Focal Loss的理解以及在多分类任务上的使用(Pytorch)
最近在做遥感影像分割,涉及到多个类别,建筑、道路、水体、植被、耕地等等。发现各类别之间占比特别不均衡,会影响最终精度,尝试过使用加权交叉熵,权重计算参考《中值频率平衡:图像分割中计算类别权重的方法》,精度有所提升,但是还是不能满足要求,后来就想试试Focal Loss,发现效果提升明显,这里也从头梳理一下Focal Loss。
个人觉的要真正理解Focal Loss,有三个关键点需要清楚,分别对应基础公式,超参数α,超参数γ。
一、二分类(sigmoid)和多分类(softmax)的交叉熵损失表达形式是有区别的。
二、理解什么是难分类样本,什么是易分类样本?搞清难易分类样本是搞清楚Focal Loss中的超参数γ作用的关键。
三、负样本的α值到底该是0.25还是0.75呢?这个问题对应Focal Loss中的超参数α的调参。
理解上面三点应该就能搞清楚二分类Focal Loss的基本思想,然后就可以推广到多分类问题上。
理解关键点一:基础公式
二分类和多分类的交叉熵的区别具体可以参考文章《一文搞懂交叉熵损失》
1.1、二分类交叉熵
在做二分类的任务时,一般是用sigmoid作为最后的激活函数,输出只有一个代表样本为正的概率值p,二分类非正即负,所以样本为负的概率值为1-p。
则以sigmoid作为激活函数的二分类任务交叉熵损失的计算公式为:
C E L = − y ∗ l o g ( p ) − ( 1 − y ) ∗ l o g ( 1 − p ) CEL=-y*log(p) -(1-y)*log(1-p) CEL=−y∗log(p)−(1−y)∗log(1−p)
其中 y y y是实际标签,正样本为1,负样本为0,p是sigmoid激活函数的输出值。
1.2、多分类交叉熵
在做多分类的时候,一般是以softmax作为最后的激活函数的,输出有多个值,对应每个分类的概率值,和为1。
则以sofmax作为激活函数的多分类任务的交叉熵损失计算公式为
C E L = − ∑ 0 C − 1 y i ∗ l o g ( p i ) = − l o g ( p c ) CEL=-\sum_{0}^{C-1}y_{i}*log(p_{i})=-log(p_{c}) CEL=−0∑C−1yi∗log(pi)=−log(pc)
其中 p c p_{c} pc表示softmax激活函数输出结果中第c类的对应的值。
注意:论文中是基于以sigmoid为激活函数来作为二分类交叉熵损失的。我在最开始学Focal Loss的时候老是将sigmoid和softmax混着看,一会用sigmoid来套公式,一会用softmax来套公式,很容易把自己搞蒙。
文章的备注里也指出可以很容易将Focal Loss应用于多分类,为了简单起见,文章中关注的是二分类情况。

理解关键点二: p t p_{t} pt和超参数γ
2.1 p t p_{t} pt
论文将交叉熵损失公式做了进一步的简化:
C E ( p , y ) = { − l o g ( p ) i f y = 1 − l o g ( 1 − p ) o t h e r w i s e CE(p,y)=\left\{\begin{matrix} & -log(p)& if\quad y=1\\ & -log(1-p)& otherwise \end{matrix}\right. CE(p,y)={−log(p)−log(1−p)ify=1otherwise
其中
p t = { p i f y = 1 1 − p o t h e r w i s e p_{t}=\left\{\begin{matrix} &p& if\quad y=1\\ &1-p& otherwise \end{matrix}\right. pt={p1−pify=1otherwise
所以:
C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE(p,y)=CE(p_{t})=-log(p_{t}) CE(p,y)=CE(pt)=−log(pt)
