linux内核分析与应用 -- 进程与线程(下)
1.3 进程的调度
在一个 CPU 中,同一时刻最多只能支持有限的进程或者线程同时运行(这取决于 CPU 核数量),但是在一个运行的操作系统上往往可以运行很多进程,假如运行的进程占据 CPU 进程时间很长,就有可能让其他进程饿死。为了解决这种问题,操作系统引入了进程调度器来进行进程的切换,目的是轮流让其他进程获取 CPU 资源。
1.3.1 进程调度机制的架构
在每个进程运行完毕时,系统可以进行调度的工作,但是系统不可能总是在进程运行完才调度,不然其他进程估计还没被调度就饿死了。系统还需要一个重要的机制:中断机制,来周期性地触发调度算法进行进程的切换。
Linux 进程的切换是通过 schedule 函数来完成的,其主要逻辑由 _schedule 函数实现:
static void __sched notrace __schedule(bool preempt)
{
// 阶级1
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
cpu = smp_processor_id(); // 获取当前 CPU 的 id
rq = cpu_rq(cpu);
rcu_note_context_switch(); // 标识当前 CPU 发生任务切换,通过 RCU 更新状态
prev = rq->curr;
…
//阶段2
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
// 阶段3
if (task_on_rq_queued(prev))
update_rq_clock(rq);
// 阶段4
next = pick_next_task(rq, prev); // 选取下一个将要执行的进程
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->clock_skip_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
…
// 阶段5
rq = context_switch(rq, prev, next); //进行进程上下文切换
cpu = cpu_of(rq);
} else {
lockdep_unpin_lock(&rq->lock);
raw_spin_unlock_irq(&rq->lock);
}
balance_callback(rq);
}
_schedule 执行过程主要分为以下几个阶段:
1)关闭内核抢占,初始化一部分变量。获得当前 CPU 的 ID 号,并赋值给局部变量 CPU。使 rq 指向 CPU 对应的运行队列(runqueue)。标识当前 CPU 发生任务切换,通知 RCU 更新状态,如果当前 CPU 处于 rcu_read_lock 状态,当前进程将会放入 rnp->blkd_tasks 阻塞队列,并呈现在 rnp->gp_tasks 链表中。(关于 RCU 机制,在第2章中介绍)。关闭本地中断,获取所要保护的运行队列(runqueue)的自旋锁(spinlock),为查找可运行进程做准备。
2)检查 prev 的状态。如果不是可运行状态,而且没有在内核态被抢占,就应该从运行队列中删除 prev 进程。但是,如果它是非阻塞挂起信号,而且状态为 TASK_INTER-RUPTIBLE,函数就把该进程的状态设置为 TASK_RUNNING,并将它插入到运行队列。
3)task_on_rq_queued(prev)将 pre 进程插入到运行队列的队尾。
4)pick_next_task 选取下一个将要执行的进程。
5)context_switch(rq,prev,next)进行进程上下文切换。
通过上述步骤可以发现,调度无非就是找一个已有的进程,然后进行上下文切换,并让它执行而已。
注意
挑选 next 进程的过程相对复杂,分析起来也比较麻烦,限于篇幅和时间有限,暂时不介绍具体挑选的调度算法实现,这里仅介绍 Linux 调度的架构,图1-10是 Linux 的调度架构图。

