3D点云目标检测:MPPNet网络训练waymo数据集
MPPNet网络训练waymo数据集
- 一、waymo数据预处理
-
- 1.1、waymo数据简介
- 1.2、 waymo数据集预处理
- 二、训练centerpoint网络
- 三、训练mppnet网络
- 四、训练结果
- 五、注意事项
在这里记录一下MPPNet网络训练waymo数据的过程。MPPNet是一个使用连续帧点云进行3D目标检测的网络。
paper:https://arxiv.org/abs/2205.05979
代码地址:https://github.com/open-mmlab/OpenPCDet
一、waymo数据预处理
1.1、waymo数据简介
waymo数据集版本为v1.4.0,其中训练集包括798个场景,验证集有202个场景,测试集有150个场景,每个场景是连续的大概20s左右的数据,每秒10帧,每个场景200帧左右,每个场景用一个tfrecord文件保存。

注意:验证集的版本要新一点,旧的的验证集合没有目标的点数,无法区分level1和level2
1.2、 waymo数据集预处理
这里主要是解析waymo数据集得到目标检测所用到的点云和真实标签。
首先将所有的场景即tfrecord数据放在同一个路径下,该路径下有两个文件夹,
![]()
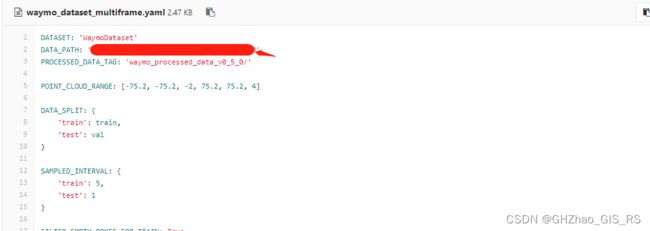
ImageSets文件夹中是train.txt和val.txt,保存的是场景名。raw_data文件夹里面是1000个tfrecord文件。然后需要将输入路径修改为自己的数据的路径,yaml文件为cfgs/dataset_configs/waymo_dataset_multiframe.yaml,把DATA_PATH改为自己的数据集路径。
执行下面的命令
安装waymo数据处理工具
pip3 install waymo-open-dataset-tf-2-5-0 --user
开始处理waymo数据
python -m pcdet.datasets.waymo.waymo_dataset --func create_waymo_infos \
--cfg_file tools/cfgs/dataset_configs/waymo_dataset_multiframe.yaml
注意事项:
1):如果训练模型时要使用gt_sampling增强策略,预处理时要求机器内存大于200G,越大越好,waymo有20多万的数据量,我在做的时候使用80G内存的机器都内存报错,最后用了320G内存的机器才正常处理完,原因是程序会把gt_sampling使用的样本库写到一个pkl文件中,这个文件只有在所有数据处理完才会保存,之前一直存在内存中,这样内存占用会越来愈大,而且不要使用share_memory策略,虽然代码里说用share_memory会提升速度,但是我使用的时候还是会报错,关掉这个功能就能正常跑通,但是处理时间真的很慢。
2):如果实在没有这么大内存的机器,还想跑通waymo数据集的同学可以选择关掉gt_sampling策略,即训练模型的时候不使用gt_sampling增强,这样需要很小的内存就能把预处理跑完,修改方式如下,还是在刚才的yaml文件,在DATA_AUGMENTOR结点的DISABLE_AUG_LIST子结点中加入gt_sampling,但是这样的坏处时模型的精度会降低很多,后面会在实验结果中给出两种训练的精度。
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['placeholder','gt_sampling']
AUG_CONFIG_LIST:
- NAME: gt_sampling
USE_ROAD_PLANE: False
DB_INFO_PATH:
- waymo_processed_data_v0_5_0_waymo_dbinfos_train_sampled_1_multiframe_-4_to_0.pkl
USE_SHARED_MEMORY: False # set it to True to speed up (it costs about 50GB? shared memory)
DB_DATA_PATH:
- waymo_processed_data_v0_5_0_gt_database_train_sampled_1_multiframe_-4_to_0_global.npy
解析后的结果包括以下几个文件夹

