html,xml_网页开发_爬虫_笔记
20220720

scrapy:二级跳转的两个url需要不一样
20220719

scrapy,如果不牵扯到登陆的话,解析的第一步,直接获取网页内容就可以了
2022507
user_agent是由浏览器的版本决定
20220427

OPTIONS:这个方法很有趣,但极少使用。它用于获取当前URL所支持的方法。若请求成功,则它会在HTTP头中包含一个名为“Allow”的头,值是所支持的方法,如“GET, POST”。
20220425
https://www.csdn.net/tags/Mtjagg5sNTkzNzEtYmxvZwO0O0OO0O0O.html
http状态码
getpost,options,header请求都属于http请求
https://blog.csdn.net/weixin_45832482/article/details/113844082
post,options区别

爬虫可以直接通过请求接口连接
通过post传递参数来请求数据,
而不是请求网页连接,
通过网页源码数据来获取目前数据
20220420

scrapy.Request提交参数
meta传递参数给下一个函数
body:传递的post参数
https://wenku.baidu.com/view/9ba141850329bd64783e0912a216147917117ecb.html
浏览器user-agent就是浏览器标识
20220418
https://zhidao.baidu.com/question/2121871171469939307.html
200和304的区别
304文件是否被修改过?
Percentage of HEAD requests: HTTP GET requests are
used to retrieve web-page content whereas HTTP HEAD
requests retrieve web-page metadata. It is expected that
“polite” crawlers would use the HEAD method, when possible,
in order to detect and download only recently
updated pages, so as to minimize the consumption of
Web-server resources.
header请求和get请求的区别
https://blog.csdn.net/qq_41658123/article/details/113994979
分布式爬虫
20220402
笔记本走手机热点,重连之后又是另一个ip
20220331
https://mp.weixin.qq.com/s/znXuCB0Fl32TbP_0UaO6SQ
爬虫相关知识快速复习
20220329
'$remote_addr | $time_iso8601 | $request | ''$status | $body_bytes_sent | $http_referer | ''$http_user_agent | $upstream_addr | $upstream_response_time | $request_time |'
客户端地址 访问日期时间 请求接口明细(请求方式 接口 协议) 请求状态码 请求头大小 前端访问主页地址(调用我们接口的来源地址) 浏览器agent 内部接口负载服务器
后端响应时间 总请求响应时间
125.69.60.179 | 2022-03-24T00:00:14+08:00 | POST /search/search/suggest HTTP/1.1 | 200 | 78 | - | okhttp/3.2.0 | 172.28.131.32:10020 | 0.012 | 0.013 |
125.69.60.179 | 2022-03-24T00:00:14+08:00 | POST /search/search/suggest HTTP/1.1 | 200 | 78 | - | okhttp/3.2.0 | 172.28.131.25:10020 | 0.011 | 0.013 |
nginx日志
https://github.com/xiaoyang611/crawler-denfender
https://zhuanlan.zhihu.com/p/103009591
机器学习反爬虫
20220215
Pyppeteer 比 selenium更高效?
20211220