图1-10 调度的架构图
Linux 调度架构的核心概念如下:
1)rq:可运行的队列,每个 CPU 对应一个,包含自旋锁、进程数量、用于公平调度的 CFS 信息结构、当前正在运行的进程描述符等。实际的进程队列用红黑树来维护(通过 CFS 信息结构来访问)。
2)cfs_rq:cfs 调度的运行队列信息,包含红黑树的根结点、正在运行的进程指针、用于负载均衡的叶子队列等。
3)sched_entity:把需要调度的东西抽象成调度实体,调度实体可以是进程、进程组、用户等。这里包含负载权重值、对应红黑树结点、虚拟运行时 vruntime 等。
4)sched_class:把调度策略(算法)抽象成调度类,包含一组通用的调度操作接口,将接口和实现分离。你可以根据这组接口实现不同的调度算法,使得一个 Linux 调度程序可以有多个不同的调度策略。
1.3.2 进程切换的原理
在挑选完 next 进程之后,就开始准切换到 next 进程。
可以将进程理解为正在利用 CPU 工作的任务。因为在系统中同时运行的进程有很多,CPU 不能仅仅被同一个进程使用,所以,这时候就需要进程切换机制,另外,假如某进程的工作大部分为 I/O 操作,占用 CPU 空跑会导致资源浪费,这样的进程需要主动放弃 CPU。
需要进程切换的场景有以下几种:
该进程分配的 CPU 时间片用完。
该进程主动放弃 CPU(例如 IO 操作)。
某一进程抢占 CPU 获得执行机会。
Linux 并没有使用 x86 CPU 自带的任务切换机制,而是通过手工的方式实现了切换,切换过程通过以下 switch_to 宏来定义:
#define switch_to(prev, next, last)
do {
unsigned long ebx, ecx, edx, esi, edi;
asm volatile("pushfl\n\t" // 步骤1
"pushl %%ebp\n\t" // 步骤2
"movl %%esp,%[prev_sp]\n\t" // 步骤3
"movl %[next_sp],%%esp\n\t" // 步骤4
"movl $1f,%[prev_ip]\n\t" // 步骤5
"pushl %[next_ip]\n\t" // 步骤6
__switch_canary
"jmp __switch_to\n" // 步骤7
"1:\t"
"popl %%ebp\n\t" // 从栈恢复 EBP
"popfl\n" // 从栈恢复 flags
// asm 内嵌汇编的输出参数
[prev_sp] "=m" (prev->thread.sp),
[prev_ip] "=m" (prev->thread.ip),
"=a" (last),
"=b" (ebx), "=c" (ecx), "=d" (edx),
"=S" (esi), "=D" (edi)
__switch_canary_oparam
// asm 内嵌汇编的输入参数
[next_sp] "m" (next->thread.sp),
[next_ip] "m" (next->thread.ip),
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
"memory");
} while (0)
该切换过程分为以下几个步骤:
1)pushfl 保存 eflags 寄存器中的数据到进程本身的堆栈。
2)保存堆栈指针 ebp 寄存器地址。
3)把堆栈寄存器 esp 的地址保存到 prev->thread.sp 中。
4)把 next->thread.sp 的地址送入到 sp 寄存器中,这个时候其实已经跑在新的 next 进程的上下文中了。
5)把当前的 eip 地址保存到 prev->thread.ip 中。
6)pushfl 把 next->thread.ip 的地址压入到当前堆栈中。
7)通过 jmp_switch_to 指令,不管 _switch_to 做了什么,ret 返回地址之前已经被设置成了 next->thread.ip 的地址,所以将会执行之前在 copy_thread_tls 中设置的 ret_from_fork。