这里 p t p_{t} pt的理解比较关键。 p t p_{t} pt的大小实际能反映出样本难易分类的程度。
举个例子,当样本为正样本(y=1)时,如果模型预测的p=0.3,表示模型预测该样本为负样本,模型预测错误, p t p_{t} pt=0.3,如果模型预测的p=0.8,表示模型预测该样本为正样本,模型预测正确, p t p_{t} pt=0.8。当样本为负样本(y=0)时,如果模型预测的p=0.3,表示模型判断该样本为负样本,判断正确, p t p_{t} pt=1-p=0.7。如果模型输出的p=0.8,表示模型判断该样本为正样本,模型预测错误, p t p_{t} pt=1-p=0.2。对应下表:
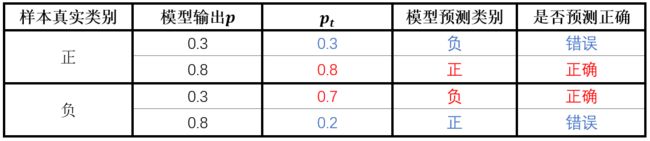
可以看到,不管是正样本还是负样本,模型预测正确时 p t p_{t} pt都很大,预测错误时 p t p_{t} pt 值很小,所以 p t p_{t} pt值代表了模型对样本预测正确的概率。
接下来看论文中一上来就给的一张图。
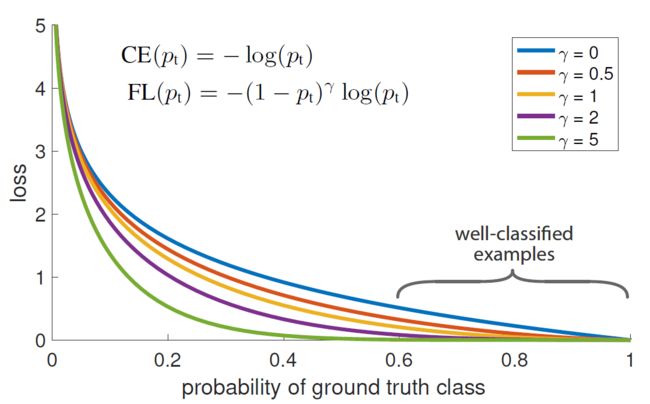
横坐标是 p t p_{t} pt,可以看出作者指出 p t p_{t} pt ∈ \in ∈(0.6,1)区间的样本为well-classified examples(易分类样本)。
针对上面的例子再啰嗦几句,对于一个正样本,如果模型得到的预测的p总是在0.5以上,则说明该样本很容易被分类正确,所以是易分类样本,此时pt=p,pt也总是在0.5以上,如果模型得到的预测的p总是在0.5以下,则说明该样本很难被正确分类,所以为难分类样本,此时pt也总是在0.5以下;同理对于一个负样本,模型预测的p很容易在0.5以下,表明模型很容易将样本正确分类,所以是易分类样本,pt=1-p,pt总是在0.5以上,如果模型得到的预测的p总是在0.5以上,则说明针对这类样本模型总是分类错误,所以是难分类样本,pt=1-p,pt总是在0.5以下。
总结一下,易分类样本的特征: p t p_{t} pt>0.5;难分类样本特征: p t p_{t} pt<0.5 , p t p_{t} pt值越大,表示预测越准确。
2.2 γ参数
上一节说过 p t p_{t} pt代表了样本难易分类的程度。在训练模型的时候,我们希望模型更加关注难分类样本,所以会考虑将难分类样本在损失函数中的比重加大。作者在原始的二分类交叉函数中增加了一项 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ,对原始交叉熵损失做了衰减。
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) FL(p_{t})=-(1-p_{t})^{\gamma }log(p_{t}) FL(pt)=−(1−pt)γlog(pt)
经过对 p t p_{t} pt的分析可知,难分类样本的 p t p_{t} pt值小, 1 − p t 1-p_{t} 1−pt大;易分类样本的 p t p_{t} pt值大, 1 − p t 1-p_{t} 1−pt值小。不管是难分类还是易分类样本,Focal Loss相对于原始的CE loss都做了衰减,只是难分类样本相对于易分类样本衰减的少。这里的超参数γ决定了衰减的程度,从上图可以看出γ越大,损失衰减越明显。
还是上面的例子,我们取 γ {\gamma} γ=2,当样本为正样本(y=1)时,如果模型预测的 p = 0.3 p=0.3 p=0.3,则 p t = 0.3 p_{t}=0.3 pt=0.3, ( 1 − p t ) γ = ( 1 − 0.3 ) 2 = 0.49 (1-p_{t})^{\gamma}=(1-0.3)^2=0.49 (1−pt)γ=(1−0.3)2=0.49, 相当于原始的CE Loss的0.49倍,如果模型预测的 p = 0.8 p=0.8 p=0.8,则 p t = 0.8 p_{t}=0.8 pt=0.8, ( 1 − p t ) γ = ( 1 − 0.8 ) 2 = 0.04 (1-p_{t})^{\gamma}=(1-0.8)^2=0.04 (1−pt)γ=(1−0.8)2=0.04, 相当于原始的CE Loss的0.04倍;当样本为负样本(y=0)时,如果模型预测的 p = 0.3 p=0.3 p=0.3,则 p t = 1 − p = 0.7 p_{t}=1-p=0.7 pt=1−p=0.7, ( 1 − p t ) γ = ( 1 − 0.7 ) 2 = 0.09 (1-p_{t})^{\gamma}=(1-0.7)^2=0.09 (1−pt)γ=(1−0.7)2=0.09, 相当于原始的CE Loss的0.09倍,如果模型输出的 p = 0.8 p=0.8 p=0.8,则 p t = 1 − p = 0.2 p_{t}=1-p=0.2 pt=1−p=0.2, ( 1 − p t ) γ = ( 1 − 0.2 ) 2 = 0.64 (1-p_{t})^{\gamma}=(1-0.2)^2=0.64 (1−pt)γ=(1−0.2)2=0.64, 相对于原始的CE Loss的0.64倍。
上面这个例子中,对于易分类样本,Focal Loss变为原来CE Loss的0.04倍、0.09倍,对于难分类样本,Focal Loss变为原来CE Loss的0.49倍、0.64倍,可以看出Focal Loss中,相较于难分类样本,易分类样本衰减的更多,从而变相的增加了难分类样本的权重。
理解关键点三:超参数 α t {\alpha_{t}} αt
我们在做实际模型训练的时候,经常会遇到各类样本数量比例不平衡的情况,对于二分类任务,负样本的数量远远多于正样本,导致模型更多关注在负样本上,忽略正样本。因此在使用交叉熵损失的时候通常会增加一个平衡参数用来调节正负样本的比重。
C E ( p t ) = − α t l o g ( p t ) CE(p_{t})=-{\alpha_{t}}log(p_{t}) CE(pt)=−αtlog(pt)
α t {\alpha_t} αt的定义和 p t p_{t} pt类似,应该是
α t = { α i f y = 1 1 − α o t h e r w i s e {\alpha_{t}}=\left\{\begin{matrix} &{\alpha}& if\quad y=1\\ &1-{\alpha}& otherwise \end{matrix}\right. αt={α1−αify=1otherwise
可以知道 α {\alpha} α代表了正样本的权重, 1 − α 1-{\alpha} 1−α为负样本的权重,这两个值应该是正负样本数量比例的反比,如正样本数量占0.2,负样本数量占0.8,那么 α {\alpha} α=0.8,1- α {\alpha} α=0.2(可以微调),以此来达到平衡正负样本的目的,这样理解看来是没有问题的。
借鉴上面的思想,作者在Focal Loss中也加入了 α t {\alpha_{t}} αt参数:
论文中Focal Loss的最终表示公式为:
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_{t})=-{\alpha_{t}}(1-p_{t})^{\gamma }log(p_{t}) FL(pt)=−αt(1−pt)γlog(pt)
作者指出加入 α t {\alpha_{t}} αt平衡参数比不加时精度有所提升。并且给出了实验参数,在作者的实验中当 α {\alpha} α=0.25, γ {\gamma} γ=2时精度最高。这时就有一个问题了, α {\alpha} α代表计算损失时对应正样本的调节权重,而正样本数量一般要小于负样本的数量,所以正样本的权重应该大于负样本的权重,那作者实验中最佳的正样本权重( α {\alpha} α=0.25)为啥比负样本权重(1- α {\alpha} α=0.75)还要低呢?明明负样本的数量已经远远大于正样本的数量了,为啥还要增加损失函数中负样本的比重呢?这不是矛盾吗?