查看chrome版本
解决:selenium.common.exceptions.WebDriverException: Message: 'chromedriver' execu
browser = webdriver.Chrome(options=chrome_options)
path参数默认
D:\Python37\Scripts
chromedriver放在这个文件夹下面
20211204
https://blog.csdn.net/m0_62298204/article/details/120802053
Executable path has been deprecated please pass in a Service object in Selenium Python
20211014
https://bjjdkp.github.io/post/concurrent_requests-and-download_delay/
请求并发数和下载延迟不一样
下载延迟是对每次请求的下载的等待时间
20210928
Python-3反爬虫原理与绕过实战
全面系统了解索引重点
HTTP响应是指服务器端根据客户端的请求返回的信息。HTTP响应由状态码、响应头和响应正文组成。状态码是一个3位数字(如200),它的第一位代表了不同的响应状态。响应状态共有5种,含义如下。
1代表信息响应类,表示接收到请求并且继续处理,这类响应是临时响应。2代表处理成功响应类,表示动作被成功接收、理解和接受
3代表重定向响应类,为了完成指定的动作,必须接受进一步处理。
4代表客户端错误,表示客户请求包含语法错误或者是不能正确执行的请求。
5代表服务器端错误,服务器不能正确执行一个正确的请求
状态码
错误码
20210928
seleniumIDE把网页操作变成代码
https://www.cnblogs.com/lhTest/p/14703892.html
selenium运行出现闪退 需要把其运行文件作为入口 加上
if name=‘main’
https://www.cnblogs.com/thomasbc/p/6650119.html
xhr ajax和javascript区别
postman可以测试影响登陆的原因
https://blog.csdn.net/qq_42348937/article/details/85065104
selenium 获取登录cookies,并添加cookies自动登录
https://npm.taobao.org/mirrors/chromedriver/94.0.4606.61/
webdriver下载地址
20210922
聚创爬虫遇到的问题
1.必须先post登陆,输入账号和密码
2.后续要连续访问网页进行爬取就必须通过get登陆和带cookies 请求
3.但是get登陆需要请求的cookies里面带有一串随机数字串,这个数字串
是在浏览器输入login页面的时候由服务器生成返回的
且这个数字串 通过普通的get方法请求response里面是没有这个数字串的
且这个数字串并不是在本地由javascript生成的
4.怎么办?

网页调试 这些网页的打开也是从上到下按时间顺序的
https://www.runoob.com/js/js-validation.html
看到这里

语句标识符
DOM (Document Object Model)(文档对象模型)是用于访问 HTML 元素的正式 W3C 标准
JavaScript 是 web 开发人员必须学习的 3 门语言中的一门:
HTML 定义了网页的内容
CSS 描述了网页的布局
JavaScript 控制了网页的行为
https://www.runoob.com/css3/css3-borders.html
看到这里
https://www.runoob.com/css/css-display-visibility.html
块级和内连元素的区别
20210916
元素:header,h1,p 等标签
https://www.runoob.com/css/css-border.html
css边框定义
border-style属性用来定义边框的样式

CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。
盒模型允许我们在其它元素和周围元素边框之间的空间放置元素。
盒子模型(Box Model)
Margin(外边距) - 清除边框外的区域,外边距是透明的。
Border(边框) - 围绕在内边距和内容外的边框。
Padding(内边距) - 清除内容周围的区域,内边距是透明的。
Content(内容) - 盒子的内容,显示文本和图像。
a:hover - 当用户鼠标放在链接上时
链接
因此,1em的默认大小是16px。可以通过下面这个公式将像素转换为em:px/16=em
当text-align设置为"justify",每一行被展开为宽度相等,左,右外边距是对齐(如杂志和报纸)。
一般情况下,样式表优先级如下:
(内联样式)Inline style > (内部样式)Internal style sheet >(外部样式)External style sheet > 浏览器默认样式
<head>
<link rel="stylesheet" type="text/css" href="mystyle.css">
</head>
浏览器会从文件 mystyle.css 中读到样式声明,并根据它来格式文档。
https://c.runoob.com/front-end/61/
HTML/CSS/JS 在线工具
html5没看
https://www.runoob.com/html/html-tag-name.html
HTML 标签简写及全称 重点
https://www.runoob.com/html/html-quicklist.html
html标签速查手册重点
https://www.runoob.com/tags/html-urlencode.html
url编码手册重点
HTML 标签原本被设计为用于定义文档内容,如下实例:
样式表定义如何显示 HTML 元素,就像 HTML 中的字体标签和颜色属性所起的作用那样。样式通常保存在外部的 .css 文件中。我们只需要编辑一个简单的 CSS 文档就可以改变所有页面的布局和外观。
html和css的区别

