MYSQL 索引失效的十个场景(二)
六、对索引列运算(如,+、-、*、/、%等),索引失效
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`score` decimal(10,2) DEFAULT NULL,
`subject` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '科目',
`create_time` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `student_name_IDX` (`name`) USING BTREE,
KEY `student_subject_IDX` (`subject`,`score`) USING BTREE,
KEY `student_create_time_IDX` (`create_time`) USING BTREE,
KEY `student_score_IDX` (`score`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci表结构student有一索引:`student_score_IDX` (`score`)
- 对索引列使用运算符:不走索引
explain select * from student s where score +1=88

七、索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
表结构student有一索引:`student_score_IDX` (`score`)
explain select * from student s where score <> 88
explain select * from student s where score not in (80,88,90)
八、索引字段上使用is null, is not null,可能导致索引失效。
表结构student有一索引:`student_score_IDX` (`score`)
explain select * from student s where score IS NOT NULL
九、多表查询关联的字段编码格式不一样,可能导致索引失效。
两个表:
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`score` decimal(10,2) DEFAULT NULL,
`subject` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '科目',
`create_time` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `student_name_IDX` (`name`) USING BTREE,
KEY `student_subject_IDX` (`subject`,`score`) USING BTREE,
KEY `student_create_time_IDX` (`create_time`) USING BTREE,
KEY `student_score_IDX` (`score`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
CREATE TABLE `student_job` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`name` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci- student表的name字段编码是utf8mb4,而student_job表的name字段编码为utf8;且两个字段都添加了索引;
explain select s.name,sj.name ,sj.job from student s left join student_job sj on s.name =sj.name 
- 修改两个字段编码都为是utf8mb4,且两个字段都添加了索引;
CREATE TABLE `student_job` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ciexplain select s.name,sj.name ,sj.job from student s left join student_job sj on s.name =sj.name 
十、mysql估计使用全表扫描要比使用索引快,则不使用索引。
-
当表的索引被查询,会使用最好的索引,除非优化器使用全表扫描更有效。优化器优化成全表扫描取决与使用最好索引查出来的数据是否超过表的30%的数据。
-
不要给'性别'等增加索引。如果某个数据列里包含了均是"0/1"或“Y/N”等值,即包含着许多重复的值,就算为它建立了索引,索引效果不会太好,还可能导致全表扫描。
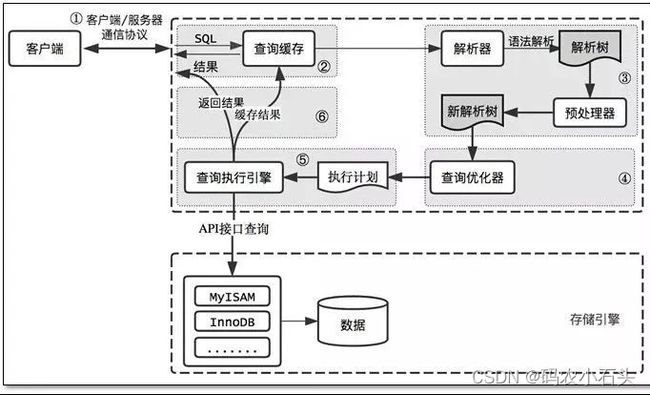
Mysql出于效率与成本考虑,估算全表扫描与使用索引,哪个执行快,会选择预估最优的方式(实际可能不是最优)。附上一张执行查询逻辑图