通过这个过程,可以了解到在 Linux 中,我们并没有对 TSS 进行特殊处理,而是每个 CPU 持有唯一一份 TSS,它的作用也仅仅是在权限级做跃迁的时候保存堆栈上下文,可以通过图1-11理解进程切换机制。
注意
关于 x86 架构 CPU 的任务切换机制,可以参考阅读《Intel 开发手册》,可以从 Intel 官网下载。另外,本人也编写了代码来模拟两个进程切换的过程,供大家参考,便于加深理解:https://github.com/lingqi1818/analysis_linux/tree/master/ch01/test03 关于 asm 内嵌汇编语法可以参考:https://www.ibm.com/developerworks/cn/linux/sdk/assemble/inline/index.html

图1-11 进程切换原理图
1.3.3 调度中的 CPU 亲和度
我们已经知道,进程创建出来后在内核中的数据结构为 task_struct,该结构中有掩码属性 cpus_allowed,这个掩码由 n 位组成,与 CPU 中的每个逻辑核心一一对应。具有4个核的 CPU 可以有4位。假如 CPU 启用了超线程,那么刚才这个 CPU 就有一个8位的掩码,进程可以运行在掩码位设置为1的 CPU 上。
Linux 内核 API 提供了两个系统调用,让用户可以修改位掩码或查看当前的位掩码:
sched_setaffinity():用来修改位掩码。
sched_getaffinity():用来查看当前的位掩码。
这两个调用实现的仅仅就是修改或者获取 cpus_allowed 的值。
在下次 task 被唤醒的时候,select_task_rq_fair 根据 cpu_allowed 里的掩码来确定将其置于哪个 CPU 的运行队列,一个进程在某一时刻只能存在于一个 CPU 的运行队列里。
在 Nginx 中,就使用了 CPU 亲和度来完成某些场景的工作:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
上面这个配置说明了4个工作进程中的每一个和一个 CPU 核挂钩。
worker_processes 2;
worker_cpu_affinity 0101 1010;
上面这个配置则说明了两个工作进程中的每一个和2个核挂钩。
看 Nginx 的实现,核心函数为 ngx_setaffinity:
void
ngx_setaffinity(uint64_t cpu_affinity, ngx_log_t *log)
{
cpu_set_t mask;
ngx_uint_t i;
…
CPU_ZERO(&mask);
i = 0;
do {
if (cpu_affinity & 1) {
CPU_SET(i, &mask);
}
i++;
cpu_affinity >>= 1;
} while (cpu_affinity);
if (sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1) {
ngx_log_error(NGX_LOG_ALERT, log, ngx_errno,
"sched_setaffinity() failed");
}
}
这里主要的操作就是 sched_setaffinity。
再结合 Nginx 文档中的例子和 Nginx 的源码来看:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
如果这个内容写入 Nginx 的配置文件中,然后 Nginx 启动或者重新加载配置的时候,若 worker_process 是4,就会启用4个 worker,然后把 worker_cpu_affinity 后面的4个值当作4个 cpu affinity mask,分别调用 ngx_setaffinity,然后就把4个 worker 进程分别绑定到 CPU 0~3上。
