I/O多路复用以及Reactor 和 Proactor
本文内容为小林codig图解系统系列的知识点梳理,详细内容请移步原文
IO复用:https://blog.csdn.net/qq_34827674/article/details/115619261
Reactor 和 Proactor:https://blog.csdn.net/qq_34827674/article/details/116175772
之前讨论过五种网络io模型,但是对于多路复用IO并没有做过多的描述,所以此文着重梳理总结多路复用IO的相关知识点。
从简单的Socket说起
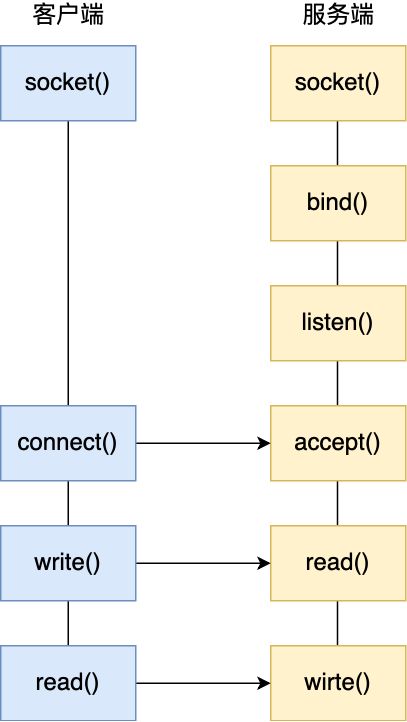
进行网络通信的两端都需要调用socket函数,通过传入不同的参数,可以确定网络层使用的是IPv4/IPv6,传输层使用的是TCP/UDP,socket创建成功后,服务端需要给socket绑定ip号和端口号,函数bind()可以完成这一过程,之所以要绑定ip和端口,因为一台机器是可以有多个网卡的,每个网卡都有对应的 IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发给我们,内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到我们的应用程序,然后把数据传递给我们。之后服务端开始等待客户端的连接请求,通过listen()函数进行监听,服务端进入了监听状态后,通过调用accept()函数,来从内核获取客户端的连接,如果没有客户端连接,则会阻塞等待客户端连接的到来。客户端的连接请求是通过connect()函数实现的,这个函数中将客户端的socket绑定了ip和端口号。而后开始进行TCP的三次握手,已经完成三次握手建立连接的会加入到服务器内核所维护的TCP全连接队列,三次握手尚未完成的放在TCP半连接队列。
当 TCP 全连接队列不为空后,服务端的accept()函数,就会从内核中的 TCP 全连接队列里拿出一个已经完成连接的 Socket 返回应用程序,后续数据传输都用这个 Socket。连接建立后,客户端和服务端就开始相互传输数据了,双方都可以通过read()和write()函数来读写数据。
为何需要多路复用IO
上述模型是一个客户端对应一个服务器,如果现实中使用这种模型对服务器浪费太大,如何将服务器尽可能多的与客户端建立连接
多进程/多线程模型
我们将一个进程用于对客户端的监听,如果客户端连接完成,accept()就会返回一个已连接的socket,这时fork()一个子进程,由于子进程可以继承父进程的资源,所以可以使用socket和客户端通信,在这个模型中,父进程负责监听socket,子进程负责处理已连接的socket。
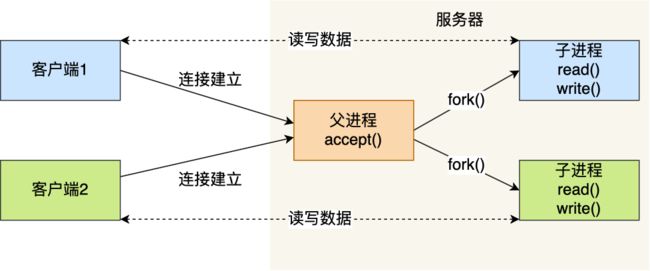
此模型需要注意,当子进程销毁的时候需要收回其所占用的资源。这种方法在客户端较多的时候回频繁的进行上下文切换,性能不高。
线程在切换的时候,耗时比进程小,所以可以使用线程来代替上述的进程,这就是多线程模型,不同的是,可以使用线程池来避免线程的频繁创建销毁,线程池,就是提前创建若干个线程,这样当由新连接建立时,将这个已连接的 Socket 放入到一个队列里,然后线程池里的线程负责从队列中取出已连接 Socket 进程处理。
