MapReduce学习2-1:以官方wordcount实例为例的MapReduce程序学习
-
- 1 实例演示与源码jar包反编译
-
- 1.1 wordcount实例运行测试
- 1.2 jar包反编译
- 2 hadoop的序列化类型
-
- 2.1 hadoop序列化类型解析
- 2.1 hadoop序列化类型解析常用序列化类型及其与Java类型的比较
- 3 编程规范与阶段解析
-
- 3.1 插件开发过程概述
- 3.2 Mapper阶段
- 3.3 Reducer阶段
- 3.4 Driver阶段
- 4 本地执行案例实操
-
- 4.1 wordcount.txt输入
- 4.2 WordcountMapper类编写
- 4.3 WordcountReducer类编写
- 4.4 WordcountDriver类编写
- 4.5 结果输出
- 5 提交到集群案例实操
- 6 Wordcount.class源码
1 实例演示与源码jar包反编译
1.1 wordcount实例运行测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount hdfs上的输入文件路径hdfs上的 输出路径
#注意输出的目录不能存在
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
2、结果
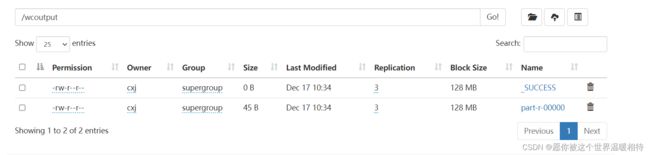

最终结果是统计出对应的单词的及其数量(右边的数字)
1.2 jar包反编译
解析之前可以使用
jar包反编译工具进行对官方的实例进行反向编译:拉到最下边选择普通下载
将官方的实例jar包拖进去就可以得到上述
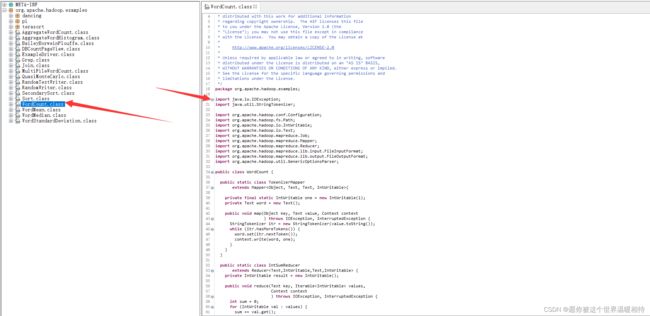
如上图为
Wordcount.class源码,文末附带Wordcount.class的源码
2 hadoop的序列化类型
2.1 hadoop序列化类型解析
通过源码可以看到实现对应的Map以及Reduce过程,在源码中实际是通过继承两个类进行处理的,也就是Mapper类和Reducer类
// Mapper类继承
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>
// Reducer类继承
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable>
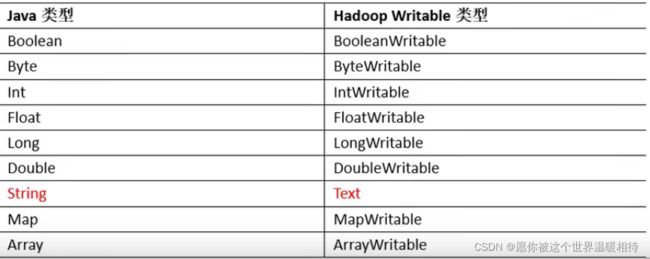
上述中Text实际相当于字符串类型、IntWritable实际为整型类型。但是是hadoop框架自定义的,因为Java的类型都是经过序列化的,传入的参数也是经过序列化后传入内部,序列化后数据量增大,对于hadoop而言,这种序列化太过笨重,因此hadoop定制自身的、更为轻巧的序列化机制,但是整个程序依旧是基于Java的,也是会经过Java的序列化,所以要使用hadoop定制的序列化机制,就需要hadoop自身的序列化类型,例如上述的Text和IntWritable
2.1 hadoop序列化类型解析常用序列化类型及其与Java类型的比较
3 编程规范与阶段解析
3.1 插件开发过程概述
用户编写的程序分成三个部分:Mapper、Reducer、Driver
实现一个MapRducer程序是一个插件类型的开发套路,包括以下三个步骤:
- 继承类或者实现接口,通过对应的类实现上述的三个部分
- 实现或者重写相关的方法
- 提交执行
3.2 Mapper阶段
- 用户自定义的
Mapper要继承自己的父类 Mapper的输入数据是KV(键值对)对的形式(KV(键值对的类型可自定义)Mapper中的业务逻辑写在map()方法中Mapper的输出数据是KV(键值对)的形式(KV(键值对)的类型可自定义)map()方法(MapTask进程)对每一个
3.3 Reducer阶段
- 用户自定义的
Reducer要继承自己的父类 Reducer的输入数据类型对应Mapper的输出数据类型,也是KV(键值对)Reducer的业务逻辑写在reduce()方法中- R
edhuceTask进程对每一组相同k的K,V>组调用一次reduce()方法
3.4 Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
4 本地执行案例实操
4.1 wordcount.txt输入
hello world
good morning
glove cxj lqq blmw
cxj cxj
编写MapReducer需要完成三个功能部分相关的类:Mapper、Reducer、Driver。接下来自定义各个部分进行分析该案例
4.2 WordcountMapper类编写
通过该类实现Map阶段
