Linux程序的内存
要研究程序的运行环境,首先要弄明白程序与内存的关系。程序与内存的关系,好比鱼和水一般密不可分。内存是承载程序运行的介质,也是程序进行各种运算和表达的场所。了解程序如何使用内存,对程序本身的理解,以及后续章节的探讨非常有利。
程序的内存布局
现代的应用程序都运行在一个内存空间里,在32位的系统里,这个内存空间拥有4GB的寻址能力。Linux默认情况下将高地址的1GB空间分配给内核,剩下的3GB的内存分配给应用进程,称为用户空间。在用户空间里,也有很多地址区间有特殊的地位,一般来讲,应用程序使用的内存空间里有如下"默认"的区域。
1、栈:栈用于维护函数调用的上下文,离开了栈函数调用就无法实现。栈通常在用户空间的最高地址处分配,通常有数兆字节的大小。
2、堆:堆是用来容纳应用程序动态分配的内存区域,当程序使用malloc或new分配内存时,得到的内存来自堆里。堆通常存在于栈的下方(低地址方向),在某些时候,堆也可能没有固定统一的存储区域。堆一般比栈大很多,可以有几十至数百兆字节的容量。
3、可执行文件映像:这里存储着可执行文件在内存里的影像。由装载器在装载时将可执行文件的内存读取或映射到这里。
4、保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称,例如,大多数操作系统里,极小的地址通常都是不允许访问的,如NULL,通常C语言将无效指针赋值为0也是出于这个考虑,因为0地址上正常情况下不可能有有效的可访问数据。图1是Linux下一个进程里典型的内存布局。
图1

在图1中,有一个没有介绍的区域:"动态链接库映射区",这个区域用于映射装载的动态链接库。在Linux下,如果可执行文件依赖其他共享库,那么系统就会为它在适当的地址分配相应的空间,并将共享库载入到该空间。
在图中箭头表明了几个大小可变的区的尺寸增长方向,在这里可以清晰看出栈向低地址增长,堆向高地址增长。当栈或堆现有的大小不够用时,它将按照图的增长方向扩大自身的尺寸,直到预留的空间被用完为止。
栈和调用惯例
栈是现代计算机程序里最为重要的概念之一,几乎每个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今能够看见的所有的计算机语言。
在经典的计算机科学中,栈被定义为一个特殊的容器,用户可以将数据压入栈中(入栈),也可以将已经压入栈中的数据弹出(出栈),但栈这个容器必须遵循一条规则:先入栈的数据后出栈。
在计算机系统中,栈则是一个具有以上属性的动态区域。程序可以将数据压入栈中,也可以将数据从栈顶弹出。压栈操作使得栈增大,而弹出操作使栈减小。
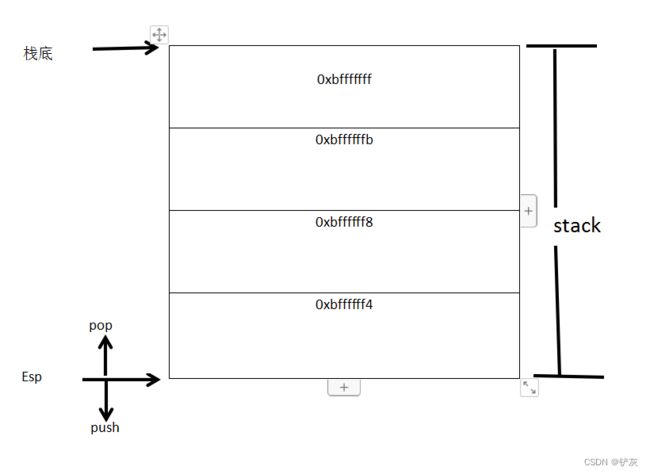
在经典的操作系统里,栈总是向下增长的。栈顶由称为esp的寄存器进行定位。压栈的操作使得栈顶的地址减小,弹出的操作使得栈顶的地址增大。
这里的栈底的地址是0xbfffffff,而esp寄存器表明了栈顶,地址为0xbffffff4。在栈上压入数据会导致esp减小,弹出数据使得esp增大。相反,直接减小esp的值也等效于在栈上开辟空间,直接增大esp的值等效于在栈上回收空间。如图2所示-程序栈实例。
图2
栈在程序运行中具有举足轻重的地位。最重要的是,栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧或活动记录。堆栈帧一般包括如下几个方面内容:
1、函数的返回地址和参数。
2、临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
3、保存的上下文:包括在函数调用前后需要保持不变的寄存器。
一个函数的活动记录用ebp和esp这两个寄存器规定范围。esp寄存器始终指向栈的顶部,同时也就指向了当前函数的活动记录的顶部。而相对的,ebp寄存器指向了函数活动记录的一个固定位置,ebp寄存器又称为帧指针。一个很常见的活动记录如图3所示。
图3 活动记录

在参数之后的数据(包括参数) 既是当前函数的活动记录,ebp固定在图中所示的位置,不随这个函数的执行而变化,相反地,esp始终指向栈顶,因此随着函数的执行,esp会不断变化。固定不变的ebp可以用来定位函数活动记录中的各个数据。在ebp之前首先是这个函数的返回地址,它的地址是ebp-4,再往前是压入栈中的参数,它们的地址分别是ebp-8,ebp-12等,视参数数量和大小而定。ebp所直接指向的数据是调用该函数前ebp的值,这样在函数返回的时候,ebp可以通过读取这个值恢复到调用钱的值。之所以函数的活动记录会形成这样的结构,是因为函数调用本身如此书写的:一个函数总是这样调用的:
1、把所有或一部分参数压入栈中,如果有其他参数没有入栈,那么使用某些特定的寄存器传递。
2、把当前指令的下一条指令的地址压入栈中。
3、跳转到函数体执行。
其中第2步和第3步由指令call一起执行。跳转到函数体之后即开始执行函数,一个函数体的"标准"开头是这样的:
1、push ebp:把ebp压入栈中(称为old ebp)。
2、move ebp,esp:ebp=esp(这时ebp指向了栈顶,而此时栈顶就是old ebp)。
3、【可选】sub esp,XXX:在栈上分配XXX字节的临时空间。
4、【可选】push XXX:如有必要,保存名为XXX寄存器(可重复多个)。
把ebp压入栈中,是为了在函数返回的时候便于恢复以前的ebp的值。而之所以可能要保存一些寄存器,在于编译器可能要求某些寄存器在调用前后保持不变,那么函数就可以在调用开始时将这些寄存器的值压入栈中,在介绍后再取出。不难想象,在函数返回时,所进行的"标准"结尾与"标准"开头正好相反:
1、【可选】pop XXX:如有必要,恢复保存过的寄存器(可重复多个)。
2、move esp,ebp:恢复ESP同时回收局部变量空间。
3、pop ebp:从栈中恢复保存的ebp的值。
4、从栈中取得返回地址,并跳转到该位置。