实际点云数据存在waymo_processed_data_v0_5_0文件件中以每个场景命名的子文件夹中,每一帧存储为一个npy文件,标签存储在pkl文件中。

二、训练centerpoint网络
MPPNet网络是two-stage网络,先单独训练第一个stage网络得到预选框,论文选用的是centerpoint网络,而且是将4帧叠加后做为单帧点云的输入,叠加方式就是使用自车的pose信息,将历史帧的点云坐标转换到当前帧的坐标系下后合并。效果如下:
不做坐标转换直接拼接
做完坐标转换再拼接
训练命令:
bash scripts/dist_train.sh 8 --cfg_file cfgs/waymo_models/centerpoint_4frames.yaml
我这里使用8张V100(32G),不使用gt_sampling策略训练的7天,使用gt_sampling策略训练了9天。
三、训练mppnet网络
训练完centerpoint后需要用得到的模型将训练集和验证集都推理一遍,保存推理结果作为第二阶段网络的预选框proposal。
推理训练集
bash scripts/dist_test.sh 8 --cfg_file cfgs/waymo_models/centerpoint_4frames.yaml \
--ckpt ../output/waymo_models/centerpoint_4frames/default/ckpt/checkpoint_epoch_36.pth \
--set DATA_CONFIG.DATA_SPLIT.test train
结果存储在eval/epoch_36/train/default/result.pkl中
推理验证集
bash scripts/dist_test.sh 8 --cfg_file cfgs/waymo_models/centerpoint_4frames.yaml \
--ckpt ../output/waymo_models/centerpoint_4frames/default/ckpt/checkpoint_epoch_36.pth \
--set DATA_CONFIG.DATA_SPLIT.test val
结果存储在eval/epoch_36/val/default/result.pkl中
训练MPPNet网络, DATA_CONFIG.ROI_BOXES_PATH.train 指定训练集的推理结果,DATA_CONFIG.ROI_BOXES_PATH.test验证集的推理结果
bash scripts/dist_train.sh 8 --cfg_file cfgs/waymo_models/mppnet_4frames.yaml --batch_size 32 \
--set DATA_CONFIG.ROI_BOXES_PATH.train ../output/waymo_models/centerpoint_4frames/default/eval/epoch_36/train/default/result.pkl \
DATA_CONFIG.ROI_BOXES_PATH.test ../output/waymo_models/centerpoint_4frames/default/eval/epoch_36/val/default/result.pkl
四、训练结果
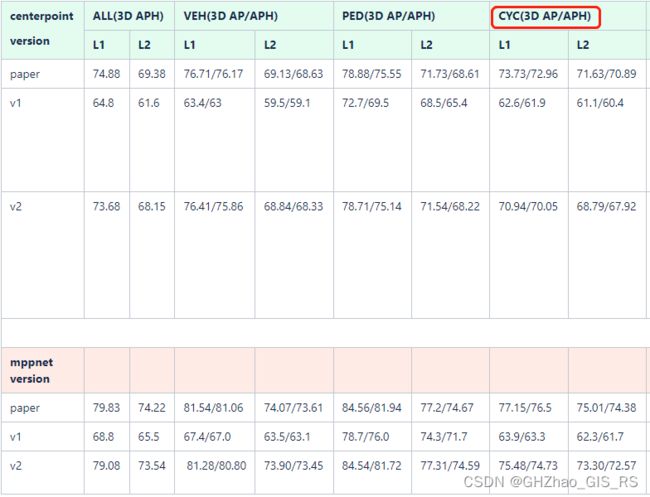
下图是我自己复现MPPNet的结果,v1是不使用gt_sampling数据增强结果,可以看到精度相比论文差距比较大,v2是使用gt_sampling的结果,出CYC类相差2个点外,其他两类基本持平。
五、注意事项
1、不使用gt_sampling增强策略精度差距很大。
2、使用gt_sampling策略在做数据预处理时需要特别大的内存,最好是200G以上,不然无法生产gt_sampling需要的npy文件。
3、使用的数据版本尽可能新,在做精度评价的时候会根据目标包含的点数将目标划分为level1和level2,初版的数据集没有记录目标的点数。