1.4 在应用程序中管理进程和线程
在了解了 Linux 对进程和线程的实现之后,我们首要的目的还是要学习如何在实际应用程序开发中使用这些技术,不同的应用程序实现了不同的进程或线程的管理模型,而每一种模型的背后,都体现了作者对业务的理解和场景化的考虑。下面我们介绍两种不同软件的管理模型。
1.4.1 Memcached 线程池模型分析
Memcached 是一款服务器内存管理软件,它主要是由 pthread 创建的用户工作线程池模型来处理主要逻辑的,图1-12是 Memcached 的线程模型图。
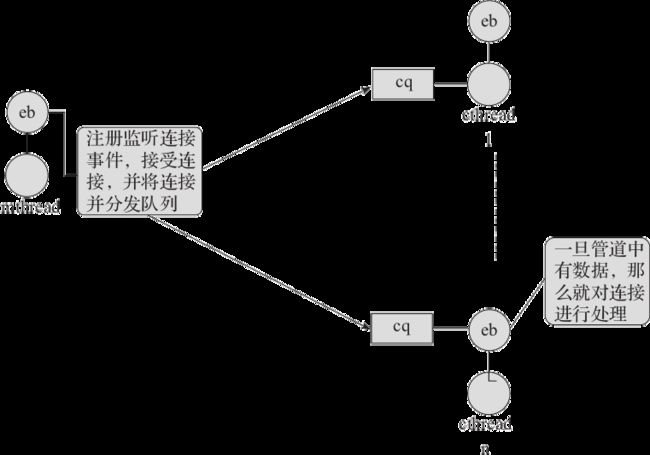
图1-12 Memcached 线程模型图
其主要概念如下:
mthread 主线程,主要用于监听 socket 事件,并建立连接,然后把连接和相应的事件分发到 cq 连接队列中(每个分线程都拥有一个连接队列)。
cthread 分线程,用于从连接队列中获取连接的读写事件,并进行业务逻辑的处理工作。
从 Memcached 的线程池初始化逻辑中我们可以发现,cthread 是个线程池,用户可以指定池子的大小:
void thread_init(int nthreads, struct event_base *main_base) {
int i;
int power;
pthread_mutex_init(&cache_lock, NULL);
pthread_mutex_init(&stats_lock, NULL);
pthread_mutex_init(&init_lock, NULL);
pthread_cond_init(&init_cond, NULL);
pthread_mutex_init(&cqi_freelist_lock, NULL);
cqi_freelist = NULL;
…
dispatcher_thread.base = main_base;
dispatcher_thread.thread_id = pthread_self();
…
// 在设置完 libevent 后,创建线程
for (i = 0; i < nthreads; i++) {
create_worker(worker_libevent, &threads[i]);
}
// 等待,直到所有线程设置完毕并返回
pthread_mutex_lock(&init_lock);
wait_for_thread_registration(nthreads);
pthread_mutex_unlock(&init_lock);
}
Memcached 在创建工作线程的时候,同样会用 pipe 调用创建管道,用于和主线程之间的通信。
create_worker 函数最终通过 pthread_create 来创建工作线程:
static void create_worker(void *(*func)(void *), void *arg) {
pthread_t thread;
pthread_attr_t attr;
int ret;
pthread_attr_init(&attr);
if ((ret = pthread_create(&thread, &attr, func, arg)) != 0) {
fprintf(stderr, "Can't create thread: %s\n",
strerror(ret));
exit(1);
}
}
该模型假设在业务逻辑繁忙,并且 I/O 开销比较大的情况下,多线程模型能提高系统的吞吐率。但缺点是当多线程同时访问同一数据的时候就存在竞争,需要额外的并发解决开销(比如锁)。另外其实 Memcached 大部分操作都是基于内存的读写,应该速度很快,引入并发反而在竞争中存在效率降低的风险,另外假如系统中线程数量开得太多,那么线程切换的开销也会上升,需要根据实际场景谨慎设置线程池的大小。而 Redis 的作者认为内存的操作速度是很快的,所以实现了单线程的服务器模型,在下一章介绍并发的时候再详细介绍。