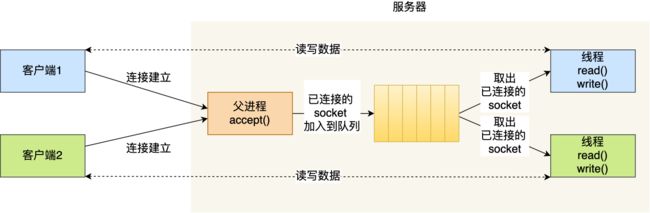
需要注意的是,这个队列是全局的,每个线程都会操作,为了避免多线程竞争,线程在操作这个队列前要加锁。
虽然上述方法可以解决一个服务器对应多个客户端的问题,但是当处理客户端数量很大的场景时,同时维护对应数量的进程/线程,操作系统难以驾驭。
I/O多路复用
I/O多路复用的模型如下:
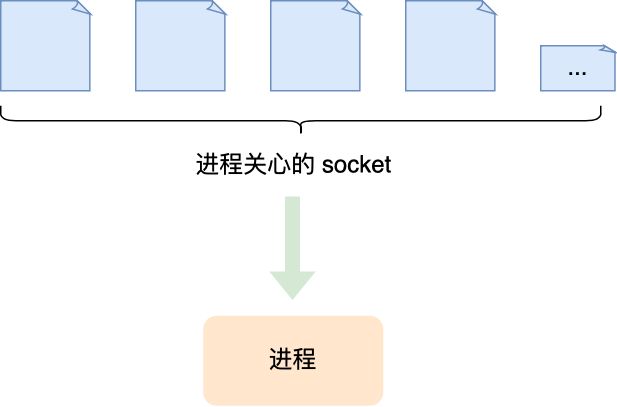
select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll
select是把已连接的socket放到文件描述符集合里,然后select函数会把集合拷贝到内核,如果有网络事件发生,通过遍历文件描述符集合找到对应的socket,并将其标记为读/写,之后再把集合拷贝回用户态,用户态再次遍历集合,找到之前内核标记好的socket进行处理,这种方法会将文件描述符集合进行两次内核和用户之间的拷贝,也要经过两个遍历查找,所以比较慢,而且内核中对文件描述符的大小也有限制。poll使用动态数组存储文件描述符,这样突破了select对于文件描述符数量的限制
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll
epoll使用红黑树来存储文件描述符,对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。此外,epoll使用事件驱动的机制,维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
epoll里的常用的函数由三个,epoll_create(),epoll_ctl(),epoll_wait(),他们的作用如下图:
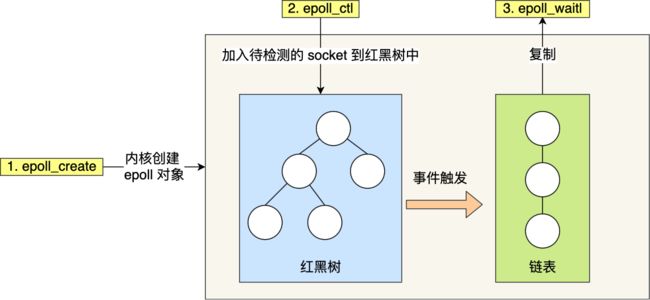
epoll支持两种触发方式,ET(边沿触发)和LT(水平触发)
ET:当被监控的 Socket 描述符上有可读事件发生时,进程会读取一次数据,即使没读完也不会继续读取了
LT:当被监控的 Socket 上有可读事件发生时,进程不断读取,知道读完才结束
水平触发的意思是只要满足事件的条件,比如内核中有数据需要读,就一直不断地把这个事件传递给用户;而边缘触发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。
边缘触发的效率比水平触发的效率要高,因为边缘触发可以减少 epoll_wait 的系统调用次数,系统调用也是有一定的开销的的,毕竟也存在上下文的切换。如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。因此,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
Reactor
Reactor模式使用多路复用进行事件监听,收到事件后根据事件类型分配给对应的线程和进程,它由以下两个部分组成:
- Reactor :负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池:负责处理事件,如 read -> 业务逻辑 -> send;
