腺癌的诊断结果。其中 0 表示没有患有乳腺癌,1 表示患有乳腺癌。
我们可以利用 pandas 中的切片,先将上表中的特征和标签分开:
X = df[df.columns[0:-1]].values # 取出30个特征的值
# df.columns[0:-1]取出第0列到倒数第二列的指标名
# df[df.columns[0:-1]].values取出这些指标名所在列的值
y = df[df.columns[-1]].values # 取出1个标签的值
X.shape, y.shape
# ((569, 30), (569,))可以看到共有 569 条数据,每条数据有 30 个特征和 1 个标签。
数据集的划分和标准化
为了能够评价模型的好坏,这里我们利用 sklearn.model_selection 函数,将原数据按比例随机分为训练数据集和测试数据集,如下:
from sklearn.model_selection import train_test_split
# 按照 0.8 和 0.2 的比例随机划分数据集合
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=1234)
# test_size=0.2:测试集为20%;random_state=1234:设置了固定值,每次分割结果一样,不会数据洗牌
X_train.shape, y_train.shape, X_test.shape, y_test.shape
# ((455, 30), (455,), (114, 30), (114,)) 为了加快模型的收敛速度,一般我们都需要对原始数据进行标准化处理,将所有的数据按照比例缩放到一定范围内。这里我们可以使用 sklearn.preprocessing 来对数据集合进行标准化。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler() # 对特征进行标准化,标签不要标准化,因为标签只有 0 和 1
X_train = sc.fit_transform(X_train) # fit_transform对训练集进行标准化
X_test = sc.transform(X_test) # transform对测试集进行标准化
X_train
最后,为了将数据放入 PyTorch 定义的模型之中,我们必须将所有的数据转为 张量类型:
import torch
import numpy as np
# 将 NumPy 类型的变量转为 Tensor
X_train = torch.from_numpy(X_train.astype(np.float32))
X_test = torch.from_numpy(X_test.astype(np.float32))
y_train = torch.from_numpy(y_train.astype(np.float32))
y_test = torch.from_numpy(y_test.astype(np.float32))
# 将标签也转为 2 维,否则放入模型之中训练时,可能出错(因为标签原本只有一列,每一行就一个数,现在要变为二维(标签的第二维为1),和x匹配)
y_train = y_train.view(y_train.shape[0], 1)
y_test = y_test.view(y_test.shape[0], 1)
X_train.size(), y_train.size()
# (torch.Size([455, 30]), torch.Size([455, 1]))乳腺癌的预测
模型的定义
在处理完数据后,接下来,我们就需要建立相应的模型,用于乳腺癌的预测了。
线性函数是一条没有上界和下界的直线,即线性函数预测出来的值可以很大如 112321442,也可以很小如 -1231242412。而本实验的数据标签只有 0(患病) 或 1(不患病),因此用线性函数来拟合乳腺癌的数据点是不合理的。
我们需要找到输出始终为 0-1 之间的函数模型。如果拥有这样的函数模型,那么将任意 x 放入该模型中,都会输出一个 0-1 之间的值。这个值我们可以看做是患有乳腺癌的概率。如果这个概率值小于 0.5 则表示没有患乳腺癌。如果这个概率值大于 0.5 则表示患有乳腺癌。
逻辑回归函数 Sigmoid 就是这样一种函数,该函数又叫做激活函数,公式如下:
![]()
该函数的几何形式如下所示:
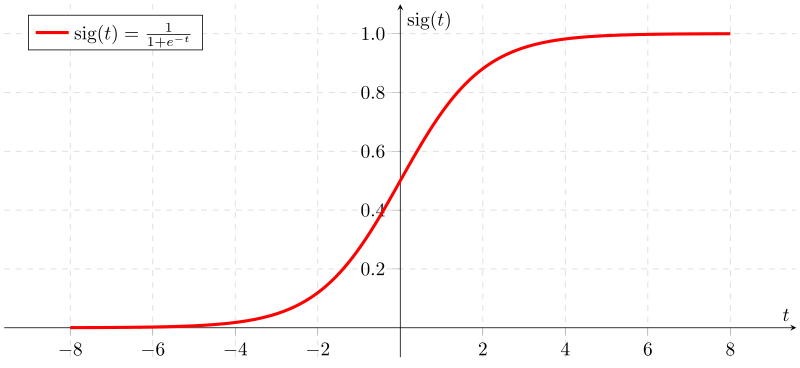
从图中我们可以看出,该函数就是一个上下界分别为 1 和 0 的有界非线性函数。我们可以让通过了线性函数的输出,再通过一次上面的激活函数,进而得到 0-1 之间的结果。
综上,乳腺癌的预测模型如下:
import torch.nn as nn
# 我们的模型是一个线性函数+激活函数的非线性模型
# modle(x) = sigmoid(w*x+b)
class Model(nn.Module):
def __init__(self, n_input_features):
super(Model, self).__init__()
self.linear = nn.Linear(n_input_features, 1) # 参数:输入神经元的个数和输出神经元的个数
def forward(self, x):
# torch 中已经定义了 sigmoid 函数模型
y_pred = torch.sigmoid(self.linear(x))
return y_pred
# 获得样本量和特征数
n_samples, n_features = X.shape
# 模型的初始化
model = Model(n_features)
model