1.4.2 Nginx 进程模型分析
刚才介绍的 Memcached 是比较经典的服务器线程池模型,比如老牌静态服务器软件 Apache 就是采用这样的模型,而 Nginx 的作者则对该模型进行了改进。
Nginx 只要创建 CPU 核心数量相等的工作进程,即可满足高并发、高吞吐量的需求,原因是它的每个工作进程都持有一个基于 I/O 多路复用的 epoll 池子(见图1-13),这样每个进程只有在事件被触发的场景下才进行工作,否则就会让出 CPU 进行其他事件的处理,特别是在 upstream 的场景下,工作进程可以悠闲地等待后端数据准备好之后再进行工作,CPU 的利用率也大大提升。
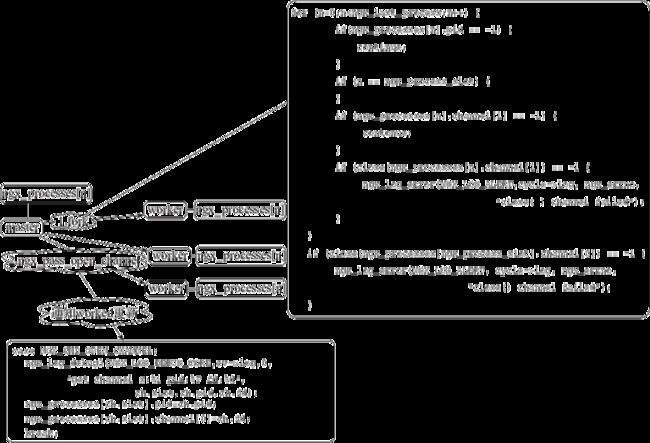
图1-13 Nginx 工作进程模型
在 Nginx 中 master 进程通过 fork 调用派生完子进程后,又通过 socketpair 创建了管道来进行父子进程之间的通信。
通过了解 Memcached 和 Nginx 的线程池和工作进程模型,我们发现有多种选择,既多线程与单线程,线程池模型与工作进程模型,选择哪种模型好?答案不是绝对的,需要根据业务场景具体分析后,找到问题的症结在哪里,才能给出具体的答案。
1.5 处理进程和线程的相关工具
在了解了 Linux 进程和线程的实现后,在具体的开发和运维场景下如何驾驭它们呢?下面我们简单介绍几个工具,在 Linux 下可用于调试、追踪系统调用并进行性能分析。
1.5.1 开发环境调试线程
当使用 gdb 调试 C 程序的时候,比如 Nginx、Nginx 的子进程都是 fork 出来的,所以当开发完并定义模块设置断点调试的时候,默认是无法进入断点的,gdb 提供了调试线程的方法。
跟踪子进程:
(gdb)set follow-fork-mode child
跟踪父进程:
(gdb)set follow-fork-mode parent
设置 gdb 在 fork 时询问跟踪哪一个进程:
(gdb)set follow-fork-mode ask
根据以上方法进行设置之后,我们就可以在相应的线程实现处设置断点并进行跟踪了。
1.5.2 进程崩溃调试方法
在 C 程序崩溃的时候往往会留下 coredump 文件,供我们分析问题到底出在哪里。下面我们用一个 Nginx 崩溃的场景来分析如何调试 coredump 文件。
曾经遇到个问题,因为后端领取奖品的接口存在并发操作,有可能会出现超领的情况,但是在分析请求日志的过程中发现,在 Tomcat 中,出现了2条领取记录,并且已经成功,但是,在 Nginx 中却只有一条记录。感觉很奇怪,困扰了很久。
不过在分析 Nginx 的 error.log 的时候,发现了一些蛛丝马迹:
[alert] 92648#0: worker process 22459 exited on signal 11
原来在被多领取的时候,还发生过 Nginx 的 woker 进程退出的情况。signal 11也就是 SIGSEGV 信号,说明有非法内存访问的情况。
那么,为什么会有这样的问题呢?难道编写的 Nginx 模块中有潜在的 bug?于是在 Nginx 配置中,设置打开 coredump 的功能:
worker_rlimit_core 500m;
working_directory /tmp;
然后,用 gdb 来调试产生的 coredump 文件:
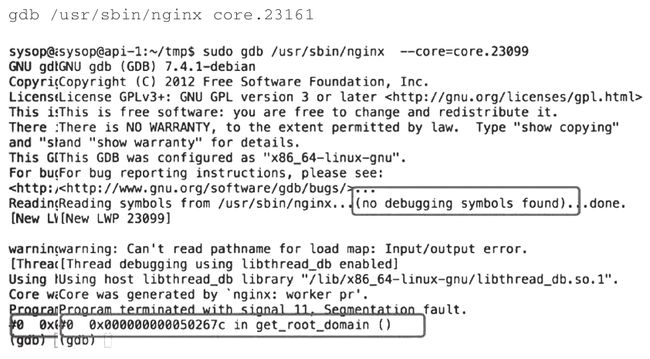
发现问题出在 get_root_domain 函数,但是由于 Nginx 没有 debug 信息,无法获取具体文件和行号,查看 Nginx 官方文档,编译的时候产生 debug 调试信息可以如下操作:“编译器需要使用正确的参数。假如你使用的是 GCC,-g 参数,会在代码编译后加入调试信息,另外,你需要禁用编译器优化,通过使用 -O0 参数,可以让调试器输出容易看懂的信息。”
我们可以重新编译 Nginx:
CFLAGS="-g -O0" ./configure ....