xmlns 在那个范围内起作用
一些变音符号, 如 尖音符 ( ̀) 和 抑音符 ( ́) 。
如果希望正确地显示预留字符,我们必须在 HTML 源代码中使用字符实体(character entities
https://www.runoob.com/try/try.php?filename=tryjs_intro_style
javascript 运行案例
你需要使用源属性(src)。src 指 “source”。源属性的值是图像的 URL 地址。
alt 属性用来为图像定义一串预备的可替换的文本。
frameborder 属性用于定义iframe表示是否显示边框。
设置属性值为 “0” 移除iframe的边框:
表格由 <table> 标签来定义。每个表格均有若干行(由 <tr> 标签定义),每行被分割为若干单元格(由 <td> 标签定义)。字母 td 指表格数据(table data),即数据单元格的内容。数据单元格可以包含文本、图片、列表、段落、表单、水平线、表格等等。
<table border="1">
表格边框宽度
表格的表头使用 <th> 标签进行定义。
无序列表使用 <ul> 标签
同样,有序列表也是一列项目,列表项目使用数字进行标记。 有序列表始于 <ol> 标签。每个列表项始于 <li> 标签。
自定义列表不仅仅是一列项目,而是项目及其注释的组合。
自定义列表以 <dl> 标签开始。每个自定义列表项以 <dt> 开始。每个自定义列表项的定义以 <dd> 开始。
文本域(textarea)、下拉列表、单选框(radio-buttons)、复选框(checkboxes)
预选下拉列表:提前选好了
legend 图例 标题
VS Code 安装教程参考:https://www.runoob.com/w3cnote/vscode-tutorial.html
20210902
RANDOMIZE_DOWNLOAD_DELAY 设置
https://www.cnblogs.com/nuochengze/p/13152156.html
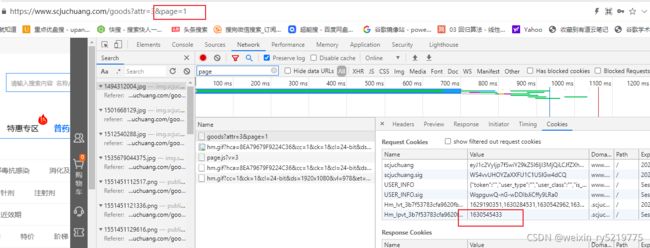
反扒 同一个页面每次请求都会生成一个随机的id放在 cookies 里面
此id 通过javascript 生成
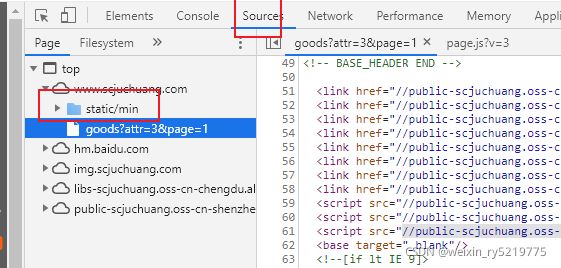
在源代码里面找 static 静态的 javacript 代码 其不在网页源代码里面
找到生成此随机id的js代码

可以打断点一步一步调试 找到生成此id 的代码行 然后 用 javascript ide 先调试 然后 用
pycharm 来执行

展开代码
20210827
scrapy TypeError: No adapter found for objects of type:
如果要你本地保存的话 返回return 为空不允许的
20210816
框架,通俗来说,就是把相似过程的相同特征提取出来。
https://mp.weixin.qq.com/s/QxWE99BFwxz7ptNzhbn-8g
手把手教你用scrapy制作一个小程序 !(附代码)
20210813