至此,我们就得到了一个乳腺癌的初始模型。由于最后通过了一层逻辑回归函数,无论输入的值为多少,模型的输出都必定属于 0-1 之间。
损失函数和优化器
接下来的步骤和上个实验中的步骤类似。
首先,让我们来定义一下损失函数,由于我们的标签只有 0 和 1,因此这里使用二元交叉熵损失nn.BCELoss()来计算真实值和预测值之间的距离了。该损失函数的公式如下:

当然,我们不必手写上面的损失函数, 直接使用 nn.BCELoss() 即可:
# 损失和优化器的定义
# 迭代次数
num_epochs = 100
# 学习率
learning_rate = 0.01
# 二元交叉熵损失
criterion = nn.BCELoss()
# SGD 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion, optimizer

模型的训练
定义完损失函数和优化器后,接下来的模型训练步骤就是固定的了,如下:
- 通过模型的正向传播,输出预测结果。
- 通过预测结果和真实标签计算损失。
- 通过后向传播,获得梯度。
- 通过梯度更新模型的权重。
- 进行梯度的清空。
- 循环上面操作,直到损失较小为止。
让我们用代码完成上面的步骤:
for epoch in range(num_epochs):
y_pred = model(X_train)
loss = criterion(y_pred, y_train)
# 后向传播、梯度更新、梯度清空
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (epoch+1) % 10 == 0:
print(f'epoch: {epoch+1}, loss = {loss.item():.4f}')
print("模型训练完毕!!")

综上,我们训练好了一个乳腺癌的预测模型。我们可以尝试对任意一条数据进行预测:
index = np.random.randint(0, len(X_test)) # 生成随机整数
y_predicted = model(X_test[index]) # 向模型中传入x,模型返回y
# 小于 0.5 则输出 0 ,大于0.5 则输出 1
y_predicted_cls = y_predicted.round() # round() 四舍五入取整
# 将结果转为 numpy类型
real = y_test[index].detach().numpy()[0] # 真实值
# real = y_test[index].detach():通过.detach() “分离”得到的的变量会和原来的变量共用同样的数据,y_test[index]发生了变化,原来的张量也会发生变化,而且新分离得到的张量real是不可求导的。
predict = y_predicted_cls.detach().numpy()[0] # 预测值
print("第 {} 条测试数据的真实结果为 {} ,预测结果为 {} "
.format(index, real, predict))
# 第 82 条测试数据的真实结果为 1.0 ,预测结果为 1.0 由于模型准确率不是 100%,因此,上面的预测结果和真实结果也可能会不相同。但是,你多运行几次上面代码,必定会出现预测结果和真实结果相同的情况。
那么,我们训练出来的模型准确率到底是多少呢?
with torch.no_grad():
y_predicted = model(X_test)
y_predicted_cls = y_predicted.round()
acc = y_predicted_cls.eq(y_test).sum().numpy() / float(y_test.shape[0])
# y_predicted_cls.eq(y_test).sum() # 测试值与预测值相同的样本总数
print(f'accuracy: {acc.item():.4f}')
# accuracy: 0.9123我们利用测试数据,计算出了整个模型的预测准确率大概在 90% 左右,证明我们的模型可以很好地进行乳腺癌的诊断预测。
实验总结
本实验以乳腺癌的预测为例,引入了激活函数 sigmoid 的概念。建立了一个简单的非线性模型用于诊断患者是否患有乳腺癌。其实,本实验建立的一个线性函数+激活函数的模型就是一个简单的神经网络模型。全连接神经网络的实质其实就是无数个线性函数和非线性网络组成的集合。