然后,重新执行:
gdb /usr/sbin/nginx core.23161
显示如下:
sysop@api-1:~$ gdb /usr/sbin/nginx core.23176
GNU gdb (GDB) 7.4.1-debian
Copyright (C) 2012 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.? Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
For bug reporting instructions, please see:
) at src/http/modules/ngx_http_beacon_
module.c:298
get_root_domain 代码如下:
size_t get_root_domain(u_char **p,ngx_str_t *domain){
*p = domain->data;
int i = domain->len - 1;
ngx_flag_t is_first = 0;
...
我们发现 domain 指针指向的是0x8这个地址,这么低的地址理论上应该是系统保护的地址,不能被程序访问,那么 domain 是如何来的呢?
domain_len = get_root_domain(&domain,&r->headers_in.host->value);
返现直接取的是 HTTP 协议头中的 host 信息。
然后再看了一下当时的错误信息,有一些获取验证码的请求是用 httpclient 构建的,不是通过浏览器发起的请求,那么 host 信息必然是空的。所以导致这个空指针的异常。
而在当时 Nginx 的进程退出,正好影响了正常的请求,导致返回的时候没打印日志以及吐数据给客户就挂了。
最后程序对这种情况做了兼容,修复了这个诡异的问题。
1.5.3 strace 工具
strace 是 Linux 提供的一个工具,常用来跟踪进程执行时的系统调用和所接收的信号。比如:
[root@lingqi1818 ~]# strace cat /dev/null
execve("/bin/cat", ["cat", "/dev/null"], [/* 27 vars */]) = 0
brk(0) = 0x250d000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) =
0x7f1e0c0bf000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=26432, ...}) = 0
mmap(NULL, 26432, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f1e0c0b8000
close(3) = 0
open("/lib64/libc.so.6", O_RDONLY) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0000\356\1\0\0\0\0\0"...
, 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1921216, ...}) = 0
mmap(NULL, 3750152, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) =
0x7f1e0bb0d000
mprotect(0x7f1e0bc98000, 2093056, PROT_NONE) = 0
mmap(0x7f1e0be97000, 20480, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_
DENYWRITE, 3, 0x18a000) = 0x7f1e0be97000
mmap(0x7f1e0be9c000, 18696, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_
ANONYMOUS, -1, 0) = 0x7f1e0be9c000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) =
0x7f1e0c0b7000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) =
0x7f1e0c0b6000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) =
0x7f1e0c0b5000
arch_prctl(ARCH_SET_FS, 0x7f1e0c0b6700) = 0
mprotect(0x7f1e0be97000, 16384, PROT_READ) = 0
mprotect(0x7f1e0c0c0000, 4096, PROT_READ) = 0
munmap(0x7f1e0c0b8000, 26432) = 0
brk(0) = 0x250d000
brk(0x252e000) = 0x252e000
open("/usr/lib/locale/locale-archive", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=99158720, ...}) = 0
mmap(NULL, 99158720, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f1e05c7c000
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 0), ...}) = 0
open("/dev/null", O_RDONLY) = 3
fstat(3, {st_mode=S_IFCHR|0666, st_rdev=makedev(1, 3), ...}) = 0
read(3, "", 32768) = 0
close(3) = 0
close(1) = 0
close(2) = 0
exit_group(0) = ?