Reactor可以有一个或者多个,处理资源池可以是单线程/进程或者多线程/进程,这样组合起来包含四种Reactor模型,但是由于多Reactor单进程方案不仅复杂且性能也没有优势,所以实际使用中并没有优势,所以常用的方案有以下三种:
- 单 Reactor 单进程 / 线程;
- 单 Reactor 多线程 / 进程;
- 多 Reactor 多进程 / 线程;
单 Reactor 单进程 / 线程

可以看到进程里有 Reactor、Acceptor、Handler 这三个对象:
- Reactor 对象的作用是监听和分发事件;
- Acceptor 对象的作用是获取连接;
- Handler 对象的作用是处理业务;
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,如果收到的事件是建立连接,交给Accepter处理,他会调用accept建立连接,并且传建一个Handle对象处理后续的响应事件,如果不是连接事件则交给Hander处理
这是方案有两个缺点,首先单进程,无法利用多核cpu的性能,其次Handle在处理业务的时候,进程无法处理其他的连接事件。
单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
单 Reactor 多线程 / 进程
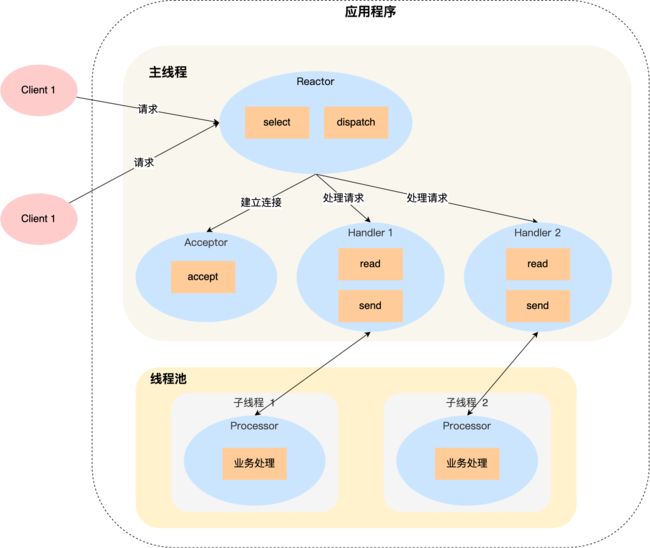
单Reactor单线程的缺点主要来自于单线程,上图描述了单Reactor多线程的处理过程,在单Reactor单线程的基础上,将Handler的工作进一步拆分为Handler负责数据的收发,而将业务处理交给子线程里的Processer,处理之后将结构返回Handler对象,通过send发送给客户端。
这种模式下需要注意多线程竞争共享资源的情况。
多 Reactor 多进程 / 线程
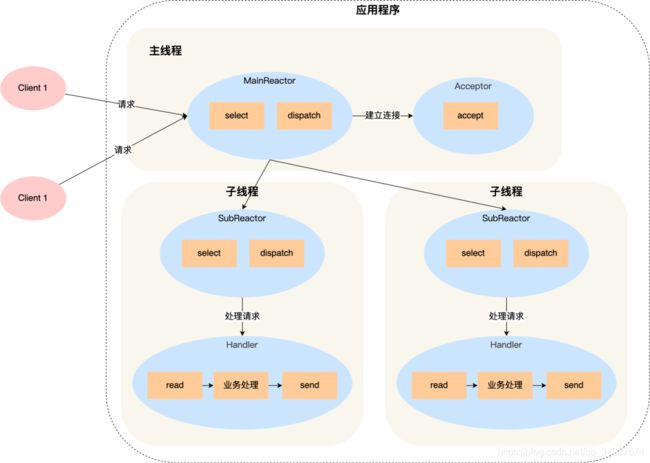
- 主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
- 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
- 如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
Proactor
Reactor 是非阻塞同步网络模式,而 Proactor 是异步网络模式。
当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
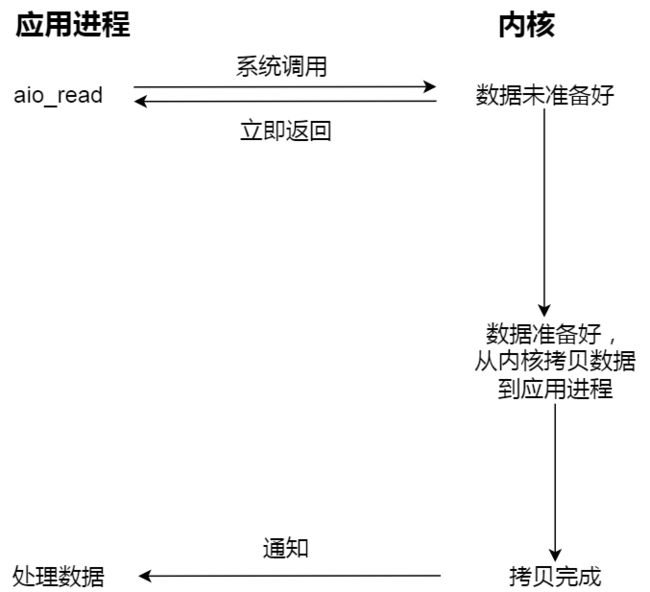
Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
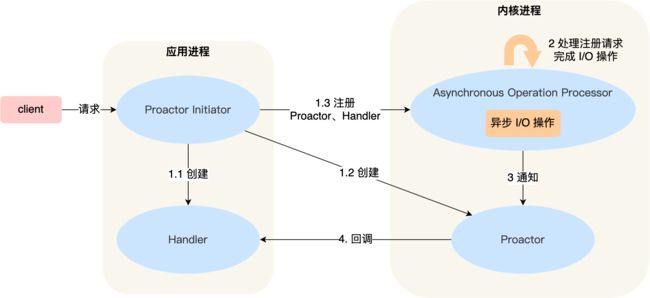
- Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过Asynchronous Operation Processor 注册到内核;
- Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
- Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
- Handler 完成业务处理;