创建WordcountMapper类并继承hadoop的Mapper类,并重写map方法。map方法是必须实现的,具体格式以及泛型参数解析如下
package com.wordcount.maven;
// 这里放了完整的类,必须看好是以下的类,例如Text是属于hadoop.io的类,而不是其他,刑如Text相关的类是很多的
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN:输入数据的key的类型 Longwritable类型 ,用来表示偏移量(从文件的哪个位置读取数据)
* VALUEIN:输入数据的vaLue的类型 Text类型,从文件中读取到的一行数据
*
* KEYOUT:输出数据的key的类型 Text类型,表示一个单词
* VALUEOUT:输出数据的value的类型 Intwritable类型 ,表示这个单词出现的次数
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
// 设置IntWritable类型,并且设置的值默认为1
private IntWritable outV = new IntWritable(1);
/**
*
* @param key 表示的是偏移量,机器对文件的处理是不知道你是哪一行的
* 所以每次标识行是通过偏移量进行指定
* @param value 表示一行的文本的值
* @param context 表示的是上下文,负责调度Mapper类中的方法
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// super.map(key, value, context); 因为是自定义,所以不需要调用父类构造函数
// 获取一行数据,并转换成Java对应的类型
String line = value.toString();
// 一行数据按空格进行分割获得单词的组合
String[] words = line.split("\\W+");
for (String word: words){
// 将Java的String类型转换成Text类型
outK.set(word);
// 输出,这里会处理成KV的形式,例如:hello,1
context.write(outK, outV);
}
}
}
4.3 WordcountReducer类编写
创建WordcountReducer类并继承hadoop的Reducer类,并重写reduce方法。reduce方法是必须实现的,具体格式以及泛型参数解析如下
package com.wordcount.maven;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN:输入数据的key的类型 Text类型(Mapper输出的类型相对应)
* VALUEIN:输入数据的value的类型 IntWritable类型(Mapper输出的类型相对应,按之前的逻辑,这里传入就是1)
* KEYOUT:输出数据的key 的类型 Text类型(因为输出要求是这里是某个单词)
* VALUEOUT:输出数据的value的类型 IntWritable类型(输出单词的个数)
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
/**
*
* @param key 传入的键值,也就是Mapper的输出的单词,键只会有一个
* @param values 值的集合。因为键只有一个,所以这里是值的集合,这里也就是同一个单词的1的集合,统计1就可以统计单词数
* @param context 上下文,通过它可以使用Reducer的方法
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// super.reduce(key, values, context);
int sum = 0;
for (IntWritable value: values){
// 值的获取,也就是1
sum += value.get();
}
// sum 转换成hadoop序列化的整型
outV.set(sum);
context.write(key, outV);
}
}
reduce的输入数据中key就Mapper输出的键,也就是具体的单词,它不是按切割的单词去进行调用一次reduce方法,而是按一定顺序的并且是一组的。上述实例的输入案例中,他不是按Mapper中处理一行然后输出的顺序进行处理,而是按输入的键值的字母排序处理的,例如输入案例中cxj在第三行而hello在第一行,但是先输入reduce方法的首先是cxj然后才是hello,因为就首字母而言c在ASCII里边是在h前边的,这里就解释了同一个键,他是对应一个values的迭代器对象,里边存储的是他的值的集合,以这一个键以及他的一个集合为一组,每一组数据处理调用一个reduce方法