以上代码每一行都是一个系统调用,等号左边是系统调用的函数名及其参数,右边是该调用的返回值。
strace 的具体参数含义可以通过 man 指令来查询,比如我们常用的 -c 参数可以统计每一次系统调用所执行的时间、次数和出错的次数等:
[root@lingqi1818 ~]# strace -c cat /dev/null
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 2 read
0.00 0.000000 0 4 open
0.00 0.000000 0 6 close
0.00 0.000000 0 5 fstat
0.00 0.000000 0 9 mmap
0.00 0.000000 0 3 mprotect
0.00 0.000000 0 1 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 1 1 access
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 36 1 total
1.5.4 SystemTap 工具
SystemTap 是基于 kprobe 的实现(关于 kprobe 网上资料较多,大家可以自行研究),其功能非常强大,可以监控内核和用户程序。
下面以实际场景为例,来监控运行中程序指定函数的调用参数值。
#include
#include
#include
#include
void print(char *p){
printf("%s.\n",p);
}
void* test_fn(void* arg)
{
while(1){
print("hello pthread");
sleep(5); }
return((void *)0);
}
int main(int argc,char **argv)
{
pthread_t id;
int ret;
ret = pthread_create(&id,NULL,test_fn,NULL);
if(ret != 0)
{
printf("create pthread error!\n");
exit(1);
}
printf("in main process.\n");
pthread_join(id,NULL);
return 0;
}
以上程序每5秒钟会调用一次 print,我要是想知道 print 的输入参数是什么,那么编写 SystemTap 脚本如下:
function myprint:string (val)
%{
char *str = (char *)STAP_ARG_val;
snprintf(STAP_RETVALUE, MAXSTRINGLEN, "%s",str);
%}
probe process(3266).function("print") {printf("%s\n",myprint($p));}
运行结果为:
stap –g test.stp
这样就可以获得监控的结果了,因为我用到了内嵌 C 来获取字符串的值,所以就需要加上-g参数。
1.5.5 DTrace 工具
DTrace 是 Oracle 旗下的一款基于 Linux 的监控程序,它可以基于 D 语言编写脚本来实现你想要的监控功能,由于功能比较复杂,这里不做过多阐述,大家可以有兴趣到下面的网址了解更多信息:
http://www.oracle.com/technetwork/cn/articles/servers-storage-admin/dtrace-on-linux-1956556-zhs.html
http://docs.oracle.com/cd/E24847_01/html/E22192/toc.html.
下面的脚本用于监控指定 pid 下指定的系统调用是否发生:
test.d:
pid$1::$2:entry
{
self->trace = 1;
}
pid$1::$2:return
/self->trace/
{
self->trace = 0;
}
pid$1:::entry,
pid$1:::return
/self->trace/
{
}
然后我们打开 Redis 进程:
localhost:src chenke$ ./redis-server
其 pid 为:
chenke 7276 0.0 0.0 2465080 1892 s003 S+ 12:32下午 0:00.01 ./redis-
server *:6379
现在进行写入操作:
localhost:~ chenke$ telnet localhost 6379
Trying ::1...
Connected to localhost.
Escape character is '^]'.
set a 1
+OK
我们来看监控脚本产生的数据如下:
dtrace: script 'test.d' matched 33829 probes
CPU ID FUNCTION:NAME
0 257241 write:entry
0 257241 write:entry
0 257241 write:entry
0 257241 write:entry
0 257241 write:entry
0 257241 write:entry
当然,更复杂的功能需要自己研究手册和 D 语言,而且 DTrace 的好处是可以监控用户态的程序。
1.6 本章小结
进程和线程是计算机发展历史上为解决特定问题而产生的解决方案。本章开头介绍了进程管理的历史,以及实现原理,特别是内核线程、用户线程和协程,只有了解了这些原理,才能更好地编写应用程序。
随后介绍了 Linux 对进程和线程的实现,还介绍了内核对进程和线程的调度机制,调度机制的好坏决定了一个操作系统是否能流畅响应不同用户的实时请求。
我们平时使用了很多开源的软件,进程和线程的模型是服务器实现必须要考虑的问题,在了解了原理以及 Linux 的实现后,再对 Memcached 和 Nginx 相关模型进行分析,有助于更好地理解进程和线程。
最后,通过对 gdb、coredump、strace、SystemTap、DTrace 等工具的介绍,有助于我们进行开发调试、故障诊断、监控分析等,建议大家可以多动手实践。