获取当前py模块的进程号
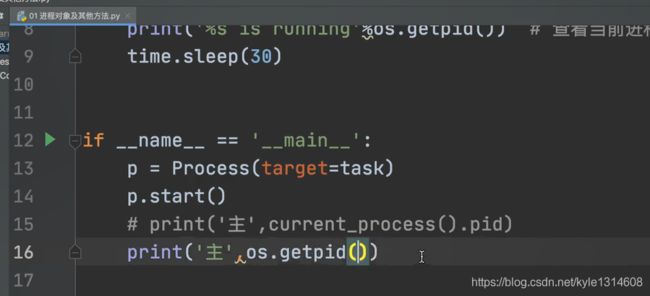

获取父进程的pid pycharm的pid
https://blog.csdn.net/weixin_39965184/article/details/88090876
https://blog.csdn.net/qq_43295136/article/details/86239700
scrapy中item和pipeline和yield和callback用法
https://www.cnblogs.com/vawter/p/5923369.html
user_agent_list
zidbc 是 cookie的字典形式 里面是 键值对
yield scrapy.FormRequest(
method='get',
url='https://www.scjuchuang.com/goods?attr=3&page=1',
# cookies=cookie_jar,
cookies=zidbc,
# meta={ 'cookiejar':zidbc},
callback=self.duqnr)
scrapy.Request 和 scrapy.FormRequest的区别
前者只能request请求
或者可以get 也可以post
cookies=xxx 这种形式 右边只能是字典形式
meta={'cookiejar':xxxx} post 形式的时候用 其右边需要是 cookiejar的形式

cookies里面可能包含多个分量 可以看成是多个键值对
要成功请求最好 是全部分量都包含
第一次post登陆的时候 返回的response的标头里面cookies不一定
含有值,其值可能保存在response.text具体内容里面
20210812
https://www.cnblogs.com/lijunlin-py/p/14922279.html
http://tools.bugscaner.com/cookietocookiejar/
https://blog.csdn.net/tsfy2003/article/details/106247895
https://www.jianshu.com/p/34ec8317f6af
字典和cookiejar的转换
https://www.jianshu.com/p/15278c331434
https://blog.csdn.net/levon2018/article/details/80558108
cookies字符串转字典
https://zhuanlan.zhihu.com/p/68149801
scrapy写入mysql数据库
https://www.cnblogs.com/mzct123/p/5663311.html
get-pip.py的 使用
https://pan.baidu.com/s/13rIiIcpaQpO7iKexhxKoRA
get-pip.py 下载
Python get-pip.py文件
做项目时发现get-pip.py这个文件比较难下载,将此文件分享给各位需要的人!
文件来源:https://bootstrap.pypa.io/get-pip.py
如果链接打不开请至网盘自行下载:链接: https://pan.baidu.com/s/13rIiIcpaQpO7iKexhxKoRA 提取码: r2mb
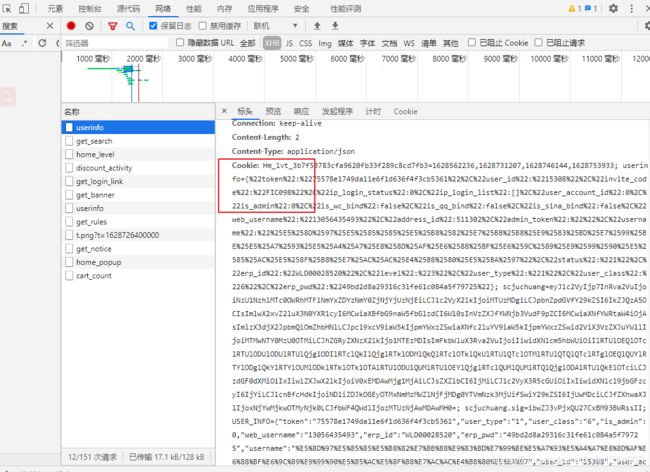
模拟请求 cookies数据要完整
post请求不仅仅用于登录
其他页面请求也可以用post
20210810

多账号爬取cookies的存储和读取
https://www.cnblogs.com/thunderLL/p/7992040.html
cookies 保存
https://www.cnblogs.com/xmwd/p/scrapy_cookies_save_to_file_and_load_from_file.html
https://cloud.tencent.com/developer/article/1562088
https://mp.weixin.qq.com/s/Yvh2_V-BWkKIO5mv35Btlg
scrap cookies登陆
https://www.cnblogs.com/rwxwsblog/p/4572367.html
scrapy写入数据库
20210809
D:\合纵文件\【Python全系列】Python全系列之爬虫scrapy框架及案例\18-20爬虫课件V3.1\爬虫课件V3.1\爬虫课件\file\part04
爬虫简单流程
20210807
https://blog.csdn.net/hihell/article/details/119137580?utm_medium=distribute.pc_feed_v2.none-task-blog-yuanlijihua_tag_v1-2.pc_personrecdepth_1-utm_source=distribute.pc_feed_v2.none-task-blog-yuanlijihua_tag_v1-2.pc_personrec
免费代理ip
20210805
https://blog.csdn.net/kyle1314608/article/details/119422947
Python使用cookie 免密登录了解一下
https://github.com.cnpmjs.org/hhuayuan/process-monitor
进程监控
https://blog.csdn.net/zhaomengszu/article/details/100146408
定时执行爬虫
20210804
https://www.bilibili.com/video/av286623724/?p=5&spm_id_from=pageDriver
https://blog.csdn.net/weixin_37719937/article/details/97417842
cookies免登录
https://www.cnblogs.com/Python-XiaCaiP/p/10268524.html
貌似不起作用
https://natapp.cn/register_2
natapp 免费隧道
https://my.oschina.net/u/4264553/blog/4041192
https://blog.csdn.net/weixin_30834783/article/details/97388084
scrapy爬虫之断点续爬和多个spider同时爬取
scrapy crawl juchuangyy -s JOBDIR=crawls/juchuangyy
https://doc.scrapy.org/en/latest/topics/jobs.html?highlight=jobdir
增量爬取
lxml 合 etree的解析方式
https://zhuanlan.zhihu.com/p/34300202
多级链接跳转

反爬措施
先登陆所有账号,只要cookies不过期 就可以直接爬取数据
cookies里面就包含了token用户登陆信息 直接使用
同一个账号的header和cookies 要对应 且是同一个页面的
params也要对应 同一个页面

cookies 要使用登陆页面的cookies而不是其他页面的
账户频繁登陆会被封
https://www.jianshu.com/p/7911f90ec693
https://blog.csdn.net/sinat_41701878/article/details/80295600 重点
Scrapy随机切换用户代理User-Agent
爬虫如何先同时登陆多个账号
然后每个账号间隔着爬一页
https://www.cnblogs.com/rwxwsblog/p/4578764.html
scrapy同时运行多个实例
可用的爬虫解决方法
阿布云
查询自己的公网ip
myip.top
whoer.net/zh
20210803
ipidea\Trusted Proxies
这两个是商用的 可以试用
400是一种HTTP状态码,告诉客户端它发送了一条异常请求。400页面是当用户在打开网页时,返回给用户界面带有400提示符的页面。其含义是你访问的页面域名不存在或者请求错误。主要分为两种。
1、语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。
2、请求参数有误。
400的主要有两种形式:
1、bad request意思是“错误的请求";
2、invalid hostname意思是"不存在的域名”。
https://ip.jiangxianli.com/?page=1
高可用全球免费代理IP库
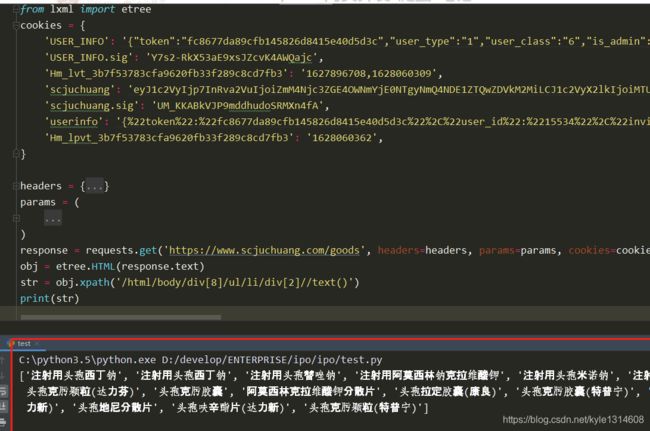
https://www.scjuchuang.com/goods?attr=3&page=1
所需要的东西的明文可能没有 但是其对应的英文可能有
response.json()
response.xpath()
两种方式都可以解析
https://m.imooc.com/wenda/detail/578141
javascript中 ( f u n c t i o n ( ) 的 (function() 的 (function()的代表什么意思哈?
20210802

当找不到post请求的时候 post页面出现之后会消失的
可以把加载速度调慢,


出现需要的页面的时候 点上面的红点停止
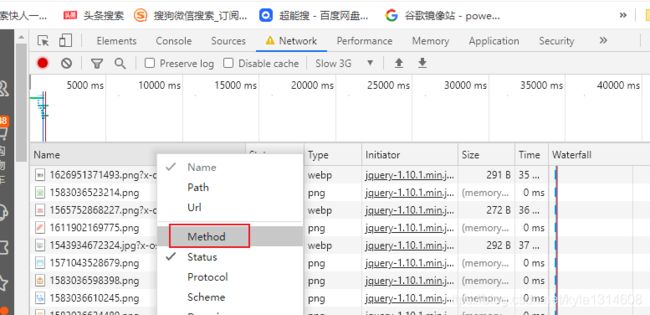
显示method
第一种方法
import scrapy
post_data = {
"username": "18113225168",
"password": "a123456",
"vildCode": ""}
yield scrapy.FormRequest(
url='https://www.scjuchuang.com/api/login',
method='post',
meta={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
"Cookie": "anonymid=j3jxk555-nrn0wh; _r01_=1; _ga=GA1.2.1274811859.1497951251; _de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; [email protected]; depovince=BJ; jebecookies=54f5d0fd-9299-4bb4-801c-eefa4fd3012b|||||; JSESSIONID=abcI6TfWH4N4t_aWJnvdw; ick_login=4be198ce-1f9c-4eab-971d-48abfda70a50; p=0cbee3304bce1ede82a56e901916d0949; first_login_flag=1; ln_hurl=http://hdn.xnimg.cn/photos/hdn421/20171230/1635/main_JQzq_ae7b0000a8791986.jpg; t=79bdd322e760beae79c0b511b8c92a6b9; societyguester=79bdd322e760beae79c0b511b8c92a6b9; id=327550029; xnsid=2ac9a5d8; loginfrom=syshome; ch_id=10016; wp_fold=0"
},
callback=self.login,
formdata=post_data)
scrapy 利用FormRequest 实现post 模拟登陆
##############################
第二种需要数据更少的post请求登陆
import scrapy
def parse(self, response):
#构造post数据
post_data = {
"username":"18030535053",
"userpass": "123456",
"do": "login"
}
yield scrapy.FormRequest.from_response(
response=response,
callback=self.login,
formdata=post_data
)
##########################################
第二种post请求方法
import requests
import json
# 简单爬虫post请求 首先先用这种简单的方式 测试一下是否能够成功
data = {
"username": "18113225168",
"password": "a123456",
"vildCode": ""}
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
cookies={ "Cookie":"anonymid=j3jxk555-nrn0wh; _r01_=1; _ga=GA1.2.1274811859.1497951251; _de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; [email protected]; depovince=BJ; jebecookies=54f5d0fd-9299-4bb4-801c-eefa4fd3012b|||||; JSESSIONID=abcI6TfWH4N4t_aWJnvdw; ick_login=4be198ce-1f9c-4eab-971d-48abfda70a50; p=0cbee3304bce1ede82a56e901916d0949; first_login_flag=1; ln_hurl=http://hdn.xnimg.cn/photos/hdn421/20171230/1635/main_JQzq_ae7b0000a8791986.jpg; t=79bdd322e760beae79c0b511b8c92a6b9; societyguester=79bdd322e760beae79c0b511b8c92a6b9; id=327550029; xnsid=2ac9a5d8; loginfrom=syshome; ch_id=10016; wp_fold=0"
}
response=requests.post('https://www.scjuchuang.com/api/login',headers=headers,cookies=cookies,data=data)
print(response.text)
https://blog.csdn.net/qq_43546676/article/details/89043445
网络爬虫—对于scrapy框架中的Request()、FormRequest()、FormRequest.from_response()做一个小结
错Missing scheme in request url: h(翻译为:请求URL中的丢失整体链接:在h开始的位置)所以需要我们将整个链接放在只有一个元素的list中,使用修改后list.append()将一个链接完整的放置在list[0]中。
post 跳转网址

Yc:
可以登录
Yc:
代码没有写好吧
wang shi yang:
啊 难道是我没设cookies 和headers
wang shi yang:
恩恩
Yc:
headers 是必须条件,不管网站有没有检查headers 都建议带上
wang shi yang:
好的
先用最简单的request方式先测试是否可以用
https://blog.csdn.net/weixin_42081389/article/details/102455273
python爬虫之scrapy 框架学习复习整理二–scrapy.Request(自己提取url再发送请求)
Yc:
看情况,网站爬多少数据会封号,还有封几天
wang shi yang:
大部分情况下 你是怎么配置的 因为你说的这个问题 我们也不清楚
Yc:
测试阶段2-3个就行了 ,具体还要根据实际情况,先用1-2个账号试试多久封一次,封一次是永久封还是封几天,还是不封账号
wang shi yang:
好的 ip地址呢
wang shi yang:
也要先测试吗
Yc:
也要测试
wang shi yang:
如果不测试的话 大部分情况下 你配置的多少
Yc:
1个账号
Yc:
最多两个
wang shi yang:
ip 呢
https://www.abuyun.com/http-proxy/products.html
ip代理厂家
Yc:
https://www.abuyun.com/http-proxy/products.html
Yc:
我一直用的都是这个ip
wang shi yang:
嗯嗯 ip 数量呢
wang shi yang:
你一般配置的多少
Yc:
没有数量限制,这个是转发请求
Yc:
就是你的http请求发送到阿布云的服务器上 阿布云的服务器再去帮你请求目标网站
wang shi yang:
这个网站相当于是代理ip的功能 对吧
wang shi yang:
明白
Yc:
是的
wang shi yang:
可以直接嵌入到scrapy里面吧
wang shi yang:
我的意思是可以直接写在scrapy里面对吧
Yc:
可以

Yc:
接入参考这里
Yc:
https://www.abuyun.com/http-proxy/dyn-manual.html
反扒策略
https://blog.csdn.net/qq_33472765/article/details/80953078
scrapy 保存
https://blog.csdn.net/weixin_30312563/article/details/95904496
https://www.cnblogs.com/dahuag/p/8902043.html
设置代理ip池
设置多用户账号很简单
随机选择用户账号密码就行了
20210730
D:\合纵文件\【Python全系列】Python全系列之爬虫scrapy框架及案例\18-20爬虫课件V3.1\爬虫课件V3.1\爬虫课件/file/part04/4.2.html
scrapy基本步骤路径
工程步骤

所有的cookies
可以用selenium更简单的实现
20210729
![]()
出现502的原因是:对用户访问请求的响应超时造成的
把timeout时间设置长一些
https://blog.csdn.net/qq_33472765/article/details/80953078
scrapy json 保存
https://blog.csdn.net/xudailong_blog/article/details/83545991
scrapy 日志保存
run_scrapy.py: error: Unrecognized output format 'txt'. Set a supported one (('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')) after a colon at the end of the output URI (i.e. -o/-O :) or as a file extension.
scrapy支持的文件保存方式
20210728
scrapy爬虫框架步骤
1.环境配置 尤其是时间
1.post登陆
2.所爬元素xpath的获取
3.下载
4.保存
https://www.cnblogs.com/chengxuyuanaa/p/12981212.html
selector的方法
pip_lx=re.findall(r’“pa”>.*<',qt_leixi[1].extract())
selector的extract() 方法
20210727
https://blog.csdn.net/weixin_45112822/article/details/91910480
python爬虫自动登录github时获取authenticity_token,如果直接调用BeautifulSoup来找到name=authenticity_token的值是行不通的,此时会得到一个不一样的authenticity_token。所以解决办法是直接用xpath来采集路径得到authenticity_token
https://www.cnblogs.com/moyand/p/9047978.html
彻底理解cookie,session,token的使用及原理
爬虫可能遇到的问题
1.cookies需要更换的问题
2.ip地址的更换
20210726
最新scrapy官方文档
https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
Python Scrapy中文教程,Scrapy框架快速入门!
重点 跑起来了
http://c.biancheng.net/view/2027.html
scrapy 官方
https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
Python Scrapy中文教程,Scrapy框架快速入门!
http://c.biancheng.net/view/2027.html
Python3网络爬虫快速入门实战解析
https://blog.csdn.net/c406495762/article/details/78123502
python3爬虫入门实例_循序渐进Python3(十二)–0–爬虫框架入门实例
https://blog.csdn.net/weixin_36277530/article/details/113646722
python3爬虫 重点
https://cuijiahua.com/?s=%E7%88%AC%E8%99%AB&cat=4
https://so.csdn.net/so/search?q=python3%E7%88%AC%E8%99%AB&t=blog&u=c406495762
https://blog.csdn.net/c406495762/article/details/78123502
Python3 爬虫实战教程_w3cschool
https://www.w3cschool.cn/python3/python3-sktl2pwq.html
RUI.Z
AttributeError: module 'urllib' has no attribute 'urlencode'
https://www.cnblogs.com/RUI-Z/p/8617409.html
python3关于urllib中urlopen报错问题的解决
pip3 install urllib2 ERROR: Could not find a version that satisfies the requirement urllib2 (from versions: none)
AttributeError: 'module' object has no attribute 'urlopen'
https://blog.csdn.net/pythonniu/article/details/51855035
https://www.runoob.com/html/html-examples.html html 实例
https://www.runoob.com/tags/html-reference.html
HTML 参考手册- (HTML5 标准) 各种标签
https://www.runoob.com/html/html-basic.html
这是一个链接
尖括号 href 是属性
相当于注释?

复合标签

属性和对应的值

css class 相当于别名
html 整个网页布局 以及一些网页静态属性的设置
css 动态属性的设置,更加灵活
javascript 实现更高级或者说是任何功能
XML 被设计用来传输和存储数据,其焦点是数据的内容。
HTML 被设计用来显示数据,其焦点是数据的外观。
自我描述性:整个文件就是一篇文章

xml中的属性和文本
XML 属性值必须加引号
与 HTML 类似,XML 元素也可拥有属性(名称/值的对)。
在 XML 中,XML 的属性值必须加引号。
请研究下面的两个 XML 文档。 第一个是错误的,第二个是正确的:
Tove
Jani
date 是名称 12/11/2007是属性值

实体引用

元素名
XML 命名规则
XML 元素必须遵循以下命名规则:
名称可以包含字母、数字以及其他的字符
名称不能以数字或者标点符号开始
名称不能以字母 xml(或者 XML、Xml 等等)开始
名称不能包含空格
可使用任何名称,没有保留的字词。

元素和属性
针对元数据的 XML 属性
有时候会向元素分配 ID 引用。这些 ID 索引可用于标识 XML 元素,它起作用的方式与 HTML 中 id 属性是一样的。这个实例向我们演示了这种情况:
在此我们极力向您传递的理念是:元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。
元数据和属性
ID索引
由于DOM“一切都是节点(everything-is-a-node)”,XML树的每个 Document、Element、Text 、Attr和Comment都是 DOM Node。
由上面例子可知, DOM 实质上是一些节点的集合。由于文档中可能包含有不同类型的信息,所以定义了几种不同类型的节点,如:Document、Element、Text、Attr 、CDATASection、ProcessingInstruction、Notation 、EntityReference、Entity、DocumentType、DocumentFragment等。