4.4 WordcountDriver类编写
这是一个驱动类,主要是将我们的MapReduce程序封装成一个job对象,并提交执行,可以看做是整个程序的入口
package com.wordcount.maven;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1、创建job对象并传入配置,可通过配置对象进行配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2、在job对象上设置驱动类
job.setJarByClass(WordcountDriver.class);
// 3、在job对象上设置Mapper类和Reducer类,关联两个类从而驱动两个类完成Map和Reduce阶段
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4、设置整个job的输入的键和值的类型,跟Mapper中输入的键值类型相对应
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5、设置整个job的输出的键和值的类型,跟Reduce中输入的键值类型相对应,这里最好设置,因为Reduce阶段是可以不存在,也就是最终的输出可以是Map阶段的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6、设置输入的文件路径。这里输出的路径是不能存在
FileInputFormat.setInputPaths(job, new Path("E:\\bigdata\\study\\test_files\\wcinput"));
FileOutputFormat.setOutputPath(job, new Path("E:\\bigdata\\study\\test_files\\wcoutput"));
// 7、提交job,传入true打印job工作过程
job.waitForCompletion(true);
}
}
上述例子为本地测试,输入的路径是本地路径,而不是
hadoop的路径
4.5 结果输出

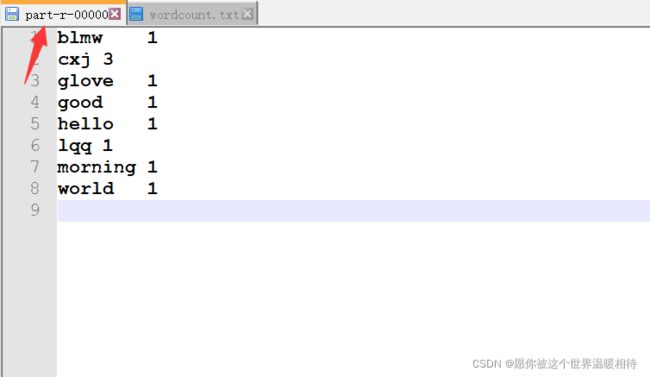
5 提交到集群案例实操
上述是在本地进行测试,也就是文件是本地输入的,但是一般而言更多是在集群上进行操作,这个时候需要打包成
jar包,然后通过hadoop命令进行操作,也就是通过hadoop jar命令
上述的本地执行基本完成所有逻辑,提交到集群中,通过
jar包执行,主要处理的是输入路径和输出路径,也就是将二者转换成命令行输入
1、主要是使用main方法中的args参数即可,以第一个参数为输入文件,第二个参数为输出目录,在WordcountDriver.class中更改如下逻辑,其他不变:
package com.wordcount1.maven;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordcountDriver.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
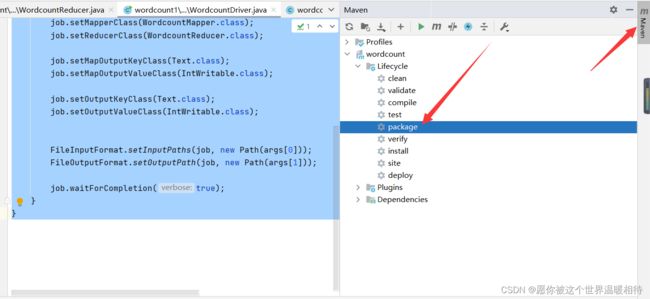
2、将整个项目打包,如果是使用IDEA可以通过点击右侧的Maven然后点击pakage即可,如果是STS,也可以通过右键项目找到Maven点击Maven install也可以进行打包,这里不演示。如果之前打包或者编译够记得先使用clean一下,也就是点击一下下图中的clean,或者STS的Maven clean
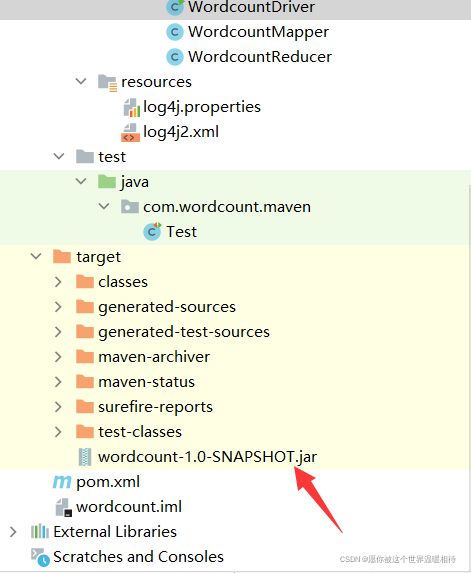
打包后的jar包都在target文件夹下
3、通过工具,例如Xtp或者Xhell上传到服务器集群中,通过以下命令执行
hadoop jar wordcount-1.0-SNAPSHOT.jar 驱动类 hdfs上的输入目录 hdfs上的输出目录
# 例子
hadoop jar wordcount-1.0-SNAPSHOT.jar com.wordcount1.maven.WordcountDriver /wcinput /wcoutput
1、上述驱动类要写
全类名,也就时从包名到类,例如上述例子,官方例子是经过处理的,所以不需要写全类名
2、输出目录也不能存在
6 Wordcount.class源码
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] " );
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}