其实作者在论文里给出了解释。有两处:
1、4.1节 Focal Loss小节


这段有两点信息:
a) α {\alpha} α代表了样本数量较少的类的权重,也就是绝大多数情况下的正样本。
b) α {\alpha} α和 γ {\gamma} γ是相互作用的,随着 γ {\gamma} γ的增加, α {\alpha} α应该稍微降低。
2、5.1节 Focal Loss小节第二段

这段话有三点意思
a) 低 α {\alpha} α 对应高 γ {\gamma} γ。
b)负样本易分类,权重已经被 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ降低很多了,所以无需给正样本再增加权重。
c)Focal Loss中 γ {\gamma} γ占主要地位。
总结:
*在Focal Loss中 α {\alpha} α对应的是正样本(占比少的类)的权重,且一般值较小。
*在Focal Loss中 γ {\gamma} γ占主导地位。随着 γ {\gamma} γ的增大, α {\alpha} α要相应的减小。
多分类
接下来我们把Focal Loss推广到多分类任务中,看看多分类中的Focal Loss公式应该是怎样的。
首先我们再来回顾一下二分类的Focal Loss的推导过程,其实就是在CE Loss的基础上增加了两项因子, α t {\alpha}_{t} αt和 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ,其中 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ为用来调整难易分类样本的比重, α t {\alpha}_{t} αt对经过 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ系数衰减后的损失再进行调整。那么这里就有一个问题了: α t {\alpha}_{t} αt和 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ在多分类任务中该怎么表示呢?
让我们先回到最初的二分类交叉熵损失中(此时激活函数为sigmoid):
C E L = − y ∗ l o g ( p ) − ( 1 − y ) ∗ l o g ( 1 − p ) CEL=-y*log(p) -(1-y)*log(1-p) CEL=−y∗log(p)−(1−y)∗log(1−p)
对应的Focal Loss为
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_{t})=-{\alpha_{t}}(1-p_{t})^{\gamma }log(p_{t}) FL(pt)=−αt(1−pt)γlog(pt)
将 α t , p t {\alpha_t},p_t αt,pt展开得到
F L ( p t ) = − α ∗ ( 1 − p ) γ ∗ y ∗ l o g ( p ) − ( 1 − α ) ∗ p γ ∗ ( 1 − y ) l o g ( 1 − p ) FL(p_{t})=-{\alpha}*(1-p)^{\gamma }*y*log(p)-(1-{\alpha})*p^{\gamma }*(1-y)log(1-p) FL(pt)=−α∗(1−p)γ∗y∗log(p)−(1−α)∗pγ∗(1−y)log(1−p)
还是二分类,我们把激活函数换成softmax,我们知道softmax输出的是每个类的概率值,和为1。使用softmax时样本的标签为onehot形式( y 1 y_1 y1, y 2 y_2 y2),二分类情况下,第1类标签为(1,0),第二类标签为(0,1)。假设softmax输出为( p 1 p_1 p1, p 2 p_2 p2),分别对应1、2类的概率。
则以softmax为激活的二分类的交叉熵损失为
C E L s o f t m a x = − y 1 ∗ l o g ( p 1 ) − y 2 ∗ l o g ( p 2 ) CEL_{softmax}=-y_1*log(p_1) -y_2*log(p_2) CELsoftmax=−y1∗log(p1)−y2∗log(p2)
我们先加入衰减参数 γ {\gamma} γ
F L s o f t m a x = − ( 1 − p 1 ) γ ∗ y 1 ∗ l o g ( p 1 ) − ( 1 − p 2 ) γ ∗ y 2 l o g ( p 2 ) FL_{softmax}= -(1-p_{1})^{\gamma }*y_{1}*log(p_{1})-(1-p_2)^{\gamma }*y_2log(p_2) FLsoftmax=−(1−p1)γ∗y1∗log(p1)−(1−p2)γ∗y2log(p2)
再加入 α {\alpha} α,第一类为 α 1 {\alpha_1} α1,第二类为 α 2 {\alpha_2} α2:
F L s o f t m a x = − α 1 ∗ ( 1 − p 1 ) γ ∗ y 1 ∗ l o g ( p 1 ) − α 2 ∗ ( 1 − p 2 ) γ ∗ y 2 l o g ( p 2 ) FL_{softmax}= -{\alpha_{1}}*(1-p_{1})^{\gamma }*y_{1}*log(p_{1})-{\alpha_2}*(1-p_2)^{\gamma }*y_2log(p_2) FLsoftmax=−α1∗(1−p1)γ∗y1∗log(p1)−α2∗(1−p2)γ∗y2log(p2)
因为标签是onehot形式,某类样本的标签中的值只有在对应位置上为1,其余都为0,所以上式可以写成
F L s o f t m a x = − α c ( 1 − p c ) γ l o g ( p c ) FL_{softmax}=-{\alpha_{c}}(1-p_{c})^{\gamma}log(p_{c}) FLsoftmax=−αc(1−pc)γlog(pc)
其中 α c {\alpha_{c}} αc表示第c类样本的权重, p c p_{c} pc表示softmax输出的第 c c c类的概率值。
现在我们来比较一下激活函数分别为sigmoid和softmax的Focal Loss公式
F L s i g m o i d = − α t ( 1 − p t ) γ l o g ( p t ) FL_{sigmoid}=-{\alpha_{t}}(1-p_{t})^{\gamma}log(p_{t}) FLsigmoid=−αt(1−pt)γlog(pt)
F L s o f t m a x = − α c ( 1 − p c ) γ l o g ( p c ) FL_{softmax}=-{\alpha_{c}}(1-p_{c})^{\gamma}log(p_{c}) FLsoftmax=−αc(1−pc)γlog(pc)
观察这两个公式, F L s i g m o i d FL_{sigmoid} FLsigmoid中的 t t t和 F L s o f t m a x FL_{softmax} FLsoftmax中的 c c c,对应的标签的值都是1。
当类别大于二类激活函数是softmax时,和以softmax为激活函数的二分类Focal Loss公式是一样的:
F L s o f t m a x = − α c ( 1 − p c ) γ l o g ( p c ) FL_{softmax}=-{\alpha_{c}}(1-p_{c})^{\gamma}log(p_{c}) FLsoftmax=−αc(1−pc)γlog(pc)
pytorch代码
二分类
class Focal_Loss():
"""
二分类Focal Loss
"""
def __init__(self,alpha=0.25,gamma=2):
super(Focal_Loss,self).__init__()
self.alpha=alpha
self.gamma=gamma
def forward(self,preds,labels):
"""
preds:sigmoid的输出结果
labels:标签
"""
eps=1e-7
loss_1=-1*self.alpha*torch.pow((1-preds),self.gamma)*torch.log(preds+eps)*labels
loss_0=-1*(1-self.alpha)*torch.pow(preds,self.gamma)*torch.log(1-preds+eps)*(1-labels)
loss=loss_0+loss_1
return torch.mean(loss)
多分类
class Focal_Loss():
def __init__(self,weight,gamma=2):
super(Focal_Loss,self).__init__()
self.gamma=gamma
self.weight=weight
def forward(self,preds,labels):
"""
preds:softmax输出结果
labels:真实值
"""
eps=1e-7
y_pred =preds.view((preds.size()[0],preds.size()[1],-1)) #B*C*H*W->B*C*(H*W)
target=labels.view(y_pred.size()) #B*C*H*W->B*C*(H*W)
ce=-1*torch.log(y_pred+eps)*target
floss=torch.pow((1-y_pred),self.gamma)*ce
floss=torch.mul(floss,self.weight)
floss=torch.sum(floss,dim=1)
return torch.mean(floss)
个人经验分享
1、在使用focal loss时γ占主导因素,同时γ是用来控制难易分类样本的,所以当数据中难分类样本较多时,γ可以设置的大一些。
2、如果要分类的目标特征比较明显(建筑、道路),最好不要用Focal Loss。
参考
1、《Focal Loss for Dense Object Detection》论文。无论什么算法,最重要的还是要看原始论文,其他任何博客都掺入了作者自己的理解,只能作为辅助。
2、《Demystifying Focal Loss I: A More Focused Cross Entropy Loss》英文博客,从这里理解了